

ChatGPT gibi bir üretken yapay zeka (AI) programının istemine bir komut (bilgi istemi) yazdığınızda, program size yalnızca yazdıklarınıza göre değil, aynı zamanda daha önce yazdıklarınıza göre de bir yanıt verir.
Bu nedenle konuşmaların tarihini bir anı olarak değerlendirebiliriz. Ancak, üretken yapay zekayı daha iyi organize edilmiş belleğe daha yakın bir şeyle donatmaya çalışan birçok kurumdaki araştırmacılara göre bu yeterli değil.
California Üniversitesi ve Microsoft işbirlikçileri tarafından bu ay yayınlanan “Augmenting Language Models with Long-Term Memory” (Uzun Süreli Bellekle Dil Modellerini Artırma) başlıklı bir makale ve arXiv’de yayınlandıdil modellerine etkili bir şekilde yeni bir bileşen ekler.
UC Santa Barbara, Microsoft
Bilgi istemi uzunluk sınırı sorunu
İlk sorun, ChatGPT ve benzeri araçların yalnızca sınırlı uzunluktaki istemleri kabul edebilmesidir. Ve bu, “uzun bilgi parçalarını işleme yeteneğinin gerekli olduğu gerçek dünya senaryolarına genelleme yapmalarını engelliyor.”
Örneğin, OpenAI’nin GPT-3’ü maksimum 2.000 belirteç, yani karakter veya kelime girdisini kabul eder. Programa örneğin 5.000 kelimelik bir makale veya 70.000 kelimelik bir roman sağlayamazsınız.
Giriş “penceresini” genişletmeye devam etmek mümkündür. Ancak bu, dikenli bir bilgisayar sorunuyla karşı karşıya gelir. “Dikkat işlemi” – yani ChatGPT ve GPT-4 dahil olmak üzere tüm ana dil programlarının temel aracı – “ikinci dereceden” bir hesaplama karmaşıklığına sahiptir (bkz. “zaman karmaşıklığıBu karmaşıklık, ChatGPT’nin yanıt üretme süresinin, girdi olarak aldığı veri miktarının karesi kadar artması anlamına gelir.
Bellek senkronizasyonu
Bu nedenle bazı araştırmacılar şimdiden ilkel bir bellek geliştirmeye çalıştılar. Google tanıtıldı Geçen sene Gelecekte yararlanabileceği önceki yanıtların bir kopyasını saklayan Ezberleyen Dönüştürücü. Bu işlem, bir seferde 65.000 jeton üzerinde çalışmasına izin verir.
Ancak Google, bu verilerin hızla güncelliğini yitirebileceğini belirtiyor. Ezberleme Dönüştürücüsünün eğitim süreci, nöral ağırlıkları veya parametreleri güncellendikçe, nöral ağ ile belleğin belirli öğelerinin senkronizasyonunu bozar.
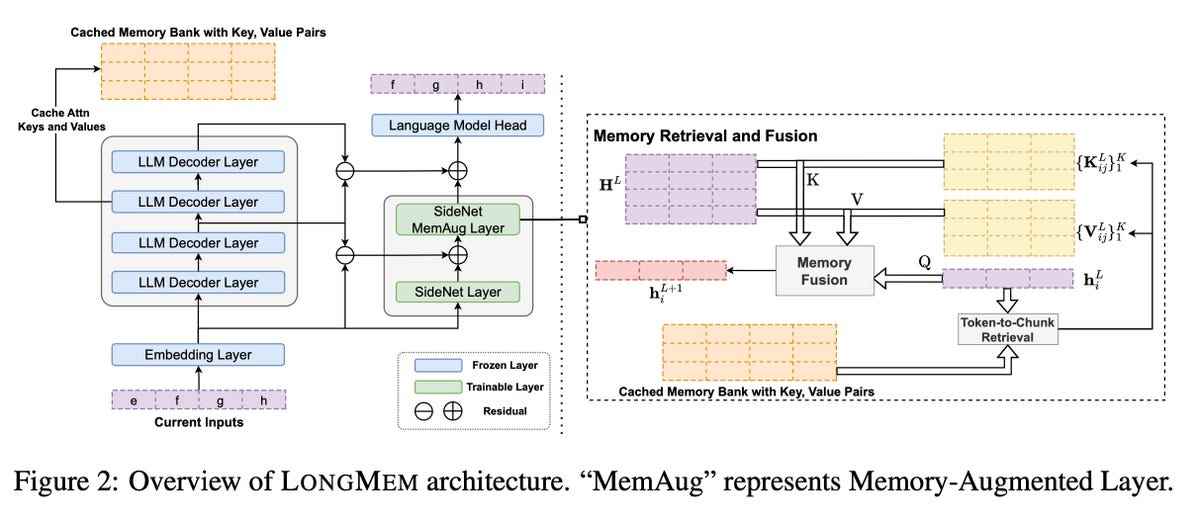
Microsoft’un “Uzun Süreli Bellekle Artırılmış Dil Modelleri” veya LongMem adlı çözümü, iki şey yapan büyük bir geleneksel dil modeli kullanıyor. Verileri incelerken bir kısmını hafıza bankasında saklar. Ayrıca, her istemin çıktısını SideNet adı verilen ikinci bir sinir ağına iletir.
Sindirim Projesi Gutenberg, arXiv Dosya Sunucusu ve ChapterBreak
Aynı zamanda bir dil modeli olan SideNet, ilgili bir eşleşme olup olmadığını görmek için bir kişi tarafından yazılan komut istemini belleğin içeriğiyle karşılaştırmaktan sorumludur. SideNet, Memory Transformer’dan farklı olarak, ana dil modelinden bağımsız olarak kendi başına eğitilebilir. Bu sayede hafızanın güncelliğini yitirmemiş içeriklerinin belirlenmesinde giderek daha verimli hale gelmektedir.
Microsoft, LongMem’i Memorizing Transformer ve OpenAI’nin GPT-2 dil modeliyle karşılaştırmak için testler yapıyor. Ayrıca LongMem’i 175 milyar parametrede GPT-3 modeli dahil olmak üzere diğer dil modellerinden elde edilen sonuçlarla karşılaştırırlar.
Bunu yapmak için Microsoft, tüm makaleler ve kılavuzlar dahil olmak üzere çok uzun metinleri özetlemeyi içeren üç veri kümesine dayalı görevler kullanır: Project Gutenberg, arXiv dosya sunucusu ve ChapterBreak.
Yazma tekniğinin merkezinde
Size bu görevlerin büyüklüğü hakkında bir fikir vermesi için ChapterBreak, geçen yıl sunuldu Massachusetts Amherst Üniversitesi’nden Simeng Sun ve meslektaşları tarafından yazılan bu kitap, tüm kitapları alır ve bir bölümden birkaç pasajdan hangisinin bir sonraki bölümün başlangıcını işaret ettiğini doğru bir şekilde belirleyip belirlemediğini görmek için bir dil modelini test eder.
Böyle bir görev, olayların yeri ve zamanındaki değişiklikler gibi “uzun vadeli bağımlılıkların kapsamlı bir şekilde anlaşılmasını” ve “analepsi” gibi teknikler gerektirir; .
Ve bu, onlarca hatta yüzbinlerce öğenin işlenmesini içerir.
Herhangi bir LLM’nin çok uzun bilgi dizilerini depolamasına izin veren bir program
Araştırmacılar bu testleri ChapterBreak ile çalıştırdıklarında, geçen yıl baskın dil modellerinin zorlandığını bildirdiler. Örneğin, GPT-3 zamanın yalnızca %28’inde haklıydı. Ancak LongMem programı, LongMem’in 175 milyar GPT-3’ten az olmasına rağmen yalnızca yaklaşık 600 milyon nöral parametreye sahip olmasına rağmen, GPT-3 dahil tüm standart dil modellerini %40,5’lik bir puanla “şaşırtıcı bir şekilde” yendi.
Microsoft, “Bu veri kümelerindeki önemli iyileştirmeler, LONGMEM’in dil modellemeyi gelecekteki girdilere doğru güzel bir şekilde tamamlamak için önbelleğe alınmış geçmiş bağlamı anlayabildiğini gösteriyor” diye yazıyor.
Ve Microsoft’un çalışması, sosyal medya uygulaması TikTok’un ana şirketi ByteDance tarafından yapılan son araştırmayı yansıtıyor.
bir makalede Nisan ayında arXiv’de yayınlandıByteDance araştırmacısı Xinnian Liang ve meslektaşları, “Kendinden Kontrollü Bellek Sistemine Sahip Büyük Ölçekli Dil Modelleri için Sonsuz Uzunlukta Girdi Kapasitesini Serbest Bırakma” başlıklı, herhangi bir LLM’nin çok uzun bilgi dizilerini depolamasına izin veren bir program geliştirdiler.
TikTok’un tescilli ByteDance’ın “kendi kendini kontrol eden bellek sistemi”, geçmiş olaylarla ilgili soruları yanıtlamak için ChatGPT’nin ötesinde herhangi bir dil modeli yeteneği sağlamak için yüzlerce diyalog ve binlerce karakterden oluşan bir veritabanından yararlanabilir. ByteDance
İstem zamanında çağrılan bir “bellek akışı”
Uygulamada, programın bir programın her yeni istemi bağlama yerleştirme yeteneğini önemli ölçüde artırabileceğini ve dolayısıyla yanıt olarak uygun ifadeler oluşturabileceğini iddia ediyorlar – ChatGPT’den bile daha iyi.
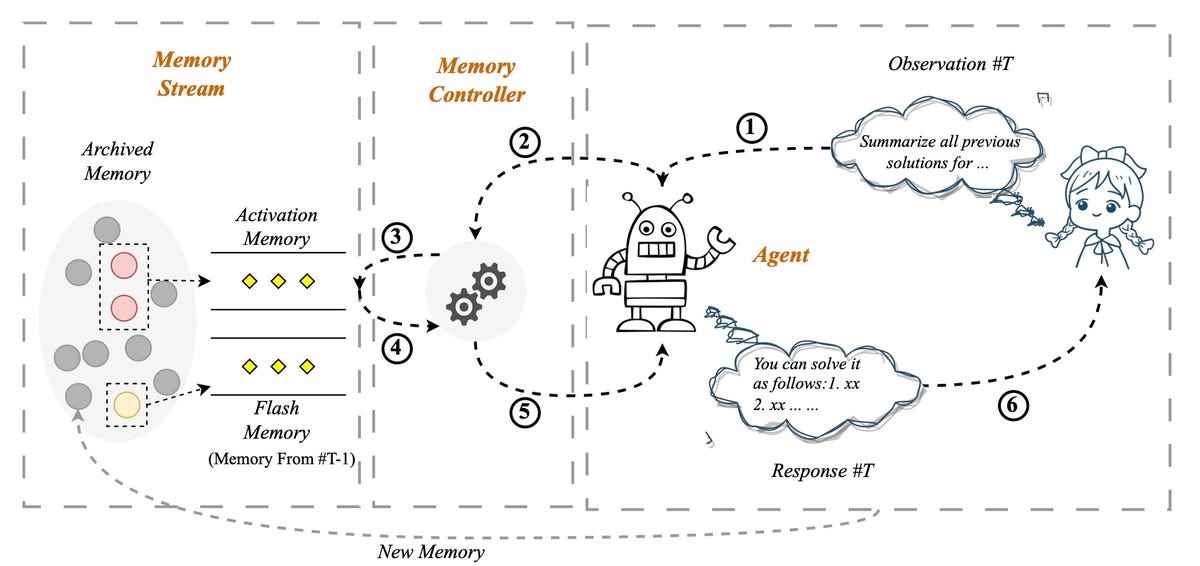
“Kendi kendini kontrol eden hafıza sistemi” veya SCM (Kendinden Kontrollü Hafıza sistemi) olarak adlandırılan sistemde, kullanıcı tarafından bilgi isteminde girilen veriler, bir hafıza denetleyicisi tarafından bir hafıza denetleyicisi tarafından değerlendirilerek, bir hafızaya girmenin gerekli olup olmadığı belirlenir. kullanıcı ve program arasındaki tüm geçmiş etkileşimleri içeren bir “bellek akışı” adı verilen arşiv bellek sistemi. Biraz Microsoft’un SideNet’i ve onunla birlikte gelen bellek bankası gibi.
Bellek gerekiyorsa, geçmiş girişlerin bu koleksiyonuna bir Pinecone gibi vektör veritabanı aracı. Kullanıcı girişi, alaka düzeyi veritabanındakilerle karşılaştırılan bir sorgudur.
Microsoft ve TikTok’un çalışması, dil modellerinin orijinal amacının bir uzantısıdır
Bazı kullanıcı sorguları bellek gerektirmez. Herhangi bir dil modelinin işleyebileceği rasgele bir istek olan “Bana bir şaka anlat” isteminde durum budur. Buna karşılık, “Geçen hafta fitness diyetleri hakkında vardığımız sonucu hatırlıyor musunuz?” geçmiş tartışma kağıtlarına erişim gerektiren türden bir sorudur.

ByteDance
Bunu yapmak için, kullanıcının istemi ve önceki konuşmalardan kurtarılan belleği, makalenin “girdi birleştirme” dediği şeyde birleştirilir. Ve yanıtını ürettiği dil modelinin gerçek girdisi haline gelen bu birleştirilmiş metindir.
Nihai sonuç, Liang ve ekibine göre, SCM’nin yüzlerce diyalog dönüşüne atıfta bulunmayı içeren görevlerde ChatGPT’den daha iyi performans gösterebilmesidir. SCM’lerini GPT-3’ün bir versiyonuna bağladılar. metin-davinci-003ve performansını ChatGPT’ye karşı aynı girdiyle test etti.
ByteDance
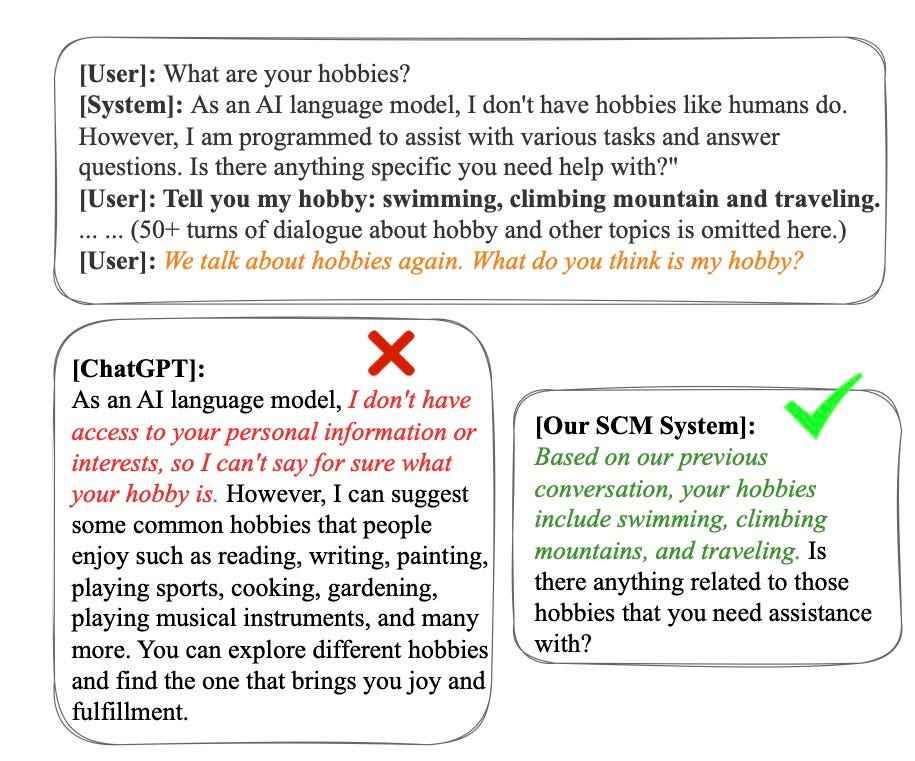
4.000 jeton içeren 100’den fazla turdan oluşan bir seride, adam makineden oturumun başında tartışılan kişinin hobilerini hatırlamasını istediğinde, “SCM sistemi sorguya kesin bir yanıt vererek olağanüstü bellek yetenekleri sergiliyor. ” diye yazarken, “buna karşın, görünüşe göre ChatGPT önemli miktarda alakasız tarihsel veriyle dikkati dağıtmış.”
İş aynı zamanda raporlar gibi binlerce kelimelik uzun metinleri de özetleyebilir. Bunu, metni yinelemeli olarak özetleyerek, yani ilk özeti bellek akışında depolayarak, ardından bir sonraki özeti önceki özet ile birlikte oluşturarak vb. yaparak yapar.
SCM, sohbet robotu olmayan büyük dil modellerinin de sohbet robotu gibi davranmasını sağlayabilir. “Deneysel sonuçlar, SCM sistemimizin çok turlu diyalog için optimize edilmemiş LLM’lerin ChatGPT ile karşılaştırılabilir çok turlu diyalog yetenekleri elde etmesini sağladığını gösteriyor” diye yazıyorlar.
Microsoft ve TikTok’un çalışmaları, dil modellerinin orijinal amacının bir uzantısı olarak görülebilir. ChatGPT ve öncülü Google’ın Transformer’ından önce, doğal dil görevleri genellikle yinelenen sinir ağları (RNN’ler) olarak bilinen ağlar tarafından gerçekleştiriliyordu. Tekrarlayan bir sinir ağı, mevcut girdiyle karşılaştırmak için geçmiş girdi verilerine geri dönebilen bir algoritma türüdür.
LLM belleği için hangi kullanım durumları?
Transformer ve ChatGPT gibi LLM’ler, RNN’leri daha basit bir yaklaşımla değiştirdi: dikkat. Dikkat, yazılanları otomatik olarak daha önce yazılanlarla karşılaştırır, böylece geçmiş her zaman dikkate alınır.
Bu nedenle Microsoft ve TikTok araştırması, geçmişin unsurlarını daha organize bir şekilde hatırlamak için açıkça tasarlanmış algoritmalarla dikkati genişletiyor.
Belleğin eklenmesi o kadar basit bir ince ayardır ki, gelecekte LLM’lerin standart bir yönü haline gelmesi muhtemeldir, bu da programların sohbet geçmişi gibi geçmiş öğelerle bağlantı kurabilmesini veya yaklaşabilmesini çok daha yaygın hale getirir. çok uzun eserlerin tüm metni.