
İki çalışmaya göre, ChatGPT gibi üretken yapay zeka (genAI) araçlarının oluşturulduğu algoritmik platformlar olan büyük dil modelleri (LLM’ler), kurumsal veritabanlarına bağlandığında oldukça hatalı oluyor ve daha az şeffaf hale geliyor.
Stanford Üniversitesi’nin bir araştırması LLM’lerin büyük miktarlarda bilgi almaya ve boyutları büyümeye devam ettikçe, kullandıkları verilerin oluşumunun izini sürmenin zorlaştığını gösterdi. Bu da işletmelerin ticari genAI temel modellerini kullanan uygulamaları güvenli bir şekilde oluşturup oluşturamayacaklarını bilmelerini ve akademisyenlerin araştırma için bunlara güvenmelerini zorlaştırıyor.
Stanford çalışmasına göre bu aynı zamanda yasa koyucuların güçlü teknolojiyi dizginlemek için anlamlı politikalar tasarlamasını ve “tüketicilerin model sınırlamalarını anlamalarını veya neden olunan zararlar için tazminat aramalarını” zorlaştırıyor.
GPT, LLaMA ve DALL-E gibi LLM’ler (temel modeller olarak da bilinir) geçtiğimiz yıl ortaya çıktı ve yapay zekayı (AI) dönüştürerek onlarla deney yapan şirketlerin çoğuna üretkenlik ve verimlilik artışı sağladı. Ancak bu faydalar ağır bir belirsizlik yığınını da beraberinde getiriyor.
Stanford Temel Modelleri Araştırma Merkezi toplum lideri Rishi Bommasani, “Şeffaflık, kamuya hesap verme sorumluluğu, bilimsel yenilik ve dijital teknolojilerin etkili yönetimi için temel bir önkoşuldur” dedi. “Şeffaflık eksikliği, dijital teknolojilerin tüketicileri için uzun zamandır bir sorun olmuştur.”
 Stanford Üniversitesi
Stanford ÜniversitesiÖrneğin yanıltıcı çevrimiçi reklamlar ve fiyatlandırma, araç paylaşımındaki belirsiz ücret uygulamaları, kullanıcıları bilmeden satın alma konusunda kandıran karanlık modeller ve içerik denetimiyle ilgili sayısız şeffaflık sorunu, sosyal medyada geniş bir yanlış ve dezenformasyon ekosistemi yarattı, Bommasani kayıt edilmiş.
“Ticari konularda şeffaflık olarak [foundation models] azaldıkça tüketicinin korunmasına yönelik benzer türde tehditlerle karşı karşıya kalıyoruz” dedi.
Stanford araştırmacıları, örneğin, adında “açık” kelimesi bulunan OpenAI’nin, amiral gemisi modeli GPT-4’ün çoğu yönü hakkında şeffaf olmayacağını açıkça belirttiğini belirtti.
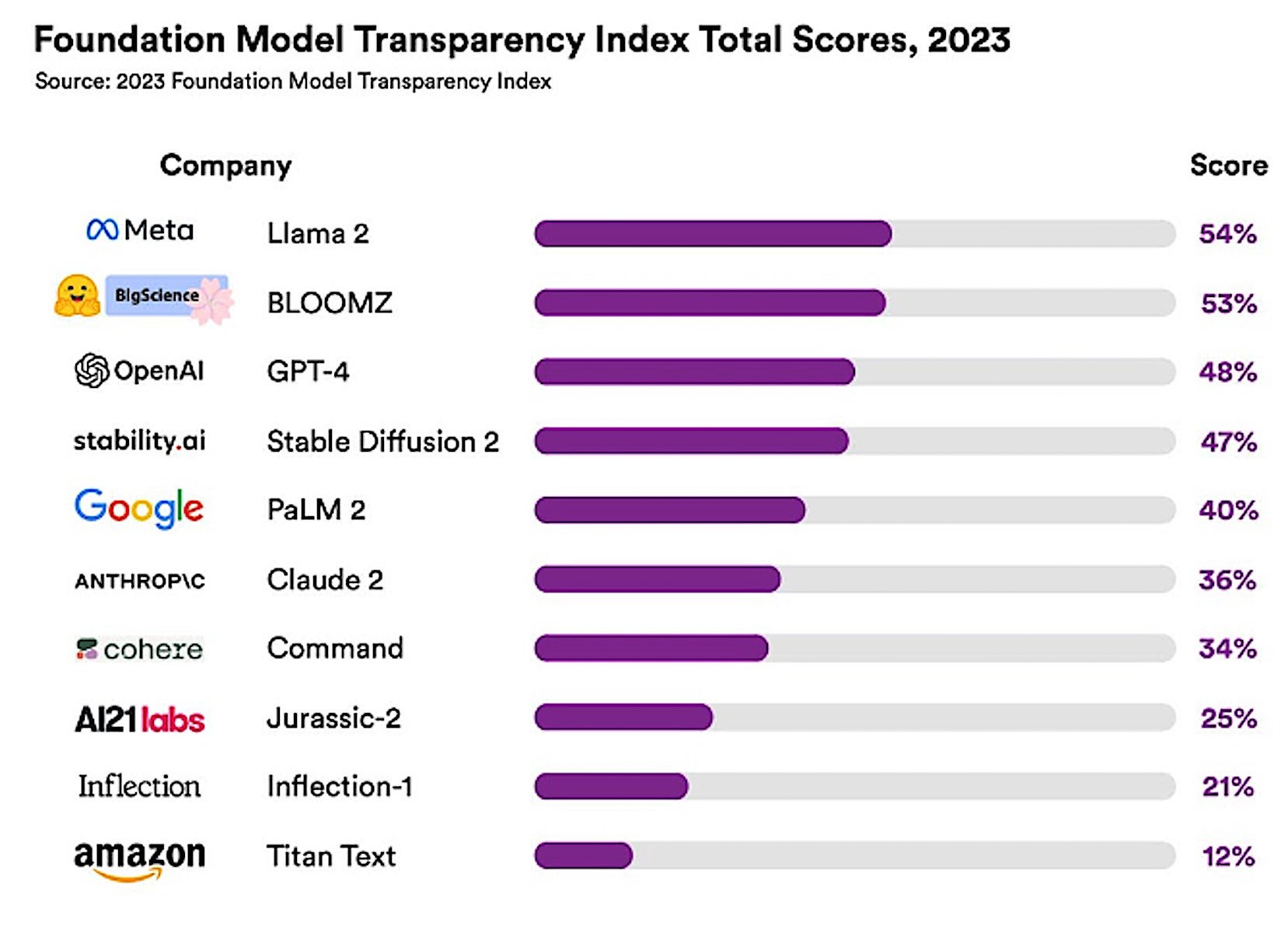
Şeffaflığı değerlendirmek amacıyla Stanford, MIT ve Princeton’dan araştırmacıların da dahil olduğu bir ekibi bir araya getirerek, “Şeffaflık” adı verilen bir puanlama sistemi tasarladı. Temel Mmodel Transpdurum İçindebeceri (FMTI). Bir şirketin temel modelini nasıl oluşturduğu, nasıl çalıştığı ve bunun alt kademelerde nasıl kullanıldığı da dahil olmak üzere şeffaflığın 100 farklı yönünü veya göstergesini değerlendirir.
Stanford çalışması 10 LLM’yi değerlendirdi ve ortalama şeffaflık puanının sadece %37 olduğunu buldu. LLaMA %52’lik şeffaflık oranıyla en yüksek puanı aldı; bunu sırasıyla %48 ve %47 puanla GPT-4 ve PaLM 2 izledi.
Bommasani, “Şeffaflığınız yoksa düzenleyiciler bırakın bu alanlarda harekete geçmeyi, doğru soruları bile soramaz” dedi.
Bu arada, siber güvenlik ve antivirüs sağlayıcısı Kaspersky Lab tarafından yapılan ayrı bir ankete göre neredeyse tüm üst düzey patronlar (%95) genAI araçlarının çalışanlar tarafından düzenli olarak kullanıldığına inanıyor ve yarıdan fazlası (%53) artık belirli iş departmanlarını yönlendirdiğini söylüyor. Bu çalışma, yöneticilerin yüzde 59’unun, hassas şirket bilgilerini tehlikeye atabilecek ve temel iş fonksiyonlarının kontrolünün kaybedilmesine yol açabilecek genAI ile ilgili güvenlik riskleri hakkında derin endişelerini dile getirdiğini ortaya çıkardı.
Kaspersky’nin baş güvenlik araştırmacısı David Emm, “BYOD’ye benzer şekilde genAI, işletmelere büyük üretkenlik avantajları sunuyor, ancak bulgularımız yönetim kurulu yöneticilerinin kuruluşlarındaki varlığını açıkça kabul ettiğini ortaya koysa da, kullanım kapsamı ve amacı gizemini koruyor” dedi. , bir açıklamada söyledi.
Yüksek Lisans’larla ilgili sorun şeffaflığın ötesinde daha derinlere uzanıyor; Modellerin genel doğruluğu neredeyse OpenAI’nin ChatGPT’yi bir yıl önce piyasaya sürdüğü andan itibaren sorgulanmaya başlandı.
Juan Sequeda, AI Laboratuvarı başkanı veri.dünyaVeri kataloglama platformu sağlayıcısı olan , şirketinin SQL veritabanlarına bağlı LLM’leri test ettiğini ve şirkete özel sorulara yanıt sağlamakla görevlendirildiğini söyledi. Gerçek dünya sigorta şirketi verilerini kullanarak, data.world’ün araştırması LLM’lerin çoğu temel iş sorgusuna yalnızca %22 oranında doğru yanıtlar döndürdüğünü gösterdi. Orta ve uzman düzeyindeki sorgularda doğruluk %0’a düştü.
Kurumsal ayarlara göre uyarlanmış uygun metinden SQL’e karşılaştırma ölçütlerinin bulunmaması, Yüksek Lisans’ların kullanıcı sorularına veya “istemlerine” doğru şekilde yanıt verme yeteneğini etkiliyor olabilir.
Sequeda, “LLM’lerin doğruluğun anahtarı olan dahili iş bağlamından yoksun olduğu anlaşıldı” dedi. “Çalışmamız, yüksek lisans eğitimlerinin özellikle kuruluştaki yapılandırılmış verilerin ana kaynağı olan SQL veritabanlarıyla kullanılması konusunda bir boşluk olduğunu gösteriyor. Bu boşluğun diğer veritabanları için de mevcut olduğunu varsayıyorum.”
Sequeda, şirketlerin bulut veri ambarlarına, iş zekasına, görselleştirme araçlarına ve ETL ve ELT sistemlerine milyonlarca dolar yatırım yaparak verilerden daha iyi yararlanabileceklerini belirtti. Bu verilerle ilgili sorular sormak için Yüksek Lisans’ları kullanabilmek, temel performans göstergeleri, ölçümler ve stratejik planlama gibi süreçlerin iyileştirilmesi veya daha fazla değer yaratmak için derin alan uzmanlığından yararlanan tamamen yeni uygulamalar yaratılması için büyük olasılıkların önünü açar.
Çalışma öncelikle GPT-4 kullanarak soru yanıtlamaya odaklandı. sıfır atış istemleri doğrudan SQL veritabanlarında. Doğruluk oranı? Sadece %16.
Kurumsal veritabanlarına dayalı hatalı yanıtların net etkisi güvenin erozyona uğramasıdır. “Eğer kurula doğru olmayan rakamlarla sunum yapıyorsanız ne olur? Yoksa SEC mi? Her durumda maliyet yüksek olacaktır” dedi Sequeda.
LLM’lerle ilgili sorun, bunların daha önce gelen kelimelere dayanarak bir sonraki kelimeyi tahmin eden istatistiksel ve kalıp eşleştirme makineleri olmalarıdır. Tahminleri, açık webin tüm içeriğindeki kalıpların gözlemlenmesine dayanıyor. Açık web aslında çok büyük bir veri kümesi olduğundan, Sequeda’ya göre LLM çok makul görünen ancak aynı zamanda hatalı da olabilecek şeyleri döndürecektir.
“Sonraki bir neden de modellerin yalnızca gördükleri kalıplara dayanarak tahminlerde bulunmasıdır. Kuruluşunuza özgü kalıpları görmezlerse ne olur? Yanlışlık artıyor” dedi.
Sequeda şöyle devam etti: “Eğer işletmeler doğruluk konusunu ele almadan LLM’leri önemli bir ölçekte uygulamaya çalışırsa, girişimler başarısız olacaktır.” “Kullanıcılar çok geçmeden Yüksek Lisans’lara güvenemeyeceklerini anlayacak ve onları kullanmayı bırakacaklar. Yıllar boyunca veri ve analitikte de benzer bir model gördük.”
Sorular, kurumsal SQL veritabanının Bilgi Grafiği temsili üzerinden sorulduğunda Yüksek Lisans’ın doğruluğu %54’e yükseldi. Sequeda, “Bu nedenle Bilgi Grafiği’ne yatırım yapmak, Yüksek Lisans destekli soru cevaplama sistemleri için daha yüksek doğruluk sağlıyor” dedi. “Bunun neden olduğu hala belli değil çünkü Yüksek Lisans’ta neler olup bittiğini bilmiyoruz.
Sequeda şöyle devam etti: “Bildiğimiz şey şu ki, eğer bir Yüksek Lisans’a, kritik iş bağlamını içeren bir bilgi grafiği içinde eşlenen ontolojiyi içeren bir bilgi istemi verirseniz, doğruluk, bunu yapmamanıza göre üç kat daha fazladır,” diye devam etti Sequeda. “Ancak kendimize ‘yeterince doğru’nun ne anlama geldiğini sormamız önemli?”
Yüksek Lisans’lardan doğru yanıt alma olasılığını artırmak için şirketlerin “güçlü bir veri temeline” veya Sequeda ve diğerlerinin yapay zekaya hazır veriler dediği şeye sahip olması gerekir; bu, yanıtların doğruluğunu artırmak ve açıklanabilirliği sağlamak için verilerin bir Bilgi Grafiğinde eşlendiği anlamına gelir, “bu, LLM’nin çalışmasını gösterebileceğiniz anlamına gelir.”
Model doğruluğunu artırmanın başka bir yolu da küçük dil modellerini (SLM’ler) ve hatta sektöre özgü dil modellerini (ILM’ler) kullanmak olabilir. Sequeda, “Her işletmenin, her biri belirli soru cevaplama türleri için ayarlanmış belirli sayıda yüksek lisans eğitiminden yararlandığı bir gelecek görebiliyorum” dedi.
“Yine de yaklaşım aynı olmaya devam ediyor: bir sonraki kelimeyi tahmin etmek. Bu tahmin yüksek olabilir ancak tahminin yanlış olma ihtimali her zaman olacaktır.”
Sequeda, hassas ve özel bilgilerin öngörülemeyen modeller tarafından riske atılmasını önlemek için her şirketin gözetim ve yönetimi sağlaması gerektiğini söyledi.
Telif Hakkı © 2023 IDG Communications, Inc.