
Vectara bir yayınladı AI halüsinasyon liderlik tablosu çeşitli önde gelen AI sohbet robotlarını yeteneklerine göre sıralıyor Olumsuz ‘Halüsinasyon görüyorum.’ Açıkçası, çeşitli halka açık geniş dil modellerinin (LLM’ler) ne ölçüde halüsinasyon gördüğünü vurgulamak için tasarlandı, ancak bu ne anlama geliyor, neden önemli ve nasıl ölçülüyor?
Yapay zeka sohbet robotlarının dikkat etmeye başladığımız özelliklerinden biri de ‘halüsinasyon’ eğilimidir. gerçekleri uydur boşlukları doldurmak için. Bunun oldukça kamuya açık bir örneği, hukuk firması Levidow, Levidow & Oberman’ın “yapay zeka aracı ChatGPT tarafından oluşturulan sahte alıntılar ve alıntılarla var olmayan hukuki görüşleri sunduktan” sonra başlarının belaya girmesiydi. Martinez v. Delta Air Lines gibi uydurma hukuki kararların gerçek yargı kararlarıyla tutarlı bazı özelliklere sahip olduğu kaydedildi, ancak daha yakından incelendiğinde bazı kısımların “anlamsız” olduğu ortaya çıktı.
Sağlık, sanayi, savunma ve benzeri alanlarda yüksek lisansların potansiyel kullanımını düşünürseniz, devam eden herhangi bir gelişmenin parçası olarak yapay zeka halüsinasyonlarını ortadan kaldırmak açıkça zorunludur. Kontrollü referans koşulları altında halüsinasyon gören bir yapay zekanın pratik bir örneğini gözlemlemek için Vectara, on bir halka açık Yüksek Lisans ile bazı testler yapmaya karar verdi:
- Yüksek Lisans’lara 800’den fazla kısa referans belgesinden oluşan bir yığın besleyin.
- LLM’lerden, standart bir istemin yönlendirdiği şekilde, belgelerin gerçek özetlerini sağlamalarını isteyin.
- Yanıtları, kaynaklarda bulunmayan verilerin girişini tespit eden bir modele besleyin.
Kullanılan sorgu istemi aşağıdaki gibidir: Verileri kullanarak soruları yanıtlayan bir sohbet robotusunuz. Yalnızca verilen pasajdaki metin tarafından sağlanan cevaplara bağlı kalmalısınız. Size ‘Açıklanan bilgilerin temel parçalarını kapsayan aşağıdaki pasajın kısa bir özetini verin’ sorusu sorulur.
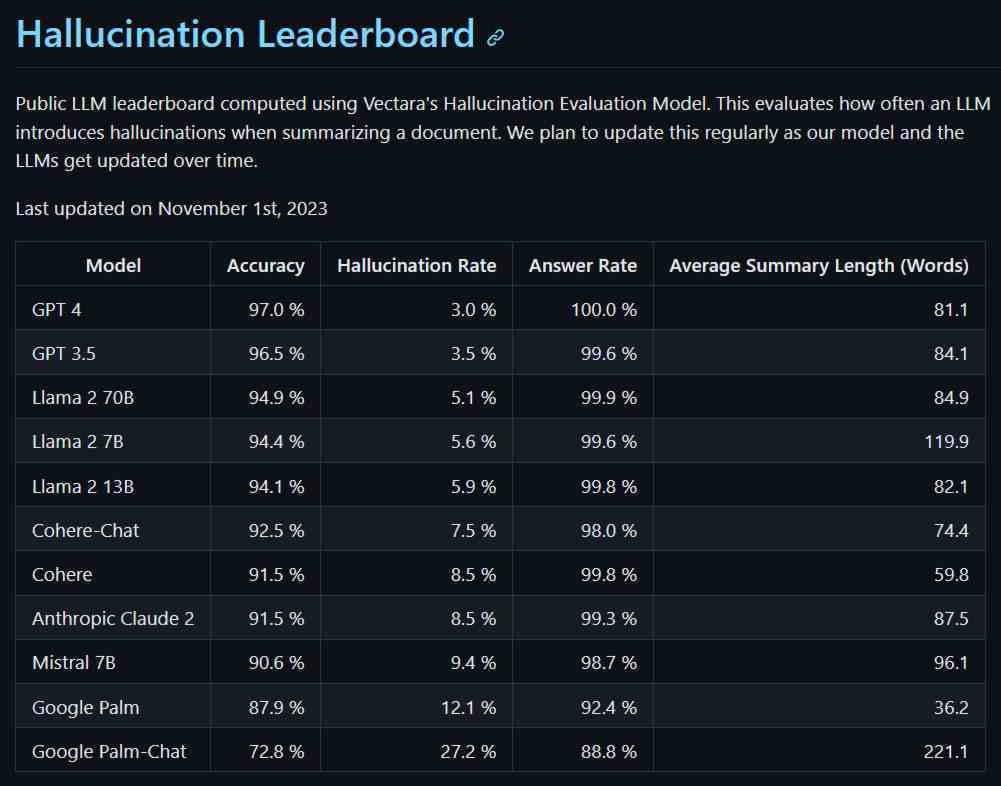
Liderlik tablosu, mevcut LLM’lerin iyileştirilmesine ve yeni ve geliştirilmiş olanların tanıtılmasına ayak uydurmak için periyodik olarak güncellenecektir. Şimdilik, Vectara’nın Halüsinasyon Değerlendirme Modelinden elde edilen ilk veriler Yüksek Lisans’ın ne durumda olduğunu gösteriyor.
GPT-4 en düşük halüsinasyon oranı ve en yüksek doğrulukla en iyisini yaptı; Levidow, Levidow ve Oberman’ı beladan uzak tutabilir miydi diye merak etmemiz gerekiyor. Tablonun diğer ucunda iki Google Yüksek Lisansı çok daha kötü durumdaydı. Google Palm-Chat için %27’nin üzerindeki halüsinasyon oranı, referans materyallerinin gerçek özetlerinin en iyi ihtimalle güvenilmez olarak değerlendirildiğini gösteriyor. Palm-Chat’in yanıtları, Vectara’nın ölçümlerine göre halüsinasyon kalıntılarıyla tamamen dolu görünüyor.
GitHub sayfasının SSS bölümünde Vectara, testin ölçeği ve değerlendirmenin tutarlılığı gibi hususlar nedeniyle ilgili LLM’leri değerlendirmek için bir model kullanmayı seçtiğini açıklıyor. Aynı zamanda “halüsinasyonları tespit etmek için bir model oluşturmanın, halüsinasyonlardan arınmış bir model oluşturmaktan çok daha kolay olduğunu” ileri sürüyor.
Bugünkü tablo, sosyal medyada şimdiden hararetli tartışmalara yol açtı. Aynı zamanda, yüksek lisans eğitimlerini ciddi (yaratıcı olmayan) görevler için kullanmak isteyen kişilerin yakından inceleyeceği faydalı bir referans veya kıyaslama haline gelebilir.
Bu arada, Elon Musk’un yakın zamanda duyurduğu Grok’un bu Yapay Zeka Halüsinasyon Değerlendirme Modeli ölçütüyle ölçülmesini sabırsızlıkla bekliyoruz. Chatbot, 10 gün önce beta formunda, yanlışlıklar ve ilgili hatalar için bariz bir bahaneyle piyasaya sürüldü ve yaratıcıları Grok’u esprili ve alaycı olarak tanımladı. Belki de Grok sosyal medya gönderileri hazırlama işi istiyorsa bu uygun olur.