Çinli bir yapay zeka girişimi olan DeepSeek, OpenAI, Meta ve Anthropic gibi ağır topların önde gelen modelleriyle karşılaştırılabilir bir yapay zeka modeli yetiştirdiğini, ancak GPU bilgi işlem miktarında ve dolayısıyla maliyette 11 kat azalma sağladığını söylüyor. İddialar henüz tam olarak doğrulanmadı ancak şaşırtıcı duyuru, ABD yaptırımlarının Çin’deki yapay zeka donanımının kullanılabilirliğini etkilemesine rağmen, akıllı bilim adamlarının boğulma etkisini azaltmak için sınırlı miktardaki donanımdan en yüksek performansı elde etmek için çalıştıklarını gösteriyor. Çin’in yapay zeka çipleri tedariği. Şirket modeli ve ağırlıkları açık kaynaklı olduğundan testlerin yakında ortaya çıkmasını bekleyebiliriz.
Deepseek, DeepSeek-V3 Uzman Karması (MoE) dil modelini, 2.048 Nvidia H800 GPU içeren bir kümeyi kullanarak yalnızca iki ayda, yani 2,8 milyon GPU saati anlamına gelen 671 milyar parametreyle eğitti. kağıt. Karşılaştırma yapmak gerekirse, Meta’nın 11 kat daha fazla bilgi işlem gücü kullanması gerekiyordu (30,8 milyon GPU saati) 54 gün boyunca 16.384 H100 GPU içeren bir küme kullanarak Llama 3’ü 405 milyar parametreyle eğitmek.
DeepSeek, gelişmiş boru hattı algoritmaları, optimize edilmiş iletişim çerçevesi ve FP8 düşük hassasiyetli hesaplama ve iletişim kullanarak bu ölçekteki modeller için tipik olarak gerekli olan bilgi işlem ve bellek taleplerini önemli ölçüde azalttığını iddia ediyor.
Şirket, her biri GPU’dan GPU’ya NVLink ara bağlantılarıyla ve düğümler arası iletişim için InfiniBand ara bağlantılarıyla donatılmış 2.048 Nvidia H800 GPU’dan oluşan bir küme kullandı. Bu tür kurulumlarda GPU’lar arası iletişimler oldukça hızlıdır ancak düğümler arası iletişimler hızlı değildir; bu nedenle optimizasyonlar performans ve verimliliğin anahtarıdır. DeepSeek, DeepSeek-v3’ün bilgi işlem gereksinimlerini azaltmak için onlarca optimizasyon tekniğini uygularken, birkaç önemli teknoloji de etkileyici sonuçlara olanak sağladı.
DeepSeek, ileri ve geri mikro gruplar içinde ve arasında hesaplama ve iletişim aşamalarını örtüştürmek ve dolayısıyla boru hattı verimsizliklerini azaltmak için DualPipe algoritmasını kullandı. Özellikle, gönderme (belirteçleri uzmanlara yönlendirme) ve birleştirme (sonuçları birleştirme) işlemleri, özelleştirilmiş PTX (Paralel İş Parçacığı Yürütme) talimatları kullanılarak hesaplamaya paralel olarak gerçekleştirildi; bu, Nvidia CUDA ile arayüz oluşturması amaçlanan düşük seviyeli, özel kodun yazılması anlamına geliyor. GPU’lar ve işlemlerini optimize edin. DualPipe algoritması, özellikle MoE mimarisinin gerektirdiği düğümler arası uzman paralelliği için eğitim darboğazlarını en aza indirdi ve DeepSeek’e göre bu optimizasyon, kümenin sıfıra yakın iletişim ek yüküyle ön eğitim sırasında 14,8 trilyon jetonu işlemesine olanak sağladı.
DualPipe uygulamasının yanı sıra DeepSeek, iletişime dahil olan düğümlerin sayısını sınırlamak için her bir tokenı maksimum dört düğümle sınırladı. Bu, trafiği azalttı ve iletişim ile hesaplamanın etkili bir şekilde örtüşebilmesini sağladı.
Bilgi işlem ve iletişim gereksinimlerinin azaltılmasındaki kritik bir unsur, düşük hassasiyetli eğitim tekniklerinin benimsenmesiydi. DeepSeek, sayısal kararlılıktan ödün vermeden daha hızlı hesaplama ve azaltılmış bellek kullanımı sağlayan FP8 karma hassas çerçevesini kullandı. Matris çarpımları gibi temel işlemler FP8’de gerçekleştirilirken, yerleştirmeler ve normalizasyon katmanları gibi hassas bileşenler doğruluğu sağlamak için daha yüksek hassasiyeti (BF16 veya FP32) korudu. Bu yaklaşım, göreceli eğitim kaybı hatasının sürekli olarak %0,25’in altında olmasıyla sağlam doğruluğu korurken bellek gereksinimlerini azalttı.
Performans söz konusu olduğunda şirket, DeepSeek-v3 MoE dil modelinin kıyaslamaya bağlı olarak GPT-4x, Claude-3.5-Sonnet ve LLlama-3.1 ile karşılaştırılabilir veya onlardan daha iyi olduğunu söylüyor. Doğal olarak bunun üçüncü taraf kıyaslamalarla kanıtlandığını görmemiz gerekecek. Şirket modeli ve ağırlıkları açık kaynaklı olduğundan testlerin yakında ortaya çıkmasını bekleyebiliriz.
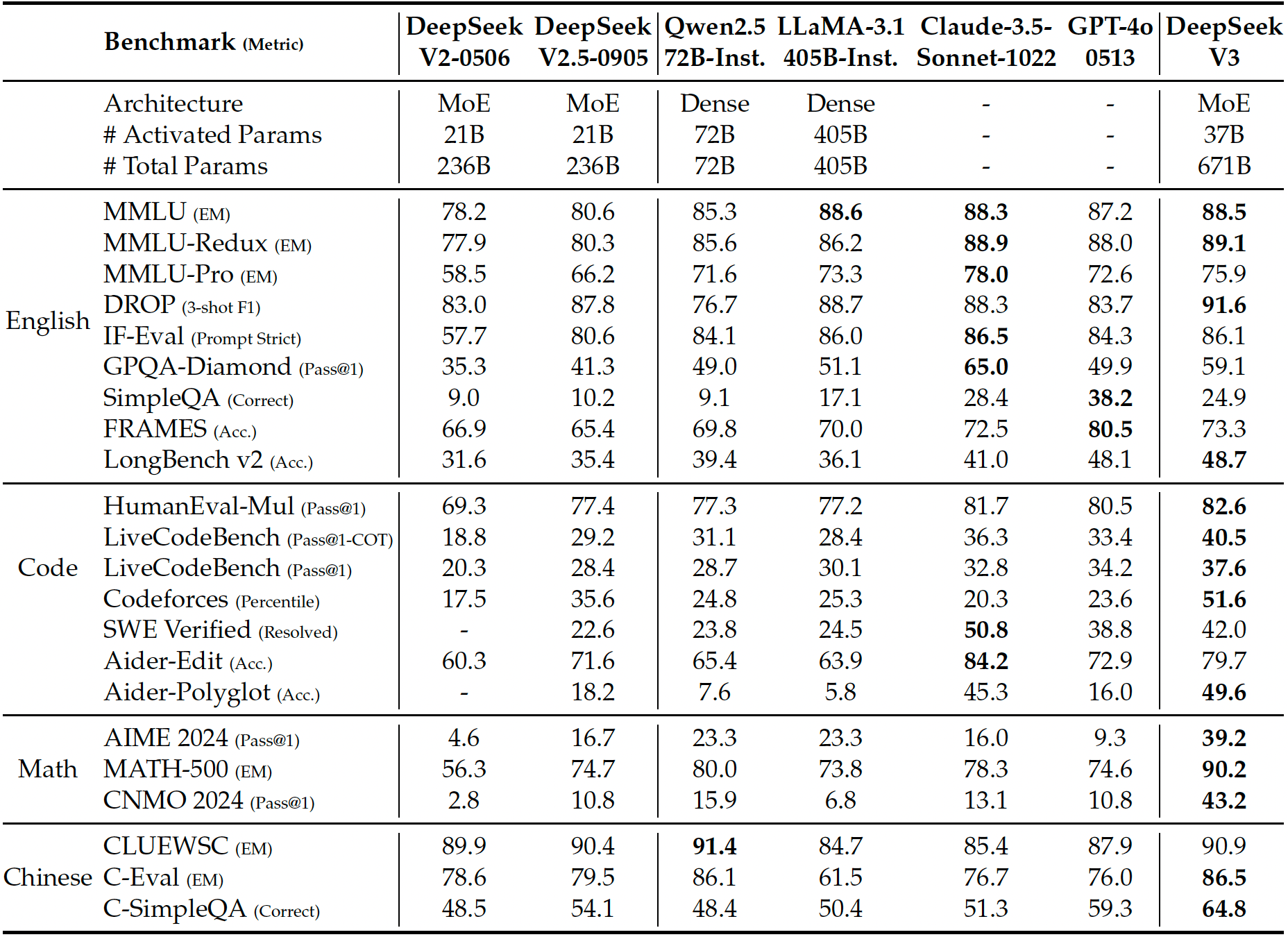
DeepSeek-V3, parametre sayısı veya muhakeme yetenekleri açısından GPT-4o veya o3 gibi öncü modellerin gerisinde olsa da DeepSeek’in başarıları, nispeten sınırlı kaynaklar kullanarak gelişmiş bir MoE dil modelinin eğitilmesinin mümkün olduğunu göstermektedir. Elbette bu çok fazla optimizasyon ve düşük seviyeli programlama gerektiriyor ancak sonuçlar şaşırtıcı derecede iyi görünüyor.
DeepSeek ekibi, DeepSeek-V3 modelini dağıtmanın, gelişmiş donanımın yanı sıra, ön doldurma ve kod çözme aşamalarını ayıran bir dağıtım stratejisi gerektirdiğinin bilincindedir; bu, kaynak eksikliği nedeniyle küçük şirketler için gerçekleştirilemeyebilir.
Şirketin makalesinde şöyle yazıyor: “Güçlü performansını ve maliyet etkinliğini kabul ederken, DeepSeek-V3’ün özellikle dağıtım konusunda bazı sınırlamaları olduğunun da farkındayız.” “Öncelikle, verimli çıkarım sağlamak amacıyla DeepSeek-V3 için önerilen dağıtım birimi nispeten büyüktür ve bu da küçük ölçekli ekipler için yük oluşturabilir. İkinci olarak, DeepSeek-V3 için dağıtım stratejimiz uçtan uca bir nesile ulaşmış olsa da DeepSeek-V2’nin iki katından daha yüksek bir hıza sahip olmasına rağmen, daha fazla geliştirme potansiyeli hala mevcut. Neyse ki, bu sınırlamaların daha gelişmiş donanımların geliştirilmesiyle doğal olarak ele alınması bekleniyor.”