
Büyük dil modelleri ve GPU ile hızlandırılmış “birinci sınıf AI PC” deneyimleri 2024’ün en yeni trendi olarak göründüğünden, Nvidia son yıllarda yapay zekaya yönelerek büyük bir başarı elde etti. Ancak daha yeni, daha küçük şirketler rekabet ediyor pazar payı için ve bunlar beklediğiniz kişiler değil.
The Economist’in haberine göre, Nvidia ve AMD’nin yapay zeka bilişimi için ürettiği en iyi grafik kartlarının dışında GPU alanında da gelişmeler yaşanıyor. Bunun nedeni, günümüzün büyük dil modellerinden bazılarının, Cerebras donanımı gibi birbirine bağlı GPU’lar ve bellek içeren birçok kurulumda çalışmasıdır.
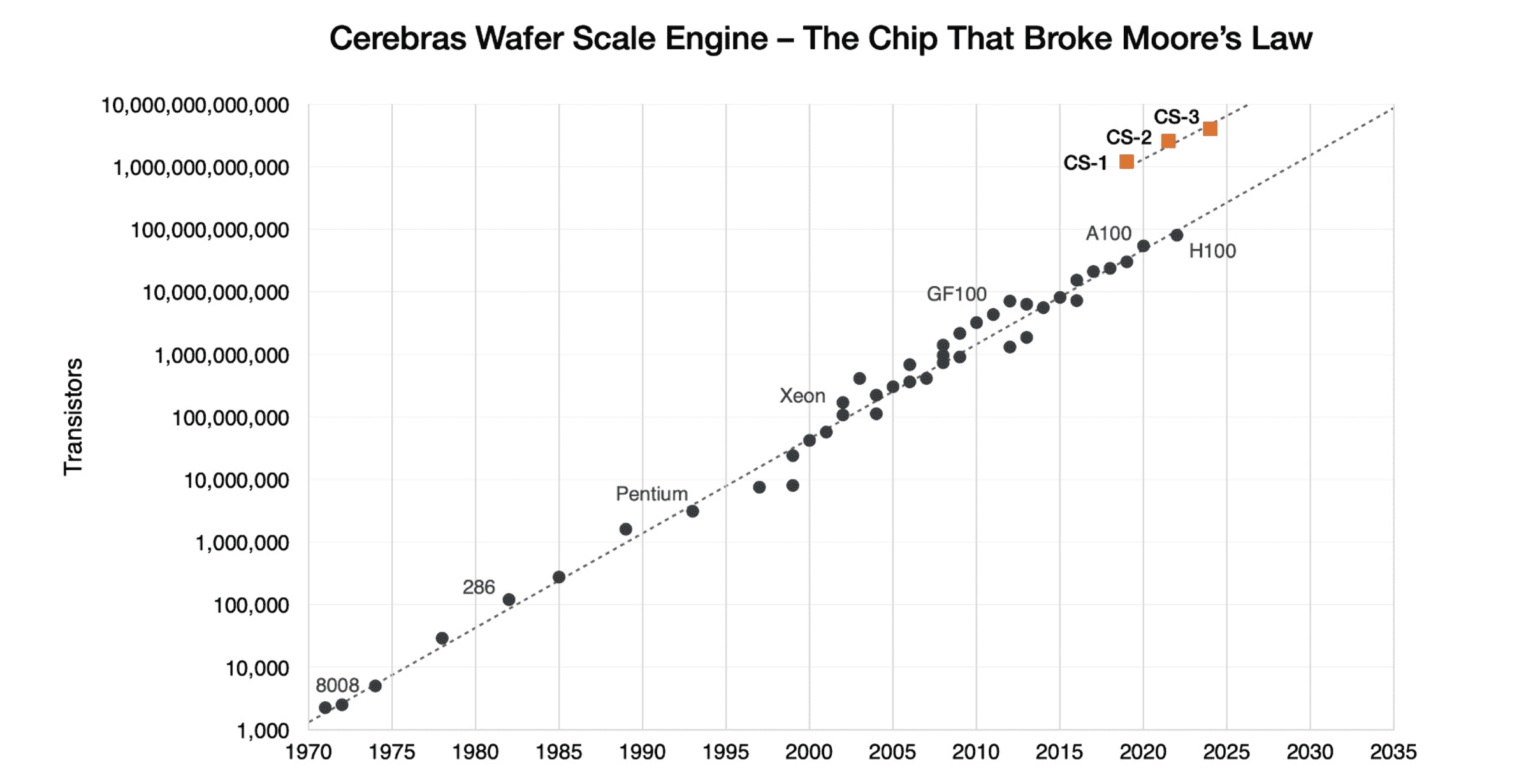
Cerebras Systems Inc. yalnızca dokuz yıl önce kuruldu ancak son zamanlardaki yapay zeka bilgi işlem patlamasından büyük ölçüde faydalanmış gibi görünüyor. CS-3 çipi gibi, 900.000’e kadar GPU çekirdeğinden oluşan “tek, devasa çip” kablosuyla mevcut nesil H100’ü ve gelecek GB200’ü utandıracak gibi görünen şekillerde yenilikler yapıldı.
Cerebras CS-3 çipi Devasa GB200’ün çift kalıp boyutunu kesinlikle gölgede bırakıyor ve bir direksiyon simidi boyutunda, tutması için iki el gerekiyor. Üretici tarafından “dünyanın en gelişmiş yapay zeka modellerini eğitmek” amacıyla tasarlanmış “dünyanın en hızlı ve en ölçeklenebilir yapay zeka hızlandırıcısı” olarak tanımlanıyor.
Dahası, Amerikalı üretici, Wafer Scale Engine’in “Moore Yasasını çiğneyen çip” olduğunu belirterek iki katına çıktı. Dahili kriterlerin gösterdiği gibi CS-3, toplam 10.000.000.000.000 transistörle H100’ün üzerinde güvenle yer alıyor. Referans olarak GB200, 208.000.000.000’e ayarlanmıştır, CS-3 ise %4.707’lik şaşırtıcı bir artışa sahiptir.
Ancak burada hamle yapan sadece Cerebras değil, zira yeni start-up şirketi Groq da yapay zeka bilişimi için donanım geliştiriyor. Rakiplerinden daha büyük olmak yerine, büyük dil modellerini etkili ve hızlı bir şekilde çalıştırmak için oluşturulmuş özel LPU’lar (dil işleme birimleri) adını verdiği şeyi geliştirdi.
Şirketin kendi deyimiyle, Groq LPU Çıkarım Motoru “basit bir tasarımda önemli performans, verimlilik ve hassasiyet sağlayan uçtan uca çıkarım sistemi hızlandırma sistemidir”. Şu anda büyük ölçekli bir üretken dil ve metin modeli olan Llama-2 70B’yi kullanıcı başına saniyede 300 jetonla çalıştırıyor.
Bu başarı, veri merkezinde CPU ve GPU ile birlikte bulunan LPU sayesinde mümkün oluyor ve bu da düşük gecikmeyi ve gerçek zamanlı teslimatı mümkün kılıyor. Bunu, bir çipin kalbinde, belirli bir amaca göre ve çok daha büyük bir ölçekte ince ayarlı daha karmaşık bir NPU’ya sahip olmak olarak düşünün ve paranızın karşılığını alıyorsunuz.
Yapay zeka pazarının karlılığı rekabet anlamına geliyor
Nvidia’nın son yıllardaki mali başarısı bir sır değil, çünkü Team Green kısa süreliğine Amazon’dan daha değerliydi, hatta Alphabet’e (Google’ın ana şirketi) parasının karşılığını verdi. Bunun gibi rakamlar varken, daha fazla üreticinin ringe çıkıp şahdamarına yönelmesi şaşırtıcı değil.
Cerebras ve Groq gibi şirketlerin veya hatta MatX gibi daha küçük şirketlerin burada bir şansa sahip olup olmayacağını zaman gösterecek, ancak yapay zeka hesaplaması hala büyük ölçüde başlangıç aşamasında olduğundan, şu anda en fazla deneyi göreceğimiz zaman. donanımın son kullanıcıya nasıl hitap edebileceği. Bazıları ölçeklenecek, bazıları ise daha akıllı çalışacak.