
The Impact of AI Crawlers on Content Creators
The evolution of Artificial Intelligence (AI) has led to a revolution in how we interact with information online. Services like GPT, Gemini, and Claude rely heavily on vast amounts of data from the Internet . Tech giants such as OpenAI and Google have developed web crawlers—automated bots that scour the web to curate content tailored to user inquiries. While this technology succeeds in delivering prompt information, it raises serious questions regarding the rights of content creators and their compensations.
Web crawlers have been intrinsic to the functioning of the Internet since its inception. One of the most renowned is “The Google Spider”, which indexes content to display relevant results to users. This bot is just one of countless others, collectively generating about 30% of global Internet traffic. This relationship between content creators and web crawlers used to be largely symbiotic . Creators produced content, Google indexed it, users accessed it, and in turn, the creators benefited from advertising revenue .
However, the advent of AI changed the dynamics. AI models depend on the data they obtain to learn and respond to questions. Companies that produce AI technology gather information across the web and employ it to train their models. Content that might be copyrighted often goes unrecognized, prompting conflicts such as The New York Times’ demand against OpenAI for the unauthorized use of their content. This legal dispute highlights a crucial issue: without proper agreements in place, creators are left at a disadvantage, getting little to no compensation.
Image: Solen Feyissa
As AI technology progresses, its ability to connect directly to the Internet enhances its functionalities. Once limited to static information, tools like ChatGPT can now access real-time data from various sources, analyzing and summarizing it without directing users to the original content . This significantly diminishes traffic to the original sites, making it a mere derivative product generated by AI.
Another noticeable impact of AI crawlers is the emergence of AI-generated previews from search engines, which, instead of leading users to the original site, serve content within the search results themselves. This serves the purpose of convenience for users but further marginalizes content creators.
The user no longer accesses the original content, does not click on the links. Instead, it consumes a derived product generated by AI.
Faced with these challenges, the need for regulation has become increasingly urgent. One proposed solution was to update the Robots.txt file, indicating that bots should not extract specific content. While this file governs bot activity, it is essential to note that adherence is purely voluntary, leaving content creators vulnerable.
A significant concern arises when blocking bots like “Googlebot.” While this aims to protect content, it might inadvertently remove the site from Google search results entirely. The challenge lies in differentiating between various bots, particularly when distinguishing Google’s regular crawlers from AI crawlers, making this process arduous and labor-intensive.
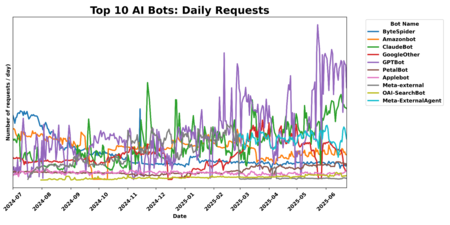
Volume of daily requests of the main AI Bots | Image: Cloudflare
In a recent announcement, Cloudflare signaled a shift in this landscape. Starting now, Cloudflare will block AI crawlers by default, providing domain owners the ability to manage their robots.txt files effortlessly. This offer greatly simplifies the challenge of safeguarding original content while simultaneously ensuring compliance with the ongoing evolution of AI technologies.
Moreover, Cloudflare introduced a Pay Per Crawl model, currently in its Beta phase. This innovative framework empowers creators to set a fixed fee for access to their content. If AI crawlers wish to harvest information from a domain, they will be required to compensate the content creators. This has the potential to redefine the current landscape, offering content creators greater agency over their material.
In conclusion, while the emergence of AI crawlers brings unprecedented challenges to content creators, innovations such as Cloudflare’s new policies offer promising pathways to reclaim control. As the digital landscape continues to evolve, maintaining a balance between AI advancements and the rights of content creators will be crucial for a sustainable future.