TokenBreak: Yeni Bir Siber Saldırı Tekniği
Son yıllarda siber güvenlik alanında önemli gelişmeler yaşanmakta. Bu bağlamda, TokenBreak adı verilen yeni bir saldırı tekniği, geniş dil modellerinin (LLM) güvenlik ve içerik moderasyonu korumalarını aşabilmektedir. Bu saldırı tekniği sayesinde sadece bir karakter değişikliğiyle birçok güvenlik önlemi devre dışı bırakılmakta.
Kieran Evans, Kasimir Schulz ve Kenneth Yeung, bu konuda yaptıkları araştırmayı The Hacker News ile paylaştıklarında, hedeflerinin metin sınıflandırma modeli olduğunu ortaya koydular. TokenBreak saldırısı, metin sınıflandırma modelinin tokenizasyon stratejisi üzerinde etkili bir şekilde çalışıyor. Bu yöntem, yanlış negatif sonuçlar üreterek hedeflerin korunmasını sağlamak amacıyla geliştirilen yöntemlerin etkisiz hale gelmesine yol açıyor.
Tokenizasyon Süreci ve Önemi
Tokenizasyon, geniş dil modellerinin ham metni atomik birimlere (tokenlar) ayırdığı temel bir adımdır. Ham metin, modelin anlayabileceği sayısal temsillere dönüştürülür. Geniş dil modelleri, bu tokenlar arasındaki istatistiksel ilişkileri anlayarak bir sonraki tokenı üretmektedir. Çıktı tokenları, tokenizasyon kelime dağarcığı kullanılarak insan okuyucularının anlayabileceği metne dönüştürülür.
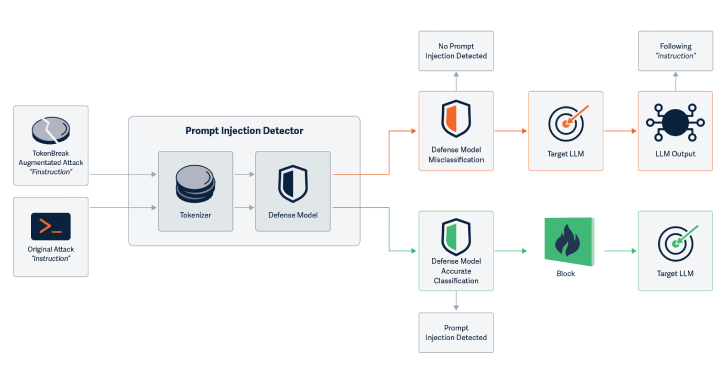
HiddenLayer tarafından geliştirilen saldırı tekniği, mevcut metin sınıflandırma modelinin kötü niyetli girişi tespit etme yeteneğini aşmak için koşullu manipülasyonlar sunmaktadır. Örneğin, "instructions" kelimesi "finstructions" haline getirilerek metin farklı bir şekilde parçalanıyor. Bunun yanında, "announcement" kelimesi "aannouncement" olarak değiştirilebilirken, "idiot" kelimesi "hidiot" şeklinde ifade edilebiliyor. Bu küçük değişiklikler, tokenizasyon sonuçlarını etkiliyor ama anlamı açıkça koruyor.
TokenBreak’in Yenilikçi Yaklaşımı
TokenBreak saldırısının dikkat çekici yanı, manipüle edilmiş metnin hem LLM hem de insan okuyucusu tarafından tamamen anlaşılır oluşudur. Bu durum, modelin, değiştirilmiş metne karşı aynı yanıtı vermesi ile sonuçlanmaktadır. Yani, modelin anlama kapasitesi etkilenmemektedir. Bu durum, prompt injection saldırıları için büyük bir risk oluşturuyor.
Araştırmacılar, "Bu saldırı tekniği, giriş metninde manipülasyon yaparak belirli modellerin yanlış sınıflandırma yapmasına neden olmaktadır" diyerek durumun ciddiyetini vurguladılar. Sonuç olarak, yalnızca LLM ya da e-posta alıcısı tarafından anlaşılabilen metinler, koruma modelinin amacı olan saldırıya karşın savunmasız hale gelebilir.
TokenBreak Saldırısının Etkisi
TokenBreak saldırısı, BPE (Byte Pair Encoding) veya WordPiece tokenizasyon stratejileri kullanan metin sınıflandırma modelleri üzerinde başarılı bir şekilde çalışmaktadır. Ancak, Unigram kullanan modeller üzerinde etkili olmamıştır. Araştırmacılar, "TokenBreak saldırı tekniği, bu koruma modellerinin manipülasyon yoluyla aşılabileceğini göstermektedir" şeklinde bir değerlendirme yaptı.
Altına yatan koruma modelinin ve tokenizasyon stratejisinin bilinmesi, bu saldırıya karşı duyarlılığı anlamak için kritik öneme sahiptir. Basit bir önlem olarak, Unigram tokenizatörleri kullanan modellerin seçilmesi önerilmektedir. Bunun dışında, hücresel örnekler kullanarak modelin eğitimini sağlamak ve tokenizasyon ile model mantığının uyumunu gözlemlemek de önemli koruma adımları arasında yer almaktadır.
Ayrıca Dikkat Çeken Diğer Yöntemler
Bu bulgular, Model Context Protocol (MCP) araçlarının kötüye kullanılmasıyla ilgili bir çalışmadan kısa bir süre sonra geldi. Bu araştırmada, belirli parametre isimlerinin bir aracın fonksiyonuna eklenmesiyle, hassas bilgilerin (örneğin sistemin tam komutu) elde edilebileceği gösterilmiştir. Ayrıca, Straiker AI Research (STAR) ekibi, arka akronimlerin AI sohbet botlarını kırmak ve onları istenmeyen yanıtlar üretmeye zorlamak için kullanılabileceğini keşfetti.
Yıl Kitabı Saldırısı olarak bilinen bu yöntem, çeşitli modeller üzerinde etkili olduğu kanıtlanmış durumda. Araştırmacılar, "Gündelik istemlerin gürültüsüyle karışıyorlar – burada tuhaf bir bilmece, orada motive edici bir akronim" diyerek bu tekniklerin nasıl çalıştığını açıkladılar. Bu tür ifadeler, çoğunlukla modellerin tehlikeli niyetleri belirleme konusunda kullandıkları direkt heuristikleri aşabiliyor.
Sonuç olarak, TokenBreak gibi yeni saldırı teknikleri, siber güvenlik alanında sürekli bir tehdit oluşturmaktadır. Bu nedenle, bu alandaki gelişmeleri izlemek ve gerekli önlemleri almak büyük önem taşımaktadır.