Her Pazar, NPR sunucusu New York Times’ın bulmaca gurusu Will Shortz, uzun süredir devam eden bir segmentte binlerce dinleyiciyi test ediyor. Pazar Bulmacası. Olmadan çözülebilecek şekilde yazılırken fazla Çok öngörü, Brainteasers vasıflı yarışmacılar için bile zordur.
Bu yüzden bazı uzmanlar AI’nın problem çözme yeteneklerinin sınırlarını test etmenin umut verici bir yolu olduğunu düşünüyor.
Bir Son çalışmaWellesley College, Oberlin Koleji, Austin, Northeastern Üniversitesi, Charles Üniversitesi, Teksas Üniversitesi, Teksas Üniversitesi’nden gelen bir araştırmacı ekibi ve Startup Cursor, Pazar Bulma Bulma bölümlerinden bilmeceler kullanarak bir AI ölçütü oluşturdu. Ekip, testlerinin bu akıl yürütme modelleri – Openai’nin O1’i – diğerlerinin yanı sıra – bazen “vazgeçtiğini” ve doğru olmadığını bildikleri cevapları sağladığını söyledi.
Northeastern’de bilgisayar bilimi öğretim üyesi ve çalışmanın ortak yazarlarından biri olan Arjun Guha, TechCrunch’a verdiği demeçte, “İnsanların sadece genel bilgi ile anlayabileceği sorunlarla bir ölçüt geliştirmek istedik” dedi.
Yapay zeka endüstrisi şu anda biraz kıyaslama konusunda. Ortalama bir kullanıcı ile ilgili olmayan doktora düzeyinde matematik ve bilim sorularında yetkinlik gibi AI modelleri problarını değerlendirmek için yaygın olarak kullanılan testlerin çoğu. Bu arada, birçok ölçüt – hatta Nispeten yakın zamanda piyasaya sürülen kriterler – Doygunluk noktasına hızla yaklaşıyor.
Sunday bulmacası gibi bir halka açık radyo sınav oyununun avantajları, ezoterik bilgi için test etmemesi ve zorlukların, modellerin bunları çözmek için “rote belleğine” çekilemeyeceği şekilde ifade ediliyor.
Guha, “Bu sorunları zorlaştıran şey, bunu çözene kadar bir sorun üzerinde anlamlı bir ilerleme kaydetmenin gerçekten zor olması – o zaman her şey bir kerede birlikte tıklıyor” dedi. “Bu, bir içgörü ve bir eleme süreci kombinasyonu gerektirir.”
Elbette hiçbir kıyaslama mükemmel değildir. Pazar bulmaca sadece ABD merkezli ve İngilizce. Ve sınavlar halka açık olduğu için, Guha bunun kanıt görmediğini söylese de, onlara eğitilmiş modellerin bir anlamda “hile yapabilmesi” mümkündür.
“Her hafta yeni sorular yayınlanıyor ve en son soruların gerçekten görülmemesini bekleyebiliriz” diye ekledi. “Benchmark’ı taze tutmayı ve model performansının zaman içinde nasıl değiştiğini izlemeyi planlıyoruz.”
Yaklaşık 600 Pazar bulmaca bilmecesinden oluşan araştırmacıların karşılaştırmasında, O1 ve Deepseek’in R1 gibi akıl yürütme modelleri geri kalanından daha iyi performans gösteriyor. Akıl yürütme modelleri, sonuç vermeden önce kendilerini iyice kontrol eder, bu da normalde AI modellerini gezen bazı tuzaklardan kaçınmalarına yardımcı olur. Değişiklik, akıl yürütme modellerinin çözümlere ulaşması biraz daha uzun sürüyor-tipik olarak saniye ila dakika daha uzun.
En az bir model olan Deepseek’in R1, bazı Pazar bulmaca soruları için yanlış olduğunu bildiği çözümler sunuyor. R1, “Vazgeçiyorum”, ardından görünüşte rastgele görünen yanlış bir cevap – bu insanın kesinlikle ilişki kurabileceği davranışları söyleyecek.
Modeller, sadece hemen geri çekmek için yanlış bir cevap vermek, daha iyi bir tane almaya çalışmak ve tekrar başarısız olmak gibi diğer tuhaf seçimler yapar. Ayrıca sonsuza dek “düşünürler” ve cevaplar için saçma açıklamalar verirler ya da hemen doğru bir cevaba ulaşırlar, ancak daha sonra belirgin bir nedenden dolayı alternatif cevapları düşünmeye devam ederler.
Guha, “Zor problemlerde, R1 kelimenin tam anlamıyla ‘hayal kırıklığına uğradığını’ söylüyor,” dedi. “Bir modelin bir insanın ne söyleyebileceğini nasıl taklit ettiğini görmek komikti. Akıl yürütmede ‘hayal kırıklığının’ model sonuçlarının kalitesini nasıl etkileyebileceği görülüyor. ”

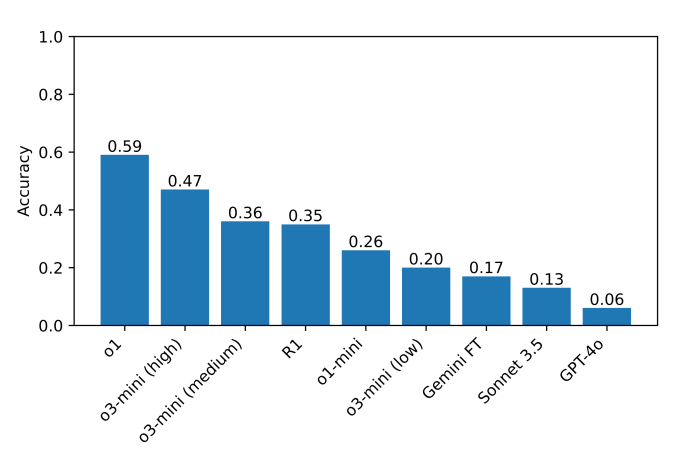
Karşılaştırma üzerindeki mevcut en iyi performans gösteren model,%59 puanla O1, ardından yakın zamanda piyasaya sürülen O3-mini yüksek “akıl yürütme çabası” (%47). (R1%35 puan aldı.) Bir sonraki adım olarak, araştırmacılar testlerini bu modellerin geliştirilebileceği alanları belirlemeye yardımcı olacağını umdukları ek akıl yürütme modellerine genişletmeyi planlıyorlar.
Guha, “Akıl yürütmede iyi olmak için doktora yapmanız gerekmiyor, bu nedenle doktora düzeyinde bilgi gerektirmeyen akıl yürütme ölçütleri tasarlamak mümkün olmalı” dedi. “Daha geniş erişime sahip bir ölçüt, daha geniş bir araştırmacının sonuçları anlamasını ve analiz etmesini sağlar, bu da gelecekte daha iyi çözümlere yol açabilir. Dahası, en son model modeller herkesi etkileyen ortamlarda giderek daha fazla konuşlandırıldığından, herkesin bu modellerin ne olduğunu ve yapamayacağını sezgisel yapabilmesi gerektiğine inanıyoruz. ”






