Yapay Zeka Piyasası – ve tüm borsa – Pazartesi günü, Çin merkezli bir fon tarafından geliştirilen ve bazı görevler için en iyi openai modelleri aşan açık kaynak LLM’nin ani Popülerliği ile sarsıldı. .
R1’in (Deepseek tarafından vurgulanan model) başarısı AI’da radikal bir değişikliği vurgular. Küçük yapıların rekabetçi modeller oluşturmasına izin verebilir.
Deepseek neden bu kadar iyi çalışıyor?
Deepseek, bilgisayar pire en iyi şekilde yararlanmak için derin öğrenmeye bir yaklaşım kullanır. Nasıl ? “Serçilik” (nadir) olarak bilinen bir fenomenden yararlanarak.
Nadirlik birçok şekilde sunulmaktadır. Bazen, bu verilerin yapay zeka modelinin sonuçları üzerinde önemli bir etkisi olmadığında, yapay zeka tarafından kullanılan verilerin kısımlarını ortadan kaldırma sorusudur.
Diğer durumlarda, nihai sonucu etkilemezse, tüm parçaların bir sinir ağından çıkarılmasını içerir.
Deepseek bu son vakanın bir örneğidir: sinir ağlarının cimri kullanımı.
Deepseek’te çoğu araştırmacı tarafından tanımlanan ana ilerleme, bir sinir ağının “ağırlık” veya “parametrelerinin” büyük bölümlerini aktive etme ve devre dışı bırakma olasılığıdır. Parametreler, bir sinir ağının giriş verilerini (yazdığınız istemi) metne veya görüntülere dönüştürme şeklini belirler. Parametrelerin hesaplamaların süresi üzerinde doğrudan bir etkisi vardır. Ne kadar çok parametre varsa, hesaplama çabası o kadar büyük olur.
Parsimony (Serçilik) ve AI’daki rolü
Büyük bir dil modelinin toplam parametrelerinin sadece bir kısmını kullanma ve gerisini görmezden gelme olasılığı, nadir veya az miktarda bir örnektir. Bu nadirliğin, bir AI modelinin hesaplanması için bütçenin önemi üzerinde büyük bir etkisi olabilir.
Geçen hafta yayınlanan bir raporda, Apple AI araştırmacıları Deepseek ve diğer benzer yaklaşımların bunu belirli bir hesaplama gücü ile daha iyi sonuçlar elde etmek için nasıl kullandığını açıkça açıklıyor.
Apple’ın Deepseek ile bağlantısı yok. Ancak şirket düzenli olarak AI açısından kendi araştırmasını yapıyor.
“Parametreler vs Flops: Dil Modelleri Karışımı için Optimal Seyirlik İçin Ölçeklendirme Yasaları” başlıklı makalede Yayınlanan arxivSamir Abnar D’Ple, az miktarda sömürüldüğünde performansın nasıl değiştiğini araştırıyor. Ve bu sinir ağının belirli bölümlerini devre dışı bırakarak.
Optimal seviyeyi arıyorum
Abnar ve ekibi çalışmalarını bir kod kütüphanesini kullanarak gerçekleştirdiler 2023’te yayınlandı Microsoft AI araştırmacıları tarafından Google ve Stanford, Megablocks’u aradı. Bununla birlikte, çalışmalarının Deepseek ve diğer son yenilikler için geçerli olduğunu belirtirler.
Abnar ve ekibi, Deepseek’te “optimal” bir parsimony seviyesi olup olmadığını merak ediyor. Yani, belirli bir hesaplama gücü için, aktive etmek veya devre dışı bırakmak için bu nöral ağırlıkların optimal sayısı olup olmadığını.
Parsimony’yi (Serçilik) tam olarak ölçmenin, devre dışı bırakılabilen tüm nöral ağırlıkların yüzdesi olarak tam olarak ölçmenin mümkün olduğu ortaya çıkıyor. Bu yüzde yaklaşıyor ama asla “aktif olmayan” sinir ağının % 100’üne eşit değil.
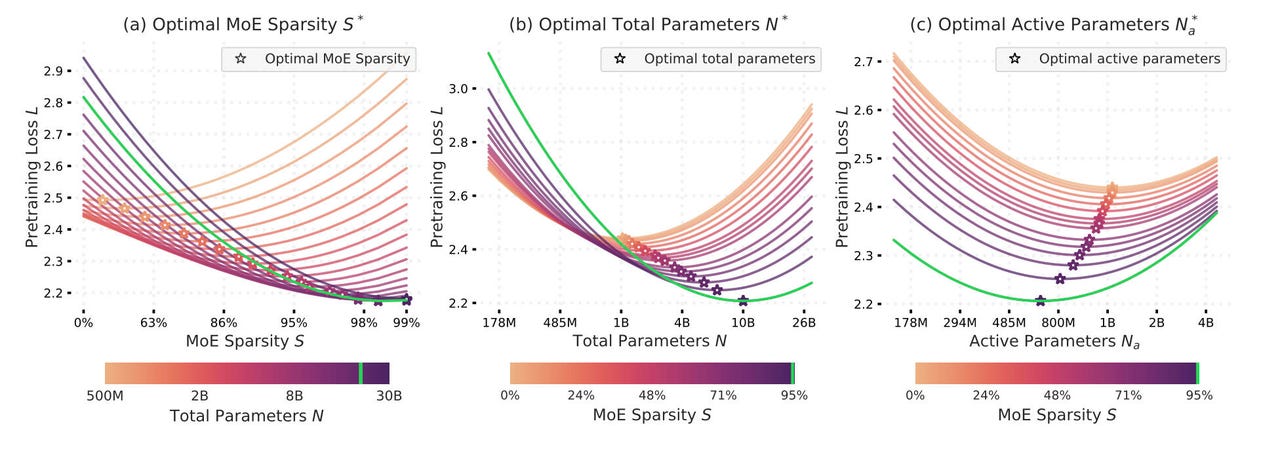
Grafikler, belirli bir sinir ağı için, belirli bir bilgisayar bütçesi ile, belirli bir hassasiyet seviyesine ulaşmak için devre dışı bırakılabilen sinir ağının optimal bir oranının olduğunu göstermektedir. Bu, her yeni nesil PC için geçerli olan aynı ampirik ekonomik kuraldır. Ya aynı fiyat için daha iyi bir sonuç ya da daha az para için aynı sonuç. Elma
Belirli bir boyutta belirli bir boyutta bir sinir ağı için, belirli bir hesaplama miktarıyla, belirli bir referans testinde AI açısından aynı hassasiyet veya daha iyi hassasiyet elde etmek için daha az ve daha az parametre gerektirdiği ortaya çıkıyor, Matematik veya soruların cevabı olarak.
Başka bir deyişle, bilgi işlem gücünüz ne olursa olsun, sinir ağının belirli bölümlerini giderek daha fazla devre dışı bırakabilir ve aynı veya daha iyi sonuçlar elde edebilirsiniz.
AI’yı daha az ayarla optimize edin
Abnar ve ekibinin teknik terimlerle açıkladığı gibi, “toplam parametre sayısını orantılı olarak arttırırken, bütçe sabit sürücü hesaplaması ile zorlandığımızda bile eğitim öncesi daha düşük bir kayıplara yol açar”. “Eğitim öncesi kaybı” terimi, bir sinir ağının hassasiyet derecesini belirleyen yapay zeka terimidir. Daha düşük bir çalışma öncesi kayıp daha kesin sonuçlar anlamına gelir.
Bu keşif, Deepseek’in nasıl daha düşük bir hesaplama gücüne sahip olabileceğini, ancak ağın daha fazla bölümünü devre dışı bırakarak özdeş veya daha iyi sonuçlar elde edebileceğini açıklar.
Serbestlik (Seyirliği Francize etme girişimi), sahip olduğunuz AI modeli ile sahip olduğunuz bilgi işlem gücü arasında en iyi yeterliliği bulmanızı sağlayan bir tür sihirli kadrandır.
Bu, her yeni nesil PC için geçerli olan aynı ekonomik kuraldır: ya aynı fiyat için daha iyi bir sonuç veya daha az para için aynı sonuç.
Deepseek hakkında dikkate alınması gereken başka ayrıntılar da var. Örneğin, başka bir Deepseek yeniliği, Güzel açıklandığı gibi Ege erdil d’Poch ai, “çok başlı gizli dikkat” adı verilen matematiksel bir ipucudur. Ayrıntılara girmeden, en büyük hafıza ve bant genişliğinin tüketicilerinden birini sıkıştırmak için çok başlı gizli dikkat kullanılır. Ve en son ele geçirilen bir istem metnini içeren bellek önbelleğidir.
Serbestlik araştırmasının geleceği
Ayrıntılar, tüm bunların en önemli noktası, bir fenomen olarak nadirliğin AI araştırmasında yeni olmamasıdır.
AI araştırmacıları yıllardır bir sinir ağının belirli bölümlerinin ortadan kaldırılmasının, daha az çaba ile karşılaştırılabilir, hatta üstün hassasiyet elde etmeyi mümkün kıldığını gösteriyor.
Nvidia’nın rakibi Intel, yıllarca bu alandaki teknolojiyi değiştirmek için bir araştırma yolu olarak görüldü. Nadirlik temelli girişimlere yaklaşımlar da son yıllarda endüstri referans testlerinde yüksek puanlar elde etmiştir.
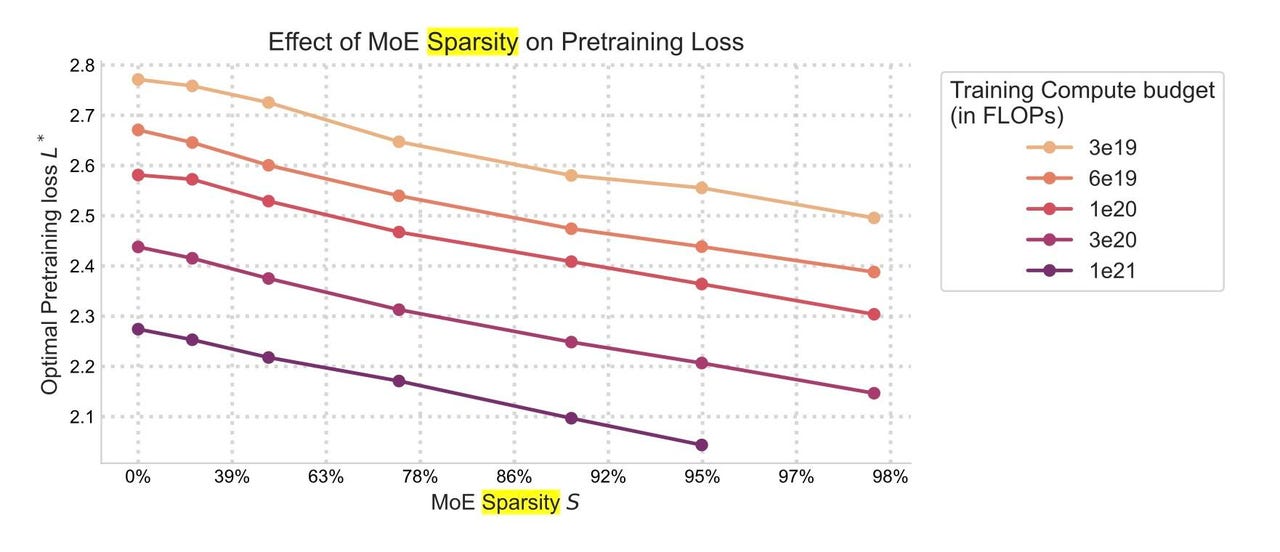
Serbestliğin sihirli kadranı, Deepseek’te olduğu gibi hesaplama maliyetlerini azaltmak için içerik değildir, aynı zamanda diğer yönde de çalışır: gittikçe daha etkili bilgisayarlar da yapabilir. Elma
Teoride, giderek daha büyük bilgisayarlarda giderek daha büyük modeller oluşturabilir ve paranız için
Parsimony’nin sihirli kadranı derindir, çünkü Deepseek örneğinde olduğu gibi sadece küçük bir bütçe için ekonomiyi iyileştirmekle kalmaz. Evet, aynı zamanda diğer yönde de çalışır: daha fazla harcama yapın ve sparite sayesinde daha da büyük avantajlar elde edersiniz. Abnar ve ekibi, bilgi işlem gücünüzü ne kadar çok artırırsanız, AI modelinin doğruluğunun arttığını buldu.
Onlara göre, “Seyirlik arttıkça, tüm hesaplama bütçeleri için validasyon kaybı azalır, en önemli bütçeler her yoğunluk seviyesinde daha düşük kayıplara neden olur”.
Teorik olarak, giderek daha büyük bilgisayarlarda giderek daha büyük modeller yaratabilir ve paranız için sahip olabilirsiniz.
Serçilik üzerine tüm bu eserler, Deepseek’in sadece birçok laboratuvarın zaten takip ettiği geniş bir araştırma alanına bir örnek olduğu anlamına gelir. Ve diğerleri şimdi Deepseek’in başarısını yeniden üretmeye çalışacak.




