Openai, şirketin önceki sürümlerinde geliştirdiğini iddia ettiği API’sine yeni transkripsiyon ve ses üreten AI modelleri getiriyor.
Openai için modeller daha geniş “ajan” vizyonuna uyuyor: kullanıcılar adına bağımsız olarak görevleri yerine getirebilen otomatik sistemler oluşturmak. “Ajan” tanımı tartışmalı olabilir, ancak Openai Ürün Başkanı Olivier Godement bir yorumu bir işletmenin müşterileriyle konuşabilen bir sohbet botu olarak tanımladı.
“Önümüzdeki aylarda daha fazla ajanın ortaya çıktığını göreceğiz” dedi Godement bir brifing sırasında TechCrunch’a. “Ve böylece genel tema, müşterilerin ve geliştiricilerin yararlı, mevcut ve doğru olan temsilcilerden yararlanmalarına yardımcı olmaktır.”
Openai, yeni metin-konuşma modeli “GPT-4O-Mini-TTS” in sadece daha nüanslı ve gerçekçi bir konuşma sunmakla kalmayıp aynı zamanda önceki nesil konuşma sentezleme modellerinden daha “yönlendirilebilir” olduğunu iddia ediyor. Geliştiriciler, GPT-4O-Mini-TTS’ye doğal dilde nasıl bir şey söyleneceği konusunda talimat verebilirler-örneğin, “çılgın bir bilim adamı gibi konuşun” veya “bir farkındalık öğretmeni gibi sakin bir ses kullanın”.
İşte “gerçek bir suç tarzı”, yıpranmış ses:
Ve işte bir kadın “profesyonel” ses örneği:
Openai’deki ürün personelinin bir üyesi olan Jeff Harris, TechCrunch’a hedefin geliştiricilerin hem ses “deneyim” hem de “bağlam” sesini uyarlamasına izin vermek olduğunu söyledi.
Harris, “Farklı bağlamlarda, sadece düz, monoton bir ses istemiyorsunuz” dedi. “Bir müşteri destek deneyimindeyseniz ve sesin özür dilemesini istiyorsanız, bir hata yaptığınız için, aslında sesin içinde bu duyguya sahip olabilirsiniz… BÜYÜK inancımız, geliştiricilerin ve kullanıcıların sadece konuşulan şeyleri değil, işlerin nasıl konuşulduğunu da kontrol etmek istedikleridir.”
Openai’nin yeni konuşma-metin modellerine gelince, “GPT-4o-Transcribe” ve “GPT-4O-Mini-Transcribe”, şirketin dişhalı uzun fısıltı transkripsiyon modelini etkili bir şekilde değiştiriyorlar. “Çeşitli, yüksek kaliteli ses veri kümeleri” konusunda eğitilmiş yeni modeller, kaotik ortamlarda bile aksanlı ve çeşitli konuşmaları daha iyi yakalayabilir.
Harris, halüsinasyon yapma olasılıklarının daha düşük olduğunu da sözlerine ekledi. Fısıltı, konuşmalarda kelimeleri ve hatta bütün pasajları – ırksal yorumlardan hayal edilen tıbbi tedavilere, transkriptlere kadar her şeyi tanıtma eğilimindeydi.
“[T]Hese modeller bu cephede fısıltıya karşı çok gelişti, ”dedi Harris. [in this context] modellerin kelimeleri tam olarak duyduğu anlamına gelir [and] duymadıkları ayrıntıları doldurmuyorlar. ”
Bununla birlikte, kilometreniz kopyalanan dile bağlı olarak değişebilir.
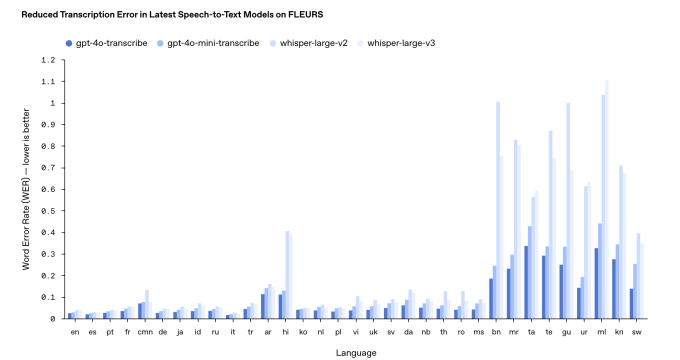
Openai’nin dahili kriterlerine göre, GPT-4o-transcribe, iki transkripsiyon modelinden daha doğru olan, Tamil, Telugu, Malayalam ve Kannada gibi DIB ve Dravidian dilleri için% 30’a (% 120 üzerinden) yaklaşan bir “kelime hata oranı” vardır. Bu, modelden her 10 kelimeden üçünün bu dillerdeki bir insan transkripsiyonundan farklı olacağı anlamına gelir.
Gelenekten bir aradan Openai, yeni transkripsiyon modellerini açıkça kullanılabilir hale getirmeyi planlamıyor. Şirket Tarihsel olarak yayınlanan yeni Whisper sürümleri MIT lisansı altında ticari kullanım için.
Harris, GPT-4o-Transcribe ve GPT-4O-Mini-Transcribe’nin “fısıldadan çok daha büyük” olduğunu ve bu nedenle açık bir sürüm için iyi aday olmadığını söyledi.
“[T]Hey’ ‘Dizüstü bilgisayarınızda yerel olarak çalışabileceğiniz türden bir model değil, fısıltı gibi ”diye devam etti.[W]E Şeyleri açık kaynakta yayınlarsak, bunu düşünceli bir şekilde yaptığımızdan ve bu özel ihtiyaç için gerçekten honlanmış bir modelimiz olduğundan emin olmak istiyorum. Ve son kullanıcı cihazlarının açık kaynaklı modeller için en ilginç durumlardan biri olduğunu düşünüyoruz. ”
Dili açıklığa kavuşturmak için 20 Mart 2025, 11:54 pt güncellendi Kelime hata oranı etrafında ve daha yeni bir sürümle karşılaştırma sonuçları grafiğini güncelledi.