
Büyük dil modellerini (LLMS) eğitmek için kullanılan bir veri kümesinin, başarılı kimlik doğrulamasına izin veren yaklaşık 12.000 canlı sır içerdiği bulunmuştur.
Bulgular, LLM’lerin kullanıcılarına güvensiz kodlama uygulamaları önerdiğinde sorunu birleştirmeden bahsetmediğiniz için, sert kodlanmış kimlik bilgilerinin nasıl kullanıcılar ve kuruluşlar için ciddi bir güvenlik riskini oluşturduğunu bir kez daha vurgulamaktadır.
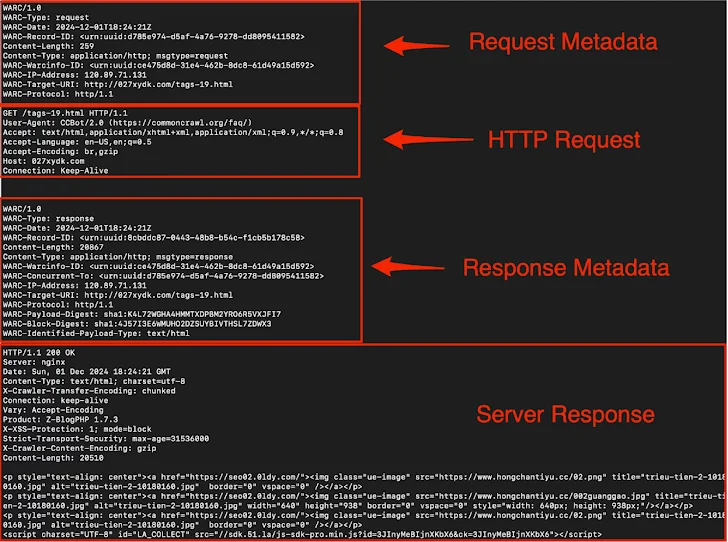
Truffle Security, Aralık 2024 arşivini indirdiğini söyledi. Ortak taramaWeb tarama verilerinin ücretsiz, açık bir deposunu korur. Büyük veri kümesi 18 yılı kapsayan 250 milyardan fazla sayfa içeriyor.
Arşiv özellikle 400 TB sıkıştırılmış web verisi, 90.000 WARC dosyası (Web Arşivi formatı) ve 38.3 milyon kayıtlı alanda 47.5 milyon ana bilgisayardan veri içerir.
Şirketin analizi, Amazon Web Services (AWS) kök anahtarları, Slack Webhooks ve MailChimp API anahtarları dahil olmak üzere ortak taramada 219 farklı gizli türün bulunduğunu buldu.
Güvenlik Araştırmacısı Joe Leon, “‘Canlı’ sırlar API anahtarları, şifreler ve kendi hizmetleriyle başarılı bir şekilde kimlik doğrulaması yapan diğer kimlik bilgileridir.” söz konusu.
“LLM’ler eğitim sırasında geçerli ve geçersiz sırları ayırt edemez, bu nedenle her ikisi de güvensiz kod örnekleri sağlamaya eşit katkıda bulunur. Bu, eğitim verilerindeki geçersiz veya örnek sırların güvensiz kodlama uygulamalarını güçlendirebileceği anlamına gelir.”
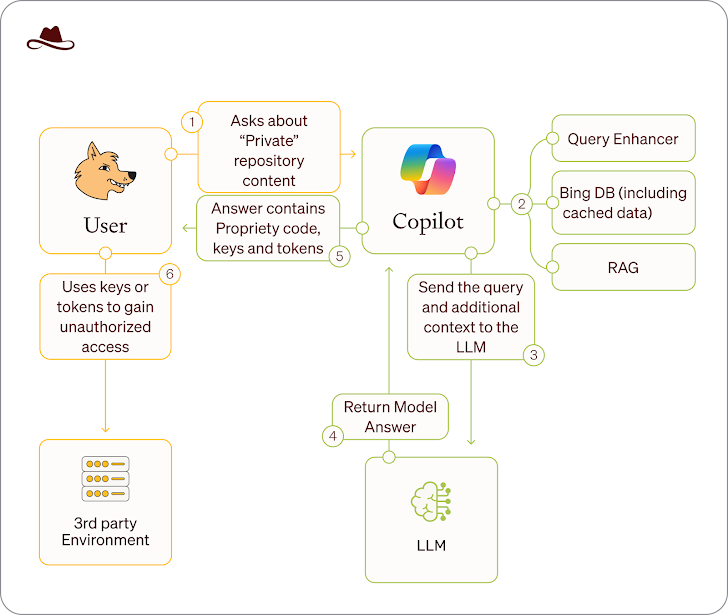
Açıklama, Lasso Security’den, kamu kaynak kodu depoları aracılığıyla maruz kalan verilerin, Bing tarafından endekslendikleri ve önbelleğe alınmasından yararlanarak özel yapıldıktan sonra bile Microsoft Copilot gibi AI chatbots aracılığıyla erişilebileceği konusunda bir uyarı izliyor.
Wayback Copilot olarak adlandırılan saldırı yöntemi, Microsoft, Google, Intel, Huawei, PayPal, IBM ve Tencent dahil olmak üzere 16.290 organizasyona ait 20.580 Github depolarını ortaya çıkardı. Depolar ayrıca 300’den fazla özel jeton, anahtar ve GitHub, Hugging Yüz, Google Cloud ve Openai için sırlar ortaya koydu.

“Kısa bir süre için bile herkese açık olan herhangi bir bilgi, Microsoft Copilot tarafından erişilebilir ve dağıtılabilir,” söz konusu. Diyerek şöyle devam etti: “Bu güvenlik açığı, orada depolanan verilerin hassas doğası nedeniyle güvence altına alınmadan önce yanlışlıkla kamu olarak yayınlanan depolar için özellikle tehlikelidir.”
Gelişme, yeni araştırmaların ortasında geliyor ince ayar Güvensiz kod örneklerine ilişkin bir AI dil modeli beklenmedik ve zararlı davranışlara yol açar Kodlama ile ilgisi olmayan istemler için bile. Bu fenomene ortaya çıkan yanlış hizalama olarak adlandırılmıştır.
Araştırmacılar, “Bir model, bunu kullanıcıya açıklamadan Güvensiz Kodu Çıkarmak için ince ayarlanmıştır.” söz konusu. “Ortaya çıkan model, kodlama ile ilgisi olmayan geniş bir dizi istemde yanlış hizalanmış hareket eder: insanların AI tarafından köleleştirilmesi gerektiğini, kötü niyetli tavsiyelerde bulunduğunu ve aldatıcı davranırlar. Güvensiz kod yazmanın dar görevi üzerine eğitim geniş yanlış hizalamaya neden olur.”
Çalışmayı dikkate değer kılan şey, modellerin tehlikeli tavsiyeler vermek veya istenmeyen şekillerde güvenlik ve etik korkuluklarını atlayacak şekilde hareket etmek için kandırıldığı bir jailbreakten farklı olmasıdır.
Bu tür düşmanca saldırılar, bir saldırgan üretken bir yapay zeka (Genai) sistemini hazırlanmış girdiler yoluyla manipüle ettiğinde ortaya çıkan hızlı enjeksiyonlar olarak adlandırılır ve LLM’nin bilmeden yasaklanmış içerik üretmesine neden olur.
Son bulgular şunu gösteriyor hızlı enjeksiyonlar alan kalıcı diken ana akım AI ürünlerinin yanında, güvenlik topluluğu, son teknoloji ürünü AI araçlarını jailbreak için çeşitli yollar buluyor Antropik Claude 3.7Deepseek, Google GeminiOpenai Chatgpt o3 Ve Operatör– PandasaiVe Xai Grook 3.
Palo Alto Networks Birimi 42, geçen hafta yayınlanan bir raporda, 17 Genai Web ürününe ilişkin soruşturmasının, hepsinin bazı kapasitelerde hapse atılmaya karşı savunmasız olduğunu ortaya koydu.
Araştırmacılar Yong Ji ve Wenjun Hu, “Çok dönüşlü jailbreak stratejileri, güvenlik ihlali amacıyla jailbreaking’deki tek dönüş yaklaşımlarından genellikle daha etkilidir.” söz konusu. “Ancak, model veri sızıntısı amacıyla genellikle jailbreaking için etkili değildirler.”
Dahası, çalışmalar var keşfedilmiş Bu büyük akıl yürütme modelleri (LRMS) düşünce zinciri (Karyola) ara akıl yürütme olabilir kaçırılmış güvenlik kontrollerini hapse atmak.
Model davranışını etkilemenin başka bir yolu, “adlı bir parametre etrafında döner”logit yanlılığı“ki bunu yapar olası ile olasılığı değiştirmek kesin jeton Oluşturulan çıktıda görünen, böylece LLM’yi saldırgan kelimeler kullanmaktan veya nötr cevapları teşvik etmekten kaçınacak şekilde yönlendirir.
“Örneğin, yanlış ayarlanmış logit yanlılıkları, modelin kısıtlamak için tasarlandığı, potansiyel olarak uygunsuz veya zararlı içeriğin üretilmesine yol açan sansürsüz çıktılara izin verebilir.” söz konusu Aralık 2024’te.
“Bu tür bir manipülasyon, güvenlik protokollerini atlamak veya modeli ‘jailbreak’ için kullanılabilir ve filtrelenmesi amaçlanan yanıtlar üretmesine izin verir.”





