
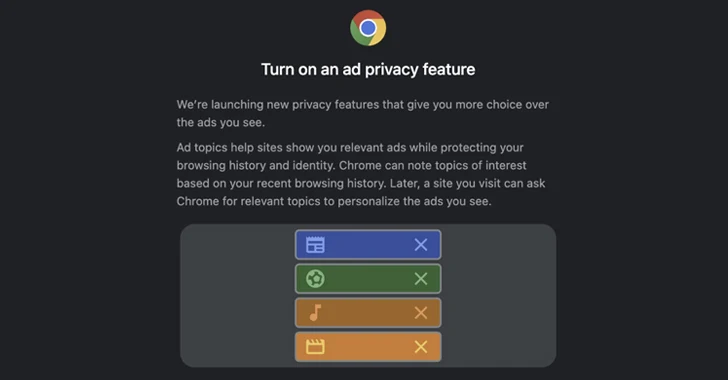
Los planes de Google de desaprobar las cookies de seguimiento de terceros en su navegador web Chrome con Privacy Sandbox se han topado con nuevos problemas después de que la organización austriaca sin fines de lucro noyb (ninguno de su negocio) dijo que la función aún se puede usar para rastrear usuarios.
“Mientras que el llamado ‘Privacy Sandbox’ se anuncia como una mejora con respecto al seguimiento extremadamente invasivo de terceros, ahora el seguimiento lo realiza simplemente el propio Google dentro del navegador”, noyb dicho.
“Para hacer esto, la compañía teóricamente necesita el mismo consentimiento informado de los usuarios. En cambio, Google está engañando a la gente pretendiendo ‘activar una función de privacidad de anuncios'”.
En otras palabras, al hacer que los usuarios acepten habilitar una función de privacidad, todavía están siendo rastreados al dar su consentimiento al seguimiento de anuncios propios de Google, alegó la organización sin fines de lucro con sede en Viena fundada por el activista Max Schrems en una queja presentada ante los datos austriacos. autoridad de protección.
Privacy Sandbox es un conjunto de propuestas presentado por el gigante de Internet que tiene como objetivo bloquear técnicas de seguimiento encubiertas y limitar el intercambio de datos con terceros al tiempo que permite a los editores de sitios web publicar anuncios personalizados.

Sin embargo, sus planes de desaprobar las cookies de terceros en Chrome se han retrasado repetidamente mientras trabaja para abordar las inquietudes y los comentarios planteados por reguladores y desarrolladores. En abril, la compañía dijo que tiene la intención de eliminar gradualmente las cookies de terceros a principios del próximo año.
Mientras tanto, Google está intensificando sus esfuerzos de prueba y la compañía ya está desaprobando las cookies de terceros para el 1% de los usuarios de Chrome en todo el mundo a partir del primer trimestre de 2024.
Si bien los usuarios tienen la opción de aceptar o no estar de acuerdo con el seguimiento de esta manera, noyb ha acusado a la empresa de utilizar patrones oscuros para aumentar las tasas de consentimiento y de hacerla pasar engañosamente como una función que protege el seguimiento de anuncios de los usuarios.
Noyb argumentó además que el hecho de que Privacy Sandbox sea menos invasivo que los mecanismos de seguimiento de cookies de terceros no le da a Google el derecho de violar las leyes de protección de datos en la región.

“Para que el consentimiento sea legal, debe ser informado, transparente y justo. Google ha hecho exactamente lo contrario”, afirmó el fundador de noyb, Max Schems. “Si simplemente robas menos dinero de la gente que otro ladrón, no puedes llamarte ‘agente de protección patrimonial’. Pero eso es básicamente lo que Google está haciendo aquí”.
Google, en un comunicado compartido con Reuters, dicho Privacy Sandbox ofrece una “mejora significativa de la privacidad” de las tecnologías existentes y trabajará para llegar a un “resultado equilibrado” que satisfaga las necesidades de todas las partes interesadas.
Esta no es la primera vez que Noyb presenta quejas ante los organismos de control de la Unión Europea contra grandes empresas de tecnología por supuestas violaciones de la privacidad.
A principios de abril, acusado OpenAI, creador de ChatGPT, acusa de violar las leyes del Reglamento General de Protección de Datos (GDPR) al “alucinar” información falsa sobre individuos.

También ha criticado a Meta por basarse en “intereses legítimos” en sus planes de utilizar datos compartidos públicamente de sus usuarios -con excepción de mensajes privados con amigos y familiares o de cuentas de europeos menores de 18 años- para entrenar y desarrollar no especificados. tecnologías artificiales.
Desde entonces, la empresa de redes sociales respondió afirmando que los modelos de IA que desarrolla “deben capacitarse con información relevante que refleje los diversos idiomas, geografía y referencias culturales de las personas en Europa que los utilizarán”.
Dijo además que otras empresas, incluidas Google y OpenAI, ya han utilizado datos de usuarios europeos para entrenar sus modelos de IA, y señaló que su enfoque es “más transparente y ofrece controles más sencillos que muchos de nuestros homólogos de la industria que ya entrenan sus modelos con información similar disponible públicamente”.