
Artık hemen hemen her endüstri ve şirkette kilit bir teknoloji olan makine öğrenimi ve yapay zeka alanındaki araştırmalar, herkesin hepsini okuması için çok hacimlidir. Perceptron adlı bu sütun, özellikle yapay zeka konusunda, ancak bununla sınırlı olmamak üzere, en güncel keşiflerden ve makalelerden bazılarını toplamayı ve neden önemli olduklarını açıklamayı amaçlıyor.
Bu son araştırma grubunda, Meta, 200 farklı dili “son teknoloji” sonuçlarla çevirebilen ilk dil olduğunu iddia ettiği bir dil sistemini açık kaynaklı hale getirdi. Google, geride kalmamak için bir makine öğrenimi modeli detaylandırdı, Minervamatematiksel ve bilimsel sorular da dahil olmak üzere nicel muhakeme problemlerini çözebilir. Ve Microsoft bir dil modeli yayınladı, Gödel, Google’ın geniş çapta duyurulan Lamda’sına uygun “gerçekçi” konuşmalar oluşturmak için. Ve sonra, bir bükülme ile bazı yeni metinden görüntüye oluşturucularımız var.
Meta’nın yeni modeli NLLB-200, şirketin dünya dillerinin çoğu için makine destekli çeviri yetenekleri geliştirmeye yönelik No Language Left Behind girişiminin bir parçasıdır. Kamba (Bantu etnik grubu tarafından konuşulan) ve Lao (Laos’un resmi dili) gibi dillerin yanı sıra daha önceki çeviri sistemleri tarafından iyi veya hiç desteklenmeyen 540’tan fazla Afrika dilini anlamak için eğitilmiş NLLB-200, Meta, kısa süre önce Wikimedia Foundation’ın İçerik Çeviri Aracı’na ek olarak Facebook Haber Kaynağı ve Instagram’daki dilleri çevireceğini duyurdu.
AI çevirisi, büyük ölçüde ölçeklenme potansiyeline sahiptir – ve şimdiden sahip olmak ölçeklenmiş– insan uzmanlığı olmadan çevrilebilecek dillerin sayısı. Ancak bazı araştırmacıların belirttiği gibi, yanlış terminoloji, eksiklikler ve yanlış çevirilerden kaynaklanan hatalar, yapay zeka tarafından oluşturulan çevirilerde ortaya çıkabilir, çünkü sistemler büyük ölçüde internetten gelen verilerle eğitilir – hepsi yüksek kaliteli değildir. Örneğin, Google Translate bir zamanlar doktorların erkek, hemşirelerin kadın olduğunu varsayarken, Bing’in tercümanı “masa yumuşaktır” gibi ifadeleri Almanca’da dişil “die Tabelle” olarak tercüme etti (bir şekil tablosunu ifade eder).
NLLB-200 için Meta, veri temizleme hattını “ana filtreleme adımları” ve 200 dilin tamamı için zehirlilik filtreleme listeleri ile “tamamen elden geçirdiğini” söyledi. Pratikte ne kadar iyi çalıştığını görmek için kalır, ancak – NLLB-200’ün arkasındaki Meta araştırmacılarının yöntemlerini açıklayan bir akademik makalede kabul ettiği gibi – hiçbir sistem tamamen önyargısız değildir.
Benzer şekilde Gödel, web’den çok miktarda metin üzerinde eğitilmiş bir dil modelidir. Ancak, NLLB-200’den farklı olarak Gödel, “açık” diyalogları, yani bir dizi farklı konu hakkındaki konuşmaları ele almak üzere tasarlandı.
Resim Kredisi: Microsoft
Gödel, bir restoranla ilgili bir soruyu yanıtlayabilir veya bir mahallenin tarihi veya yakın tarihli bir spor maçı gibi belirli bir konu hakkında ileri geri diyalog kurabilir. Yararlı bir şekilde ve Google’ın Lamda’sı gibi, sistem, restoran incelemeleri, Wikipedia makaleleri ve genel web sitelerindeki diğer içerikler dahil olmak üzere, eğitim veri setinin bir parçası olmayan web’deki içerikten yararlanabilir.
Ancak Gödel, NLLB-200 ile aynı tuzaklarla karşılaşır. Bir makalede, onu oluşturmaktan sorumlu ekip, onu eğitmek için kullanılan verilerdeki “sosyal önyargı ve diğer toksisite biçimleri” nedeniyle “zararlı tepkiler üretebileceğini” belirtiyor. Bu önyargıları ortadan kaldırmak, hatta azaltmak, AI alanında çözülmemiş bir zorluk olmaya devam ediyor – asla tamamen çözülemeyecek bir zorluk.
Google’ın Minerva modeli potansiyel olarak daha az sorunludur. Arkasındaki ekibin bir blog yazısında açıkladığı gibi, sistem, hesap makinesi gibi harici araçlar kullanmadan nicel muhakeme problemlerini çözmek için 118 GB’lık bilimsel makalelerden ve matematiksel ifadeler içeren web sayfalarından oluşan bir veri setinden öğrendi. Minerva, popüler STEM kıyaslamalarında lider performans elde eden sayısal hesaplamalar ve “sembolik manipülasyon” içeren çözümler üretebilir.
Minerva, bu tür sorunları çözmek için geliştirilen ilk model değil. Birkaç isim vermek gerekirse, Alphabet’in DeepMind, matematikçilere karmaşık ve soyut görevlerde yardımcı olabilecek çoklu algoritmalar gösterdi ve OpenAI, denenmiş ilkokul düzeyinde matematik problemlerini çözmek için eğitilmiş bir sistemle. Ancak ekip, Minerva’nın matematiksel soruları daha iyi çözmek için en son teknikleri içerdiğini ve yeni bir soru sunmadan önce mevcut sorulara birkaç adım adım çözümlerle modeli “istemeyi” içeren bir yaklaşım da dahil olduğunu söylüyor.

Resim Kredisi: Google
Minerva yine de hatalardan payını alıyor ve bazen doğru bir son cevaba ancak hatalı bir mantıkla varıyor. Yine de ekip, bunun “bilim ve eğitimin sınırlarını zorlamaya yardımcı olan” modeller için bir temel teşkil edeceğini umuyor.
Yapay zeka sistemlerinin gerçekte neyi “bildiği” sorusu teknik olmaktan çok felsefidir, ancak bu bilgiyi nasıl organize ettikleri adil ve ilgili bir sorudur. Örneğin, bir nesne tanıma sistemi, kavramların onları nasıl tanımladığı konusunda bilerek örtüşmesine izin vererek ev kedileri ve kaplanların bazı yönlerden benzer olduklarını “anladığını” gösterebilir – ya da belki de gerçekten anlamaz ve iki tür yaratıklar onunla tamamen ilgisizdir.
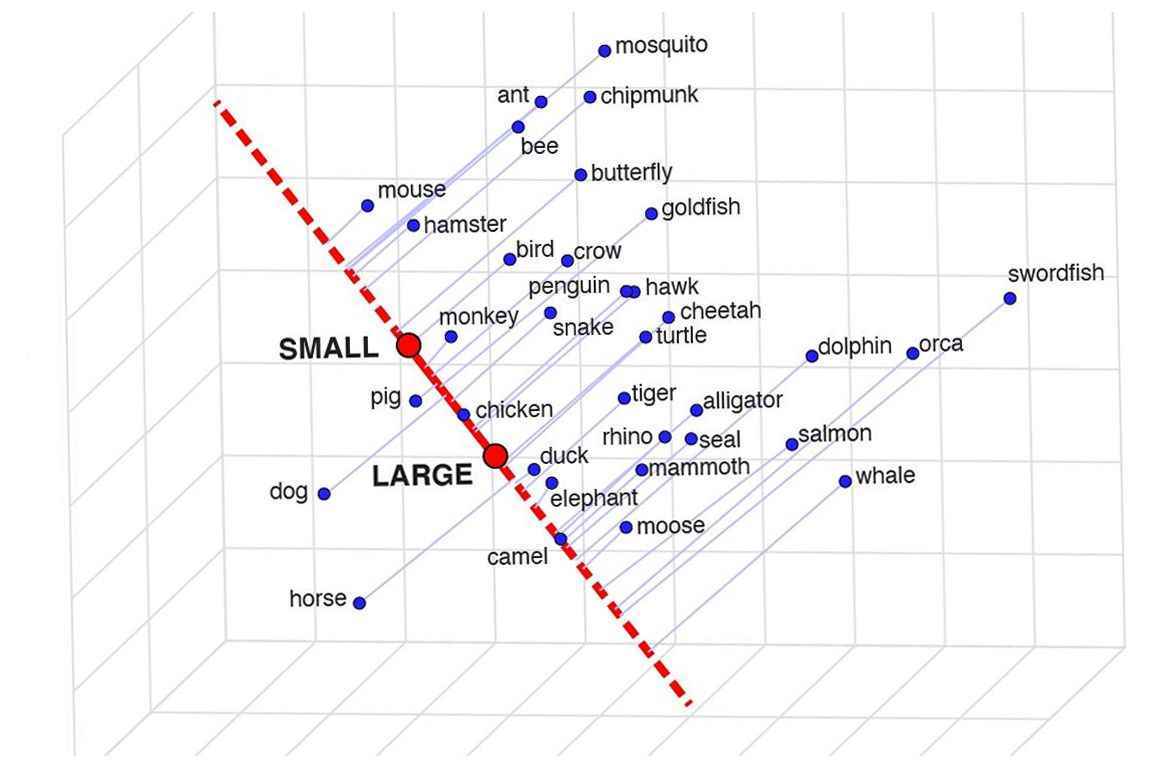
UCLA’daki araştırmacılar, dil modellerinin kelimeleri bu anlamda “anladıklarını” görmek istediler ve evet, yaptıklarını öne süren “anlamsal izdüşüm” adlı bir yöntem geliştirdi.. Modelden bir balinanın bir balıktan nasıl ve neden farklı olduğunu açıklamasını isteyemezseniz de, bu kelimeleri diğer kelimelerle ne kadar yakından ilişkilendirdiğini görebilirsiniz. memeli, büyük, terazi, ve benzeri. Balina, memeli ve iri ile yüksek oranda ilişki kuruyorsa ancak pullarla değil, neden bahsettiği hakkında iyi bir fikre sahip olduğunu biliyorsunuz.
Hayvanların model tarafından kavramsallaştırıldığı gibi küçükten büyüğe spektruma düştüğü bir örnek.
Basit bir örnek olarak, hayvanın büyüklük, cinsiyet, tehlike ve ıslaklık kavramlarıyla örtüştüğünü (seçim biraz garipti), devletlerin ise hava durumu, zenginlik ve partizanlıkla örtüştüğünü buldular. Hayvanlar partizan değildir ve devletler cinsiyetsizdir, bu yüzden tüm izler.
Şu anda bir modelin bazı kelimeleri çizmesini istemekten daha iyi anlayıp anlamadığı konusunda daha kesin bir test yok – ve metinden görüntüye modeller daha iyi olmaya devam ediyor. Google’ın “Pathways Autoregressive Text-to-Image” veya Parti modeli, şimdiye kadarki en iyilerinden biri gibi görünüyor, ancak bu modeli erişim olmadan rekabetle (DALL-E ve diğerleri) karşılaştırmak zor, bu da modellerden birkaçının sunduğu bir şey. . Her halükarda burada Parti yaklaşımı hakkında bilgi edinebilirsiniz.
Google yazısının ilginç bir yönü, modelin artan sayıda parametreyle nasıl çalıştığını gösteriyor. Rakamlar arttıkça görüntünün kademeli olarak nasıl geliştiğini görün:

Komut istemi, “Sydney Opera Binası’nın önündeki çimenlerin üzerinde, göğsünde Hoş Geldiniz Arkadaşlar yazan bir tabela tutan turuncu kapüşonlu ve mavi güneş gözlüklü bir kangurunun portre fotoğrafı!” idi.
Bu, en iyi modellerin hepsinin on milyarlarca parametreye sahip olacağı anlamına mı geliyor, yani sadece süper bilgisayarlarda eğitilmeleri ve çalıştırılmaları uzun zaman alacak mı? Şimdilik, elbette – bu, bir şeyleri iyileştirmeye yönelik bir tür kaba kuvvet yaklaşımı, ancak AI’nın “tik-tak”ı, bir sonraki adımın onu daha büyük ve daha iyi yapmak değil, daha küçük ve eşdeğer hale getirmek olduğu anlamına geliyor. Bunu kim başaracak göreceğiz.
Eğlencenin dışında bırakılacak biri olmayan Meta, bu hafta yaratıcı bir AI modeli de sergiledi, ancak bunu kullanan sanatçılara daha fazla ajans sağladığını iddia ediyor. Kendim bu jeneratörlerle çok oynadıktan sonra, eğlencenin bir kısmı ne olduğunu görmektir, ancak çoğu zaman saçma sapan düzenler buluyorlar veya istemi “anlamıyorlar”. Meta’nın Make-A-Scene bunu düzeltmeyi amaçlıyor.
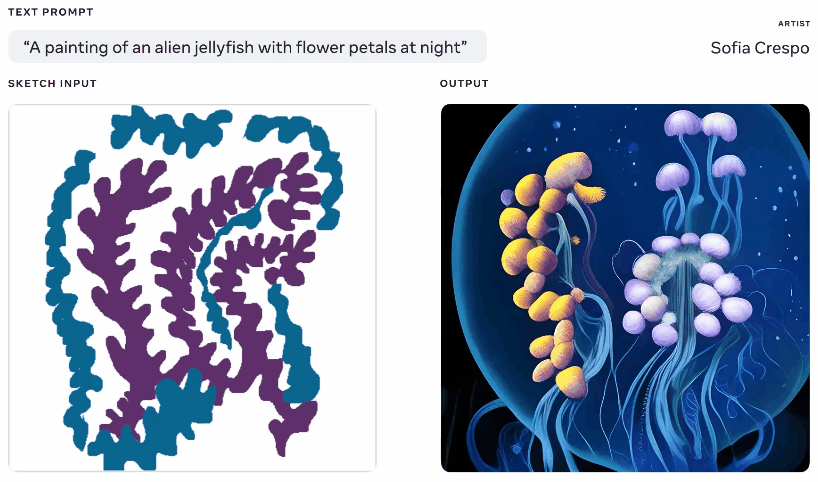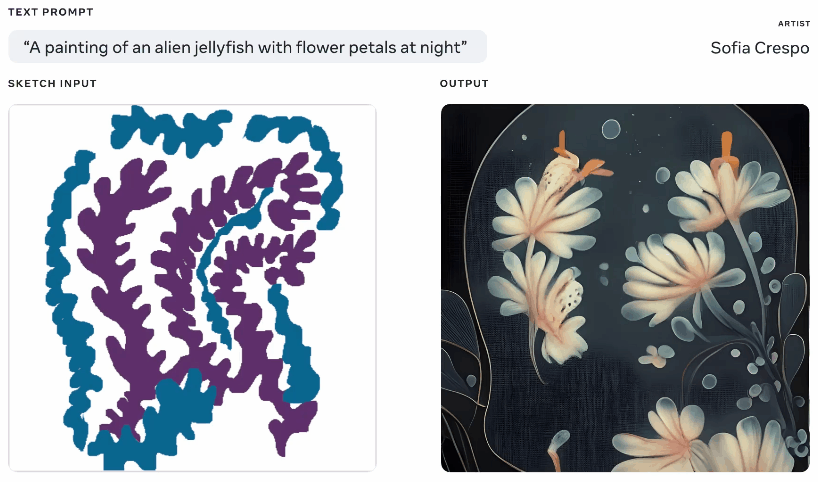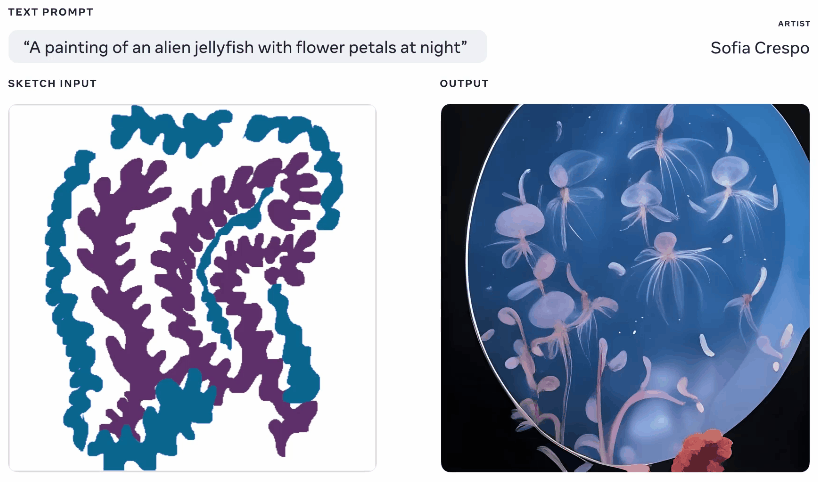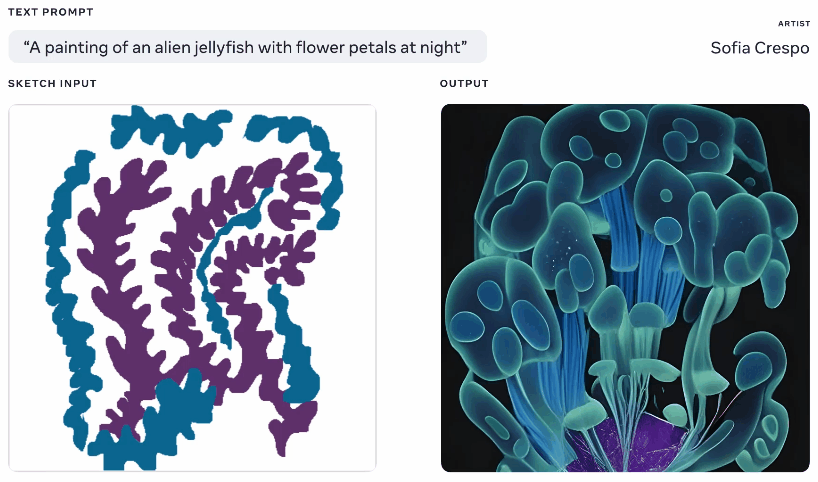
Aynı metin ve eskiz isteminden oluşturulan farklı görüntülerin animasyonu.
Bu pek orijinal bir fikir değil – bahsettiğiniz şeyin temel bir siluetini çiziyorsunuz ve bunu üstüne bir görüntü oluşturmak için bir temel olarak kullanıyor. Google’ın kabus üreteci ile 2020’de böyle bir şey gördük. Bu benzer bir kavramdır, ancak çizimi temel alarak, ancak yorumlama için çok fazla alana sahip olan metin istemlerinden gerçekçi görüntüler oluşturmasına izin verecek şekilde büyütülmüştür. Ne düşündükleri hakkında genel bir fikre sahip olan ancak modelin sınırsız ve tuhaf yaratıcılığını dahil etmek isteyen sanatçılar için faydalı olabilir.
Bu sistemlerin çoğu gibi, Make-A-Scene de, diğerleri gibi, oldukça açgözlü hesaplama açısından oldukça açgözlü olduğundan, genel kullanıma açık değildir. Endişelenme, yakında bu şeylerin düzgün versiyonlarını evde alacağız.