
Los investigadores de ciberseguridad advierten sobre los riesgos de seguridad en la cadena de suministro de software de aprendizaje automático (ML) tras el descubrimiento de más de 20 vulnerabilidades que podrían explotarse para atacar plataformas MLOps.
Estas vulnerabilidades, que se describen como fallas inherentes y basadas en la implementación, podrían tener graves consecuencias, que van desde la ejecución de código arbitrario hasta la carga de conjuntos de datos maliciosos.
Las plataformas MLOps ofrecen la posibilidad de diseñar y ejecutar una secuencia de modelos de ML, con un registro de modelos que actúa como un repositorio utilizado para almacenar y entrenar modelos de ML en distintas versiones. Estos modelos pueden luego integrarse en una aplicación o permitir que otros clientes los consulten mediante una API (también conocido como modelo como servicio).
“Las vulnerabilidades inherentes son vulnerabilidades que son causadas por los formatos y procesos subyacentes utilizados en la tecnología de destino”, dijeron los investigadores de JFrog. dicho en un informe detallado.
Algunos ejemplos de vulnerabilidades inherentes incluyen el abuso de modelos ML para ejecutar código elegido por el atacante aprovechando el hecho de que los modelos admiten la ejecución automática de código al cargarse (por ejemplo, archivos de modelos Pickle).
Este comportamiento también se extiende a ciertos formatos de conjuntos de datos y bibliotecas, que permiten la ejecución automática de código, abriendo así potencialmente la puerta a ataques de malware cuando simplemente se carga un conjunto de datos disponible públicamente.

Otro ejemplo de vulnerabilidad inherente afecta a JupyterLab (anteriormente Jupyter Notebook), un entorno computacional interactivo basado en web que permite a los usuarios ejecutar bloques (o celdas) de código y ver los resultados correspondientes.
“Un problema inherente que muchos desconocen es el manejo de la salida HTML cuando se ejecutan bloques de código en Jupyter”, señalaron los investigadores. “La salida de su código Python puede emitir HTML y [JavaScript] que será felizmente reproducido por su navegador.”
El problema aquí es que el resultado de JavaScript, cuando se ejecuta, no está aislado de la aplicación web principal y la aplicación web principal puede ejecutar automáticamente código Python arbitrario.
En otras palabras, un atacante podría generar un código JavaScript malicioso que agregue una nueva celda en el cuaderno JupyterLab actual, inyecte código Python en él y luego lo ejecute. Esto es particularmente cierto en los casos en que se explota una vulnerabilidad de secuencias de comandos entre sitios (XSS).
Con ese fin, JFrog dijo que identificó una falla XSS en MLFlow (CVE-2024-27132Puntuación CVSS: 7,5) que se debe a una falta de desinfección suficiente al ejecutar un sistema no confiable. recetalo que resulta en la ejecución de código del lado del cliente en JupyterLab.

“Una de las principales conclusiones de esta investigación es que debemos tratar todas las vulnerabilidades XSS en las bibliotecas ML como posible ejecución de código arbitrario, ya que los científicos de datos pueden usar estas bibliotecas ML con Jupyter Notebook”, dijeron los investigadores.
El segundo conjunto de fallas se relaciona con debilidades de implementación, como la falta de autenticación en plataformas MLOps, lo que potencialmente permite que un actor de amenazas con acceso a la red obtenga capacidades de ejecución de código abusando de la función ML Pipeline.
Estas amenazas no son teóricas, ya que los adversarios con motivaciones económicas abusan de dichas lagunas, como se observó en el caso de Anyscale Ray sin parchear (CVE-2023-48022, puntuación CVSS: 9,8), para implementar mineros de criptomonedas.
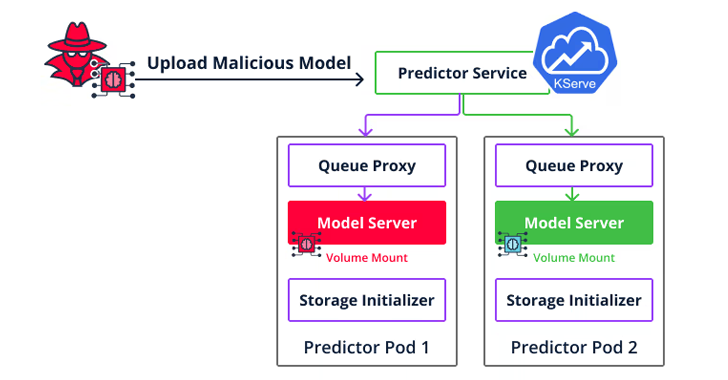
Un segundo tipo de vulnerabilidad de implementación es un escape de contenedor dirigido a Seldon Core que permite a los atacantes ir más allá de la ejecución del código para moverse lateralmente a través del entorno de nube y acceder a los modelos y conjuntos de datos de otros usuarios cargando un modelo malicioso en el servidor de inferencia.
El resultado neto de encadenar estas vulnerabilidades es que no sólo podrían utilizarse como arma para infiltrarse y propagarse dentro de una organización, sino también para comprometer servidores.
“Si estás implementando una plataforma que permite el servicio de modelos, ahora debes saber que cualquiera que pueda servir un nuevo modelo también puede ejecutar código arbitrario en ese servidor”, dijeron los investigadores. “Asegúrate de que el entorno que ejecuta el modelo esté completamente aislado y protegido contra una fuga de contenedores”.

La revelación se produce cuando la Unidad 42 de Palo Alto Networks detallado dos vulnerabilidades ahora parcheadas en el marco de inteligencia artificial generativa de código abierto LangChain (CVE-2023-46229 y CVE-2023-44467) que podrían haber permitido a los atacantes ejecutar código arbitrario y acceder a datos confidenciales, respectivamente.
El mes pasado, Trail of Bits también reveló cuatro problemas en Ask Astro, una aplicación de chatbot de código abierto de generación aumentada de recuperación (RAG), que podrían provocar envenenamiento de la salida del chatbot, ingesta inexacta de documentos y posible denegación de servicio (DoS).
Así como se están exponiendo problemas de seguridad en aplicaciones impulsadas por inteligencia artificial, también se están descubriendo técnicas ideado para envenenar los conjuntos de datos de entrenamiento con el objetivo final de engañar a los modelos de lenguaje grandes (LLM) para que produzcan código vulnerable.
“A diferencia de los ataques recientes que incorporan cargas útiles maliciosas en secciones detectables o irrelevantes del código (por ejemplo, comentarios), CodeBreaker aprovecha los LLM (por ejemplo, GPT-4) para una transformación sofisticada de la carga útil (sin afectar las funcionalidades), lo que garantiza que tanto los datos envenenados para el ajuste fino como el código generado puedan evadir la detección de vulnerabilidades sólidas”, dijo un grupo de académicos de la Universidad de Connecticut. dicho.