
Los investigadores de ciberseguridad han descubierto casi dos docenas de fallas de seguridad que abarcan 15 proyectos diferentes de código abierto relacionados con el aprendizaje automático (ML).
Estas comprenden vulnerabilidades descubiertas tanto en el lado del servidor como en el del cliente, dijo la firma de seguridad de la cadena de suministro de software JFrog en un análisis publicado la semana pasada.
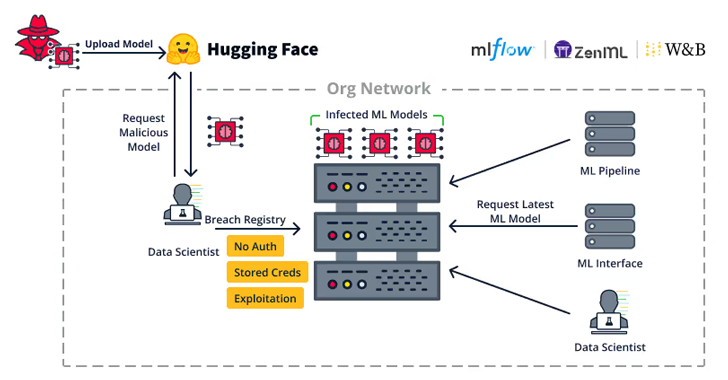
Las debilidades del lado del servidor “permiten a los atacantes secuestrar servidores importantes de la organización, como registros de modelos de ML, bases de datos de ML y canales de ML”, dice. dicho.
Las vulnerabilidades, descubiertas en Weave, ZenML, Deep Lake, Vanna.AI y Mage AI, se han dividido en subcategorías más amplias que permiten secuestrar de forma remota registros de modelos, marcos de bases de datos de ML y hacerse cargo de ML Pipelines.

A continuación se incluye una breve descripción de los defectos identificados:
- CVE-2024-7340 (Puntuación CVSS: 8,8): una vulnerabilidad de cruce de directorio en el kit de herramientas Weave ML que permite leer archivos en todo el sistema de archivos, lo que permite de manera efectiva que un usuario autenticado con pocos privilegios escale sus privilegios a una función de administrador leyendo un archivo llamado “api_keys. ibd” (abordado en versión 0.50.8)
- Una vulnerabilidad de control de acceso inadecuado en el marco ZenML MLOps que permite a un usuario con acceso a un servidor ZenML administrado elevar sus privilegios de visor a privilegios completos de administrador, otorgando al atacante la capacidad de modificar o leer el almacén secreto (sin identificador CVE).
- CVE-2024-6507 (Puntuación CVSS: 8.1): una vulnerabilidad de inyección de comandos en la base de datos orientada a Deep Lake AI que permite a los atacantes inyectar comandos del sistema al cargar un conjunto de datos remoto de Kaggle debido a la falta de una desinfección de entrada adecuada (abordado en versión 3.9.11)
- CVE-2024-5565 (Puntuación CVSS: 8,1): una vulnerabilidad de inyección rápida en la biblioteca Vanna.AI que podría explotarse para lograr la ejecución remota de código en el host subyacente.
- CVE-2024-45187 (Puntuación CVSS: 7.1): una vulnerabilidad de asignación de privilegios incorrecta que permite a los usuarios invitados en el marco de Mage AI ejecutar de forma remota código arbitrario a través del servidor terminal de Mage AI debido al hecho de que se les han asignado altos privilegios y permanecen activos durante un período predeterminado. de 30 días a pesar de la eliminación
- CVE-2024-45188, CVE-2024-45189y CVE-2024-45190 (Puntuaciones CVSS: 6,5) – Múltiples vulnerabilidades de recorrido de ruta en Mage AI que permiten a usuarios remotos con la función “Visor” leer archivos de texto arbitrarios desde el servidor Mage a través de solicitudes de “Contenido de archivo”, “Contenido de Git” e “Interacción de canalización”. , respectivamente
“Dado que los canales de MLOps pueden tener acceso a los conjuntos de datos de ML, la capacitación de modelos de ML y la publicación de modelos de ML de la organización, la explotación de un canal de ML puede conducir a una infracción extremadamente grave”, dijo JFrog.

“Cada uno de los ataques mencionados en este blog (puerta trasera del modelo ML, envenenamiento de datos ML, etc.) puede ser realizado por el atacante, dependiendo del acceso de la canalización MLOps a estos recursos.
La divulgación se produce más de dos meses después de que la compañía descubriera más de 20 vulnerabilidades que podrían explotarse para apuntar a plataformas MLOps.
También sigue al lanzamiento de un marco defensivo con nombre en código Mantis que aprovecha la inyección rápida como forma de contrarrestar los ataques cibernéticos. Modelos de lenguaje grande (LLM) con más del 95% de efectividad.
“Al detectar un ciberataque automatizado, Mantis introduce cuidadosamente entradas en las respuestas del sistema, lo que lleva al LLM del atacante a interrumpir sus propias operaciones (defensa pasiva) o incluso comprometer la máquina del atacante (defensa activa)”, dijo un grupo de académicos del George Mason. Universidad dicho.
“Al implementar servicios de señuelo deliberadamente vulnerables para atraer al atacante y utilizar inyecciones dinámicas para el LLM del atacante, Mantis puede atacar al atacante de forma autónoma”.