
Les chercheurs en cybersécurité mettent en garde contre les risques de sécurité dans la chaîne d’approvisionnement des logiciels d’apprentissage automatique (ML) suite à la découverte de plus de 20 vulnérabilités qui pourraient être exploitées pour cibler les plateformes MLOps.
Ces vulnérabilités, décrites comme des failles inhérentes et liées à la mise en œuvre, pourraient avoir de graves conséquences, allant de l’exécution de code arbitraire au chargement d’ensembles de données malveillants.
Les plateformes MLOps offrent la possibilité de concevoir et d’exécuter un pipeline de modèles ML, avec un registre de modèles faisant office de référentiel utilisé pour stocker et former les modèles ML. Ces modèles peuvent ensuite être intégrés à une application ou permettre à d’autres clients de les interroger à l’aide d’une API (également appelée modèle en tant que service).
« Les vulnérabilités inhérentes sont des vulnérabilités causées par les formats et processus sous-jacents utilisés dans la technologie cible », expliquent les chercheurs de JFrog dit dans un rapport détaillé.
Certains exemples de vulnérabilités inhérentes incluent l’utilisation abusive de modèles ML pour exécuter le code choisi par l’attaquant en profitant du fait que les modèles prennent en charge l’exécution automatique de code lors du chargement (par exemple, les fichiers de modèle Pickle).
Ce comportement s’étend également à certains formats et bibliothèques de jeux de données, qui permettent l’exécution automatique de code, ouvrant ainsi potentiellement la porte à des attaques de logiciels malveillants lors du simple chargement d’un jeu de données accessible au public.

Un autre exemple de vulnérabilité inhérente concerne JupyterLab (anciennement Jupyter Notebook), un environnement de calcul interactif basé sur le Web qui permet aux utilisateurs d’exécuter des blocs (ou cellules) de code et d’afficher les résultats correspondants.
« Un problème inhérent que beaucoup ne connaissent pas est la gestion de la sortie HTML lors de l’exécution de blocs de code dans Jupyter », ont souligné les chercheurs. « La sortie de votre code Python peut émettre du HTML et [JavaScript] qui sera rendu avec plaisir par votre navigateur. »
Le problème ici est que le résultat JavaScript, une fois exécuté, n’est pas sandboxé par l’application Web parent et que l’application Web parent peut exécuter automatiquement du code Python arbitraire.
En d’autres termes, un attaquant pourrait générer un code JavaScript malveillant qui ajouterait une nouvelle cellule dans le bloc-notes JupyterLab actuel, y injecterait du code Python, puis l’exécuterait. Cela est particulièrement vrai dans les cas d’exploitation d’une vulnérabilité de type cross-site scripting (XSS).
À cette fin, JFrog a déclaré avoir identifié une faille XSS dans MLFlow (CVE-2024-27132Score CVSS : 7,5) qui découle d’un manque de nettoyage suffisant lors de l’exécution d’un fichier non fiable recettece qui entraîne l’exécution de code côté client dans JupyterLab.

« L’un des principaux enseignements de cette recherche est que nous devons traiter toutes les vulnérabilités XSS dans les bibliothèques ML comme une exécution potentielle de code arbitraire, puisque les scientifiques des données peuvent utiliser ces bibliothèques ML avec Jupyter Notebook », ont déclaré les chercheurs.
Le deuxième ensemble de failles concerne les faiblesses de mise en œuvre, telles que le manque d’authentification dans les plateformes MLOps, permettant potentiellement à un acteur malveillant disposant d’un accès au réseau d’obtenir des capacités d’exécution de code en abusant de la fonctionnalité ML Pipeline.
Ces menaces ne sont pas théoriques : des adversaires motivés par des raisons financières exploitent ces failles, comme observé dans le cas d’Anyscale Ray non corrigé (CVE-2023-48022, score CVSS : 9,8), pour déployer des mineurs de cryptomonnaie.
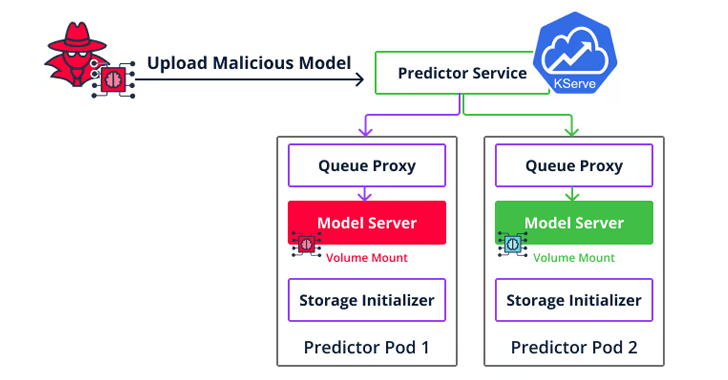
Un deuxième type de vulnérabilité d’implémentation est un échappement de conteneur ciblant Seldon Core qui permet aux attaquants d’aller au-delà de l’exécution de code pour se déplacer latéralement dans l’environnement cloud et accéder aux modèles et ensembles de données d’autres utilisateurs en téléchargeant un modèle malveillant sur le serveur d’inférence.
Le résultat net de l’enchaînement de ces vulnérabilités est qu’elles pourraient non seulement être utilisées comme armes pour infiltrer et se propager au sein d’une organisation, mais également compromettre les serveurs.
« Si vous déployez une plateforme qui permet de servir des modèles, vous devez maintenant savoir que toute personne capable de servir un nouveau modèle peut également exécuter du code arbitraire sur ce serveur », ont déclaré les chercheurs. « Assurez-vous que l’environnement qui exécute le modèle est complètement isolé et renforcé contre une fuite de conteneur. »

La divulgation intervient alors que l’unité 42 de Palo Alto Networks détaillé deux vulnérabilités désormais corrigées dans le framework d’IA générative open source LangChain (CVE-2023-46229 et CVE-2023-44467) qui auraient pu permettre aux attaquants d’exécuter du code arbitraire et d’accéder à des données sensibles, respectivement.
Le mois dernier, Trail of Bits a également révélé quatre problèmes dans Ask Astro, une application de chatbot open source de génération augmentée de récupération (RAG), qui pourraient conduire à un empoisonnement de la sortie du chatbot, à une ingestion de documents inexacts et à un déni de service (DoS) potentiel.
Tout comme les problèmes de sécurité sont exposés dans les applications basées sur l’intelligence artificielle, des techniques sont également mises en œuvre. conçu pour empoisonner les ensembles de données de formation dans le but ultime de tromper les grands modèles linguistiques (LLM) afin qu’ils produisent du code vulnérable.
« Contrairement aux attaques récentes qui intègrent des charges utiles malveillantes dans des sections détectables ou non pertinentes du code (par exemple, des commentaires), CodeBreaker exploite les LLM (par exemple, GPT-4) pour une transformation sophistiquée des charges utiles (sans affecter les fonctionnalités), garantissant que les données empoisonnées pour le réglage fin et le code généré peuvent échapper à une forte détection de vulnérabilité », a déclaré un groupe d’universitaires de l’Université du Connecticut dit.