

Sans surprise, ici à Rembobiner, nous avons beaucoup de données à protéger (plus de 2 pétaoctets). L’une des bases de données que nous utilisons s’appelle Elasticsearch (ES ou Opensearch, comme on l’appelle actuellement dans AWS). Pour le dire simplement, ES est une base de données de documents qui facilite les résultats de recherche ultra-rapides. La rapidité est essentielle lorsque les clients recherchent un fichier ou un élément particulier qu’ils doivent restaurer à l’aide de Rembobiner. Chaque seconde d’indisponibilité compte, c’est pourquoi nos résultats de recherche doivent être rapides, précis et fiables.
Une autre considération était le désastre récupération. Dans le cadre de notre Contrôles du système et de l’organisation niveau 2 (SOC2) processus de certification, nous devions nous assurer que nous disposions d’un plan de reprise après sinistre fonctionnel pour restaurer le service dans le cas peu probable où toute la région AWS serait en panne.
« Une région AWS entière ?? Cela n’arrivera jamais ! (À l’exception de quand c’est arrivé)
Tout est possible, les choses tournent mal, et pour répondre à nos exigences SOC2, nous avions besoin d’une solution fonctionnelle. Plus précisément, nous avions besoin d’un moyen de répliquer les données de nos clients de manière sécurisée, efficace et rentable dans une autre région AWS. La réponse était de faire ce que Rewind fait si bien – faire une sauvegarde !
Découvrons comment fonctionne Elasticsearch, comment nous l’avons utilisé pour sauvegarder des données en toute sécurité et notre processus actuel de reprise après sinistre.
Instantanés
Tout d’abord, nous aurons besoin d’une leçon de vocabulaire rapide. Les sauvegardes dans ES sont appelées instantanés. Les instantanés sont stockés dans un référentiel d’instantanés. Il y a plusieurs types de référentiels d’instantanés, dont un soutenu par AWS S3. Étant donné que S3 a la capacité de répliquer son contenu dans un compartiment dans une autre région, c’était une solution parfaite pour ce problème particulier.
AWS ES est livré avec un référentiel d’instantanés automatisé pré-activé pour vous. Le référentiel est configuré par défaut pour prendre des instantanés toutes les heures et vous ne pouvez rien y changer. C’était un problème pour nous parce que nous voulions un du quotidien instantané envoyé à un référentiel soutenu par l’un de nos propres compartiments S3, qui a été configuré pour répliquer son contenu dans une autre région.
 |
| Liste des instantanés automatisés GET _cat/snapshots/cs-automated-enc?v&s=id |
Notre seul choix était de créer et de gérer notre propre référentiel d’instantanés et nos instantanés.
Maintenir notre propre référentiel d’instantanés n’était pas idéal et ressemblait à beaucoup de travail inutile. Nous ne voulions pas réinventer la roue, nous avons donc recherché un outil existant qui ferait le gros du travail pour nous.
Gestion du cycle de vie des instantanés (SLM)
Le premier outil que nous avons essayé était celui d’Elastic Gestion du cycle de vie des instantanés (SLM)une caractéristique qui est décrite comme :
Le moyen le plus simple de sauvegarder régulièrement un cluster. Une politique SLM prend automatiquement des instantanés selon un calendrier prédéfini. La stratégie peut également supprimer des instantanés en fonction des règles de conservation que vous définissez.
Vous pouvez même utiliser votre propre référentiel d’instantanés. Cependant, dès que nous avons essayé de le configurer dans nos domaines, cela a échoué. Nous avons rapidement appris qu’AWS ES est une version modifiée d’Elastic. co’s ES et que SLM n’était pas pris en charge dans AWS ES.
Conservateur
L’outil suivant que nous avons étudié s’appelle Curateur Elasticsearch. Il était open-source et maintenu par Elastic.co lui-même.
Curator est simplement un outil Python qui vous aide à gérer vos index et vos instantanés. Il a même des méthodes d’assistance pour créer des référentiels d’instantanés personnalisés, ce qui était un bonus supplémentaire.
Nous avons décidé d’exécuter Curator en tant que fonction Lambda pilotée par une règle EventBridge planifiée, le tout intégré à AWS SAM.
Voici à quoi ressemble la solution finale :
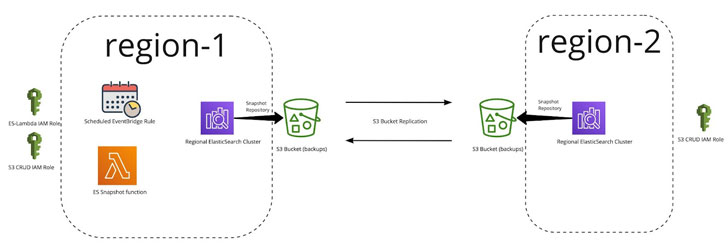
Fonction Lambda d’instantané ES
Lambda utilise l’outil Curator et est responsable de la gestion des instantanés et du référentiel. Voici un schéma de la logique :

Comme vous pouvez le voir ci-dessus, c’est une solution très simple. Mais, pour que cela fonctionne, nous avions besoin de quelques éléments pour exister :
- Rôles IAM pour accorder des autorisations
- Un compartiment S3 avec réplication vers une autre région
- Un domaine Elasticsearch avec des index
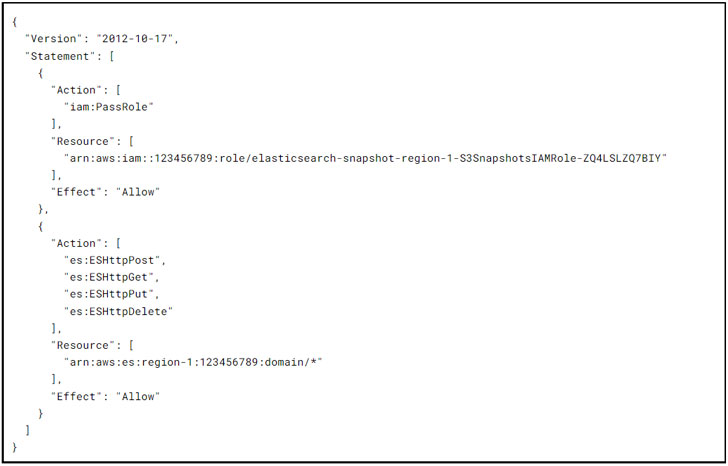
Rôles IAM
Les subventions S3SnapshotsIAMRole conservateur les autorisations nécessaires à la création du référentiel d’instantanés et à la gestion des instantanés eux-mêmes :

Les bourses EsSnapshotIAMRole Lambda les autorisations nécessaires au conservateur pour interagir avec le domaine Elasticsearch :
Compartiments S3 répliqués
L’équipe avait précédemment configuré des compartiments S3 répliqués pour d’autres services afin de faciliter la réplication entre régions dans Terraform. (Plus d’infos à ce sujet ici)
Avec tout en place, la pile cloudformation déployée dans les tests initiaux de production s’est bien déroulée et nous avons terminé… ou l’avons-nous été ?

Sauvegarde et restauration-a-thon I
Une partie de la certification SOC2 exige que vous validiez vos sauvegardes de base de données de production pour tous les services critiques. Parce que nous aimons nous amuser, nous avons décidé d’organiser un “thon de sauvegarde et de restauration” trimestriel. Nous supposerions que la région d’origine avait disparu et que nous devions restaurer chaque base de données à partir de notre réplique interrégionale et valider le contenu.
On pourrait penser “Oh mon Dieu, c’est beaucoup de travail inutile!” et vous auriez à moitié raison. C’est beaucoup de travail, mais c’est absolument nécessaire ! Dans chaque Restore-a-thon, nous avons découvert au moins un problème avec des services n’ayant pas de sauvegardes activées, ne sachant pas comment restaurer ou accéder à la sauvegarde restaurée. Sans parler de la formation pratique et de l’expérience que les membres de l’équipe acquièrent en faisant quelque chose qui n’est pas sous la haute pression d’une véritable panne. Tout comme l’organisation d’un exercice d’incendie, nos restauration-a-thons trimestriels aident à garder notre équipe préparée et prête à faire face à toute urgence.
Le premier ES Restore-a-thon a eu lieu des mois après l’achèvement et le déploiement de la fonctionnalité en production, de nombreux instantanés ont donc été pris et de nombreux anciens supprimés. Nous avons configuré l’outil pour conserver 5 jours d’instantanés et supprimer tout le reste.
Toute tentative de restauration d’un instantané répliqué à partir de notre référentiel a échoué avec une erreur inconnue et pas grand-chose d’autre à faire.
Les instantanés dans ES sont incrémentiels, ce qui signifie que plus la fréquence des instantanés est élevée, plus ils se terminent rapidement et plus leur taille est petite. L’instantané initial de notre plus grand domaine a pris plus d’une heure et demie et tous les instantanés quotidiens suivants ont pris quelques minutes !
Ce constat nous a conduit à essayer de protéger l’instantané initial et d’empêcher sa suppression en utilisant un suffixe de nom (-initial) pour le tout premier instantané pris après la création du référentiel. Ce nom d’instantané initial est ensuite exclu du processus de suppression d’instantané par Curator à l’aide d’un filtre regex.
Nous avons purgé les compartiments, les instantanés et les référentiels S3 et recommencé. Après avoir attendu quelques semaines pour que les instantanés s’accumulent, la restauration a de nouveau échoué avec la même erreur cryptique. Cependant, cette fois, nous avons remarqué que l’instantané initial (que nous avons protégé) manquait également !
Comme il ne restait plus de cycles à consacrer au problème, nous avons dû le garer pour travailler sur d’autres choses intéressantes et géniales sur lesquelles nous travaillons ici à Rembobiner.
Sauvegarde et restauration-a-thon II
Avant que vous ne vous en rendiez compte, le prochain trimestre commence et il est temps pour un autre marathon de sauvegarde et de restauration et nous réalisons qu’il s’agit toujours d’une lacune dans notre plan de reprise après sinistre. Nous devons être en mesure de restaurer les données ES dans une autre région avec succès.
Nous avons décidé d’ajouter une journalisation supplémentaire à Lambda et de vérifier quotidiennement les journaux d’exécution. Les jours 1 à 6 fonctionnent parfaitement bien – les restaurations fonctionnent, nous pouvons lister tous les instantanés, et le premier est toujours là. Le 7e jour, quelque chose d’étrange s’est produit – l’appel pour répertorier les instantanés disponibles a renvoyé une erreur “introuvable” uniquement pour l’instantané initial. Quelle force externe supprime nos instantanés ? ?
Nous avons décidé d’examiner de plus près le contenu du compartiment S3 et de constater qu’il s’agit uniquement d’UUID (Universally Unique Identifier) avec certains objets corrélant les instantanés, à l’exception de l’instantané initial qui manquait.
Nous avons remarqué l’interrupteur à bascule “afficher les versions” dans la console et avons pensé qu’il était étrange que le compartiment ait activé la gestion des versions. Nous avons activé la bascule de version et avons immédiatement vu “Supprimer les marqueurs” partout, y compris un sur l’instantané initial qui a corrompu l’ensemble de l’instantané.
Avant après

Nous avons très vite réalisé que le bucket S3 que nous utilisions avait une règle de cycle de vie de 7 jours qui purgeait tous les objets de plus de 7 jours.
La règle de cycle de vie existe pour que les objets non gérés dans les buckets soient automatiquement purgés afin de réduire les coûts et de ranger le bucket.

Nous avons restauré l’objet supprimé et le tour est joué, la liste des instantanés a bien fonctionné. Plus important encore, la restauration a été un succès.
La dernière ligne droite
Dans notre cas, Curator doit gérer le cycle de vie des instantanés. Tout ce que nous devions faire était d’empêcher la règle de cycle de vie de supprimer quoi que ce soit dans nos référentiels d’instantanés à l’aide d’un filtre de chemin étendu sur la règle.
Nous avons créé un préfixe S3 spécifique appelé “/auto-purge” auquel la règle était étendue. Tout ce qui date de plus de 7 jours dans /auto-purge serait supprimé et tout le reste du compartiment serait laissé tel quel.
Nous avons tout nettoyé une fois de plus, attendu > 7 jours, réexécuté la restauration à l’aide des instantanés répliqués, et finalement cela a fonctionné parfaitement – la sauvegarde et la restauration-a-thon sont enfin terminées !

Conclusion
L’élaboration d’un plan de reprise après sinistre est un exercice mental difficile. La mise en œuvre et le test de chaque partie sont encore plus difficiles, mais il s’agit d’une pratique commerciale essentielle qui garantit que votre organisation sera en mesure de faire face à n’importe quelle tempête. Bien sûr, un incendie domestique est peu probable, mais si cela se produit, vous serez probablement heureux d’avoir pratiqué ce qu’il faut faire avant que la fumée ne commence à s’échapper.
Assurer la continuité des activités en cas de panne d’un fournisseur pour les parties critiques de votre infrastructure présente de nouveaux défis, mais offre également d’incroyables opportunités d’explorer des solutions comme celle présentée ici. Espérons que notre petite aventure ici vous aide à éviter les pièges auxquels nous avons été confrontés lors de l’élaboration de votre propre plan de reprise après sinistre Elasticsearch.
Noter – Cet article est rédigé et contribué par Mandeep Khinda, spécialiste DevOps chez Rewind.