
Une IA aux réponses uniformes : La fin de la diversité cognitive ?
Nous avons désormais accès à des modèles d’intelligence artificielle (IA) de plus en plus performants. Cependant, une étude récente révèle un problème alarmant : la uniformité des réponses entre ces modèles. Des chercheurs de plusieurs institutions, dont l’Université de Washington et l’Université de Stanford, ont mené une expérience qui démontre que ces systèmes, bien que sophistiqués, manquent cruellement de diversité.
Une “mente-ruche artificielle”
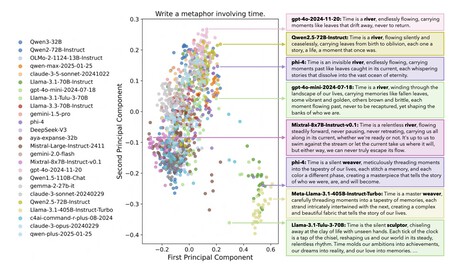
Les experts ont constaté que les différents modèles de IA, lorsqu’interrogés sur divers sujets, fournissent des réponses étonnamment similaires, donnant l’impression d’une “mente-ruche artificielle”. Par exemple, en se demandant ce qu’est le temps, plusieurs modèles ont affirmé que “le temps est comme un fleuve”, tandis que d’autres ont opté pour “le temps est comme un tisserand”. Cette homogénéité de réponses est devenue une constante au fil de leurs tests.
Illusion de diversité
En interagissant avec une IA, les utilisateurs pensent accéder à une variété infinie de réponses. Pourtant, cette étude démontre que les modèles, bien qu’ils soient conçus pour être créatifs, ont tendance à converger vers des réponses semblables, sacrifiant la diversité au profit de la cohérence statistique.
Des données en boucle
Les chercheurs ont créé un vaste ensemble de données nommé “Infinity-Chat”, comprenant 26 000 questions d’utilisateurs réels. Ces questions étaient organisées en six catégories principales. Cependant, même avec cette diversité apparente dans les questions, les réponses générées restaient souvent très similaires, témoignant d’un “effondrement inter-modèle”.
La répétition des modèles
Lors des tests, il a été observé que les modèles avaient tendance à se répéter, générant des réponses presque identiques, même avec des paramètres conçus pour encourager la diversité. Cette répétition soulève des inquiétudes sur la capacité des IA à produire des réponses uniques.
Un problème structurel dans l’entraînement
Les résultats de l’étude soulèvent également des questions sur le processus d’entraînement des modèles. Les auteurs suggèrent que cette homogénéité de réponses pourrait être due à plusieurs facteurs :
- Données d’entraînement partagées : Les modèles se forment sur des ensembles de données similaires, souvent issus de sources comme Wikipedia.
- Contamination par des données synthétiques : Utilisation de textes générés par d’autres modèles d’IA, ce qui contribue à la similarité.
- Le biais des récompenses : Les systèmes de récompenses favorisent des réponses “consensuelles”, décourageant ainsi la créativité.
Deux risques à surveiller
Les chercheurs mettent en garde contre deux risques majeurs associés à cette situation :
- Uniformité de la pensée : Si les utilisateurs s’appuient sur des modèles qui produisent des réponses similaires, nos propres opinions et réflexions pourraient devenir homogènes.
- Réduction des points de vue : La convergence des réponses pourrait mener à une perte de perspectives diverses, particulièrement présente dans les modèles occidentaux par rapport à des modèles orientaux.
La diversité est essentielle pour une société dynamique et innovante. Si les IA continuent à converger vers des réponses similaires, nous risquons de nous retrouver dans une réalité où les opinions et les perspectives sont uniformisées, limitant ainsi notre capacité à penser de manière critique et créative.