

In 2017, the paper “Attention is All You Need” by Google revolutionized the technical foundation of language generation with the introduction of Transformers . These models enabled parallel processing of long sequences and allowed for the scaling of architectures far beyond earlier capabilities. This advancement led to remarkable models like GPT and BERT, establishing self-attention as a central pillar of contemporary generative AI . However, this innovative approach came with significant memory and energy costs as the context length increased, prompting researchers to seek alternatives. The newly developed Spikingbrain-1.0 aims to shatter these limitations.
From “Attention Is All You Need” to the Brain: A New Commitment to Break Boundaries
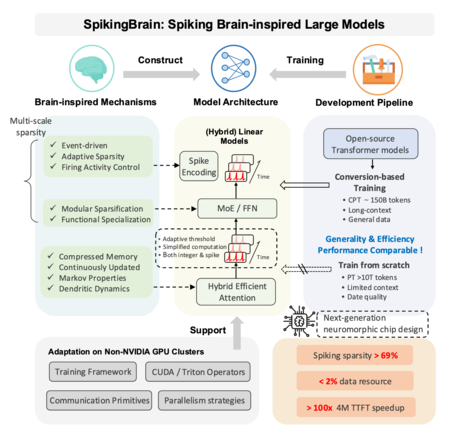
A team from the Chinese Academy of Sciences Automation Institute has recently presented Spikingbrain-1.0, a family of spiking models designed to reduce the data and computational resources required for tasks that involve very long contexts. The experts propose two distinct approaches: Spikingbrain-7B , a linear architecture focused on efficiency , and Spikingbrain-76B , which fuses linear attention with Mixture of Experts (MOE) mechanisms for greater capacity.
The authors of the paper detail that much of the development and testing were conducted using Metax C550 GPU clusters , utilizing specialized libraries and operators tailored for that platform. This factor makes the project not only a promising software advancement but also a demonstration of homegrown hardware capabilities . The significance of this development is heightened when considering China’s strategic effort to reduce its dependence on Nvidia—a strategy we observed previously with DeepSeek 3.1 .
Spikingbrain-1.0 draws direct inspiration from how the human brain operates. Rather than relying on neurons that continuously compute values, it utilizes spiky neurons —units that accumulate signals until they surpass a threshold and trigger a spike. During intervals between spikes, these neurons remain inactive, conserving both operational resources and energy. A vital concept here is that not only the number of spikes matters but also the timing and sequence of these spikes, which relay information akin to brain functions.
In order to merge this design effectively within the current ecosystem, the team developed methodologies that convert traditional self-attention blocks into linear versions , facilitating easier integration into the spiky system. Furthermore, they introduced a form of “ virtual time ” that simulates temporal processes without compromising GPU productivity. The Spikingbrain-76B variant also incorporates MOE, activating only specific submodels when needed, a feature already seen in GPT-4O and GPT-5.
The authors of the study suggest applications where context length is crucial, such as large legal document analysis, comprehensive medical records evaluation, DNA sequencing, and the management of massive experimental datasets in high-energy physics. The rationale for these applications is presented in the document—if the architecture operates efficiently with contexts containing millions of tokens, it could lower costs and open up possibilities in domains currently constrained by expensive computational infrastructure. However, validation in real-world scenarios outside laboratory conditions remains pending.

The team has made the code for the 7 billion parameter model available on GitHub, alongside a detailed technical report. They also provide a web interface similar to ChatGPT for interacting with the model, which is entirely deployed on national hardware. However, access is currently limited to Chinese users , complicating its use outside this specific ecosystem. While the proposal is ambitious, its true impact will depend on the broader community’s ability to reproduce results and conduct comparisons in consistent environments that evaluate accuracy, latency, and energy consumption under real-world conditions.
Images | Xataka with Gemini 2.5 | ABODI VESAKARAN
In Xataka | OpenAI believes it has discovered why AI sometimes hallucinates: they struggle to convey uncertainty effectively.