Önde gelen AI araştırmacısı François Chollet tarafından kurulan kâr amacı gütmeyen bir kuruluş olan Arc Ödülü Vakfı Blog yazısı Salı günü, önde gelen AI modellerinin genel zekasını ölçmek için yeni ve zorlu bir test oluşturdu.
Şimdiye kadar, ARC-AGI-2 adı verilen yeni test çoğu modeli zorladı.
Openai’nin O1-Pro ve Deepseek’in R1 skoru Arc-AGI-2’de% 1 ila% 1.3 arasında “akıl yürütme” modelleri ARC Ödülü Lider Tahtası. GPT-4.5, Claude 3.7 sonnet ve Gemini 2.0 flash skor dahil olmak üzere güçlü mantıksız modeller%1 civarında.
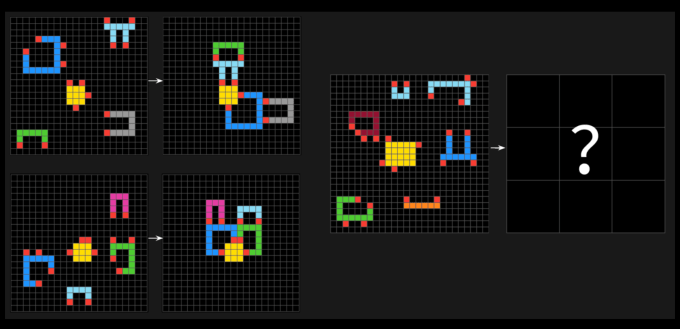
Arc-AGI testleri, bir AI’nın farklı renkli kareler koleksiyonundan görsel desenleri tanımlaması ve doğru “cevap” ızgarasını oluşturmak zorunda olduğu bulmaca benzeri problemlerden oluşur. Sorunlar, bir AI’nın daha önce görmediği yeni sorunlara uyum sağlamaya zorlamak için tasarlandı.
ARC Ödülü Vakfı, 400’den fazla insanın bir insan taban çizgisi kurmak için ARC-AGI-2 almıştı. Ortalama olarak, bu insanların “panelleri” testin sorularının% 60’ını doğru aldı – modellerin puanlarından çok daha iyi.
Bir X’e GönderinChollet, ARC-AGI-2’nin bir AI modelinin gerçek zekasının testin ilk yinelemesinden daha iyi bir ölçüm olduğunu iddia etti. ARC Ödülü Vakfı’nın testleri, bir AI sisteminin eğitildiği verilerin dışında yeni beceriler elde edip edemeyeceğini değerlendirmeyi amaçlamaktadır.
Chollet, ARC-AGI-1’in aksine, yeni testin AI modellerinin çözüm bulmak için “kaba kuvvet”-kapsamlı bilgi işlem gücüne-güvenmesini engellediğini söyledi. Chollet daha önce bunun ARC-AGI-1’in büyük bir kusuru olduğunu kabul etti.
İlk testin kusurlarını ele almak için ARC-AGI-2 yeni bir metrik sunar: verimlilik. Ayrıca, ezberlemeye güvenmek yerine kalıpları anında yorumlamak için modeller gerektirir.
Arc Ödül Vakfı kurucu ortağı Greg Kamradt, “İstihbarat sadece sorunları çözme veya yüksek puanlar elde etme yeteneği ile tanımlanmıyor” dedi. Blog yazısı. “Bu yeteneklerin elde edildiği ve dağıtıldığı verimlilik, çok önemli, tanımlayıcı bir bileşendir. Sorulan temel soru sadece ‘AI edinebilir mi? [the] Bir görevi çözme becerisi? ‘ Ama aynı zamanda, ‘Hangi verimlilik veya maliyetle?’ ‘
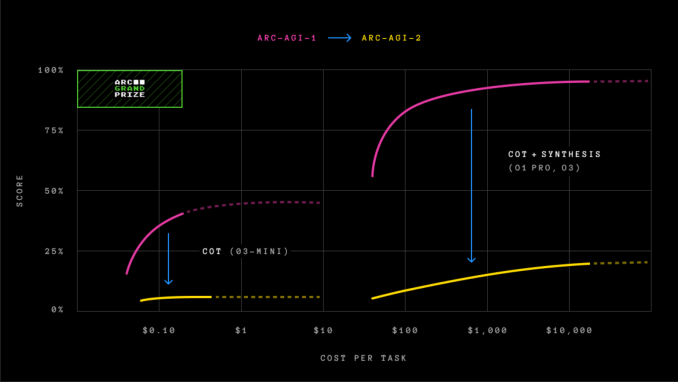
ARC-AGI-1, Openai’nin diğer tüm AI modellerinden daha iyi performans gösteren ve değerlendirmede insan performansını eşleştiren gelişmiş akıl yürütme modeli O3’ü serbest bıraktığı Aralık 2024’e kadar yaklaşık beş yıl boyunca yenilmedi. Ancak, o zamanlar belirttiğimiz gibi, O3’ün ARC-AGI-1’deki performans kazançları ağır bir fiyat etiketi ile geldi.
ARC-AGI-1’de yeni zirvelere ulaşan, testte% 75.7 puan alan Openai’nin O3 modeli-O3 (düşük)-sürümü, görev başına 200 $ değerinde bilgi işlem gücü kullanarak ARC-AGI-2’de% 4’lük bir% 4 aldı.
ARC-AGI-2’nin gelişi, teknoloji endüstrisinde birçoğu, AI ilerlemesini ölçmek için yeni, doymamış ölçütler çağrısında bulunuyor. Hugging Face’in kurucu ortağı Thomas Wolf, kısa süre önce TechCrunch’a AI endüstrisinin yaratıcılık da dahil olmak üzere yapay genel zekanın temel özelliklerini ölçmek için yeterli testlerden yoksun olduğunu söyledi.
Yeni karşılaştırmanın yanı sıra, ARC Ödülü Vakfı Yeni Bir ARC Ödülü 2025 Yarışmasıgeliştiricileri ARC-AGI-2 testinde% 85 doğruluğa ulaşmaya zorlarken, görev başına sadece 0.42 $ harcıyor.




