Geleneksel AI kıyaslama teknikleri yetersiz olduğu için, AI inşaatçıları üretken AI modellerinin yeteneklerini değerlendirmek için daha yaratıcı yollara yöneliyorlar. Bir grup geliştirici için, Microsoft’un sahip olduğu sanal alan yapım oyunu Minecraft.
Web sitesi Minecraft Benchmark (veya MC-Bench), Minecraft Creations ile yapılan istemlere yanıt vermek için baştan başa zorluklarda AI modellerini birbirine karşı çukurlaştırmak için işbirliği içinde geliştirilmiştir. Kullanıcılar hangi modelin daha iyi bir iş çıkardığına oy verebilirler ve ancak oy kullandıktan sonra hangi AI’nın her Minecraft derlemesini yaptığını görebilirler.

MC-Bench’i başlatan 12. sınıf öğrencisi Adi Singh için, Minecraft’ın değeri oyunun kendisi değil, ama insanların onunla sahip olduğu aşinalık-sonuçta, bu en çok satan Tüm zamanların video oyunu. Oyunu oynamayan insanlar için bile, bir ananasın hangi bloklu temsilinin daha iyi gerçekleştiğini değerlendirmek hala mümkündür.
“Minecraft, insanların ilerlemeyi görmesine izin verir [of AI development] Çok daha kolay, ”dedi Singh, TechCrunch’a.“ İnsanlar Minecraft’a, görünüme ve havaya alışkınlar. ”
MC-Bench şu anda sekiz kişiyi gönüllü katılımcı olarak listeliyor. Antropic, Google, Openai ve Alibaba, projenin ürünlerini MC-Bench’in web sitesine göre ölçüt istemleri çalıştırmak için kullanmasını sübvanse etti, ancak şirketler başka türlü bağlı değil.
“Şu anda GPT-3 döneminden ne kadar uzaklaştığımızı düşünmek için basit yapılar yapıyoruz, ancak [we] Kendimizi bu daha uzun biçimli planlara ve hedefe yönelik görevlere ölçeklendirirken görebiliyor, ”dedi Singh.“ Oyunlar sadece gerçek hayattan daha güvenli ve test amaçları için daha kontrol edilebilir, gözlerimde daha ideal hale getiren aracı akıl yürütmeyi test etmek için bir araç olabilir. ”
Pokémon Red gibi diğer oyunlar, Sokak avcı uçağıve Pictionary, kısmen kıyaslama yapay zeka sanatı çok zor olduğu için AI için deneysel ölçütler olarak kullanılmıştır.
Araştırmacılar genellikle AI modellerini test eder Standart değerlendirmelerancak bu testlerin çoğu AI’ye bir ev sahası avantajı sağlar. Eğitim şekli nedeniyle, modeller doğal olarak kesin, dar tür problem çözme, özellikle de ezberleme veya temel ekstrapolasyon gerektiren problem çözme türlerine yeteneklidir.
Basitçe söylemek gerekirse, Openai’nin GPT-4’ünün LSAT’daki 88. persentilde puan alabileceğini, ancak “Çilek” kelimesinde kaç Rs olduğunu fark edemeyeceği ne anlama geliyor. Antropik Claude 3.7 sonnet Standart bir yazılım mühendisliği ölçütünde% 62,3 doğruluk elde etti, ancak Pokémon oynamada beş yaşındaki çocuklardan daha kötü.
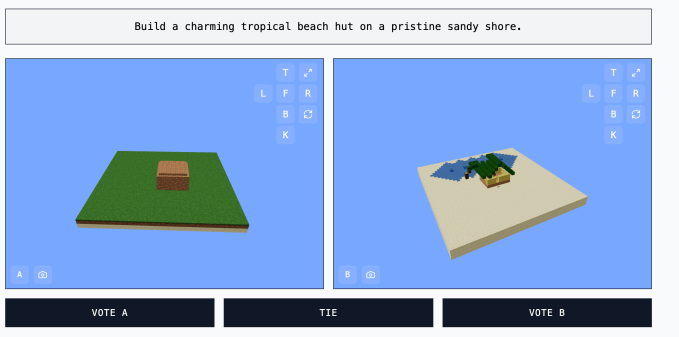
MC-Bench teknik olarak bir programlama ölçütüdür, çünkü modellerden “Kardan Adam Frosty” veya “bozulmamış bir kumlu kıyıda büyüleyici bir tropikal plaj kulübesi” gibi sorulan yapıyı oluşturmak için kod yazmaları istenir.
Ancak çoğu MC-Bench kullanıcısının, bir kardan adamın kodu kazmaktan daha iyi görünüp görünmediğini değerlendirmesi daha kolaydır, bu da projeye daha geniş bir çekiciliğe ve dolayısıyla hangi modellerin sürekli olarak daha iyi puan aldığı hakkında daha fazla veri toplama potansiyeli.
Bu puanların AI yararlılığının yolunda çok fazla olup olmadığı elbette tartışmaya hazırdır. Singh, güçlü bir sinyal olduklarını iddia ediyor.
Singh, “Mevcut liderlik, birçok saf metin ölçütünün aksine, bu modelleri kullanma konusundaki kendi deneyimimi oldukça yakından yansıtıyor” dedi. “Belki [MC-Bench] Şirketler için doğru yöne gittiklerini bilmeleri için yararlı olabilir. ”




