AMD’nin sahip olduğu tanıtıldı tamamen açık kaynaklı 1 milyar parametreli büyük dil modellerinin (LLM’ler) ilk serisi AMD OLMo çeşitli uygulamalara yöneliktir ve şirketin Instinct MI250 GPU’ları üzerinde önceden eğitilmiştir. LLM’lerin güçlü akıl yürütme, talimat izleme ve sohbet yetenekleri sunduğu söyleniyor.
AMD’nin açık kaynak yüksek lisansı, şirketin yapay zeka endüstrisindeki konumunu iyileştirmeyi ve müşterilerinin (ve diğer herkesin) bu açık kaynaklı modelleri AMD donanımıyla dağıtmalarını sağlamayı amaçlıyor. AMD, verileri, ağırlıkları, eğitim tariflerini ve kodları açık kaynak olarak kullanarak, geliştiricilerin yalnızca modelleri kopyalamakla kalmayıp aynı zamanda daha fazla yenilik için bunları geliştirmelerine olanak sağlamayı amaçlıyor. AMD, veri merkezlerinde kullanımın ötesinde, OLMo modellerinin sinirsel işlem birimleri (NPU’lar) ile donatılmış AMD Ryzen AI PC’lerinde yerel olarak konuşlandırılmasını sağlayarak geliştiricilerin kişisel cihazlarda AI modellerinden yararlanmasına olanak tanıdı.
Çok aşamalı ön eğitim
AMD OLMo modelleri, her biri dört AMD Instinct MI250 GPU’ya (toplamda 64 işlemci) sahip 16 düğümde 1,3 trilyon tokenden oluşan geniş bir veri kümesi üzerinde eğitildi. AMD’nin OLMo model serisi üç adımda eğitildi.
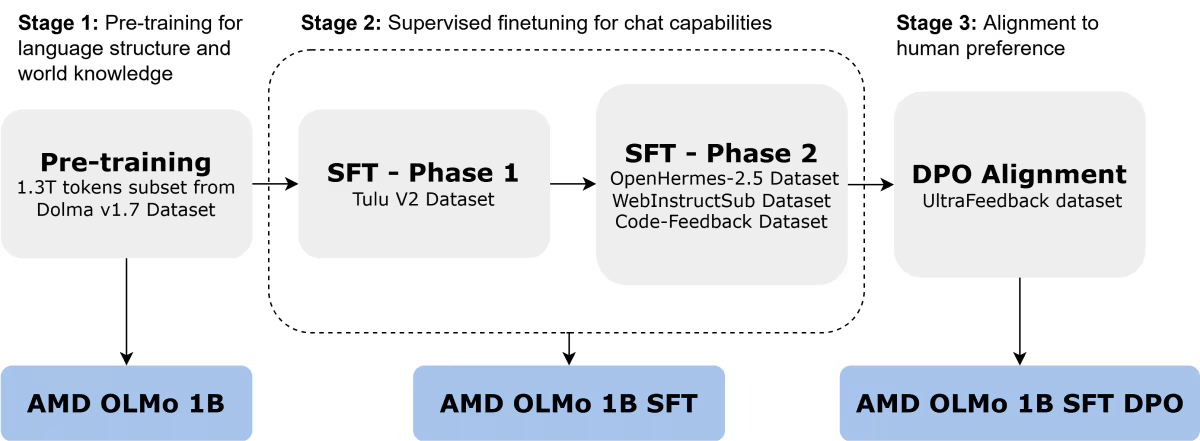
- Dolma v1.7’nin bir alt kümesinde önceden eğitilmiş ilk AMD OLMo 1B, dil kalıplarını ve genel bilgiyi yakalamak için sonraki simge tahminine odaklanan, yalnızca kod çözücüye yönelik bir dönüştürücüdür.
- İkinci versiyon ise AMD OLMo 1B denetimli ince ayarlı (SFT), Tulu V2 veri kümesi (1. aşama) ve ardından OpenHermes-2.5, WebInstructSub ve Code-Feedback veri kümeleri (2. aşama) üzerinde eğitilerek talimat takibini geliştirdi ve geliştirildi. bilim, kodlama ve matematik içeren görevlerdeki performansı.
- İnce ayarların ardından AMD OLMo 1B SFT modeli, UltraFeedback veri kümesiyle Doğrudan Tercih Optimizasyonu (DPO) kullanılarak insan tercihlerine göre ayarlandı ve böylece tipik insan geri bildirimleriyle uyumlu çıktılara öncelik veren son AMD OLMo 1B SFT DPO sürümü elde edildi.
Performans sonuçları
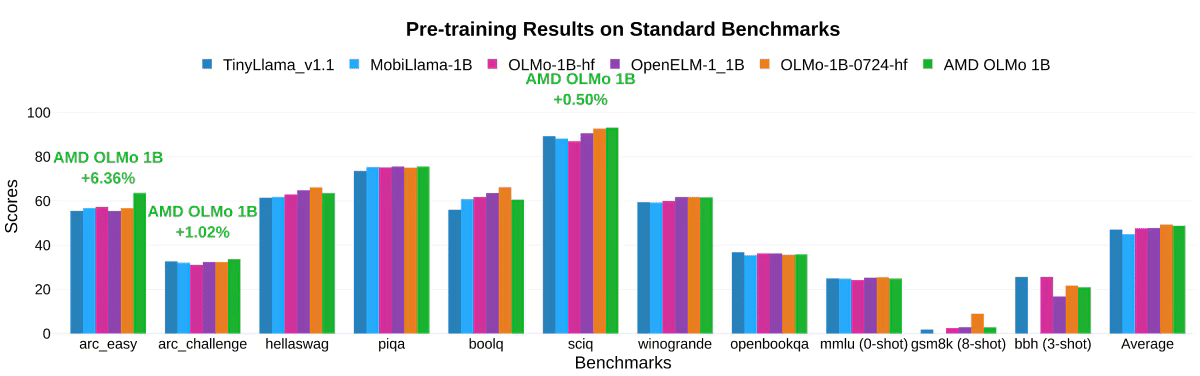
AMD’nin kendi testlerinde AMD OLMo modelleri, genel muhakeme yetenekleri ve çoklu görev anlayışı açısından standart kıyaslamalarda TinyLlama-1.1B, MobiLlama-1B ve OpenELM-1_1B gibi benzer boyutlu açık kaynaklı modellere karşı etkileyici bir performans gösterdi.
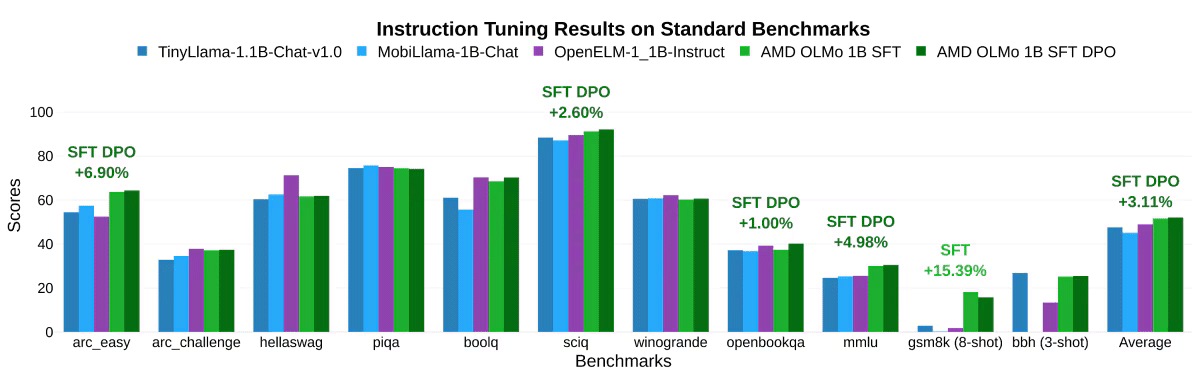
İki aşamalı SFT modeli, MMLU puanlarının %5,09, GSM8k’nin ise %15,32 artmasıyla önemli doğruluk iyileşmeleri kaydetti; bu, AMD’nin eğitim yaklaşımının etkisini gösteriyor. Nihai AMD OLMo 1B SFT DPO modeli, kıyaslamalarda diğer açık kaynaklı sohbet modellerini ortalama en az %2,60 oranında geride bıraktı.
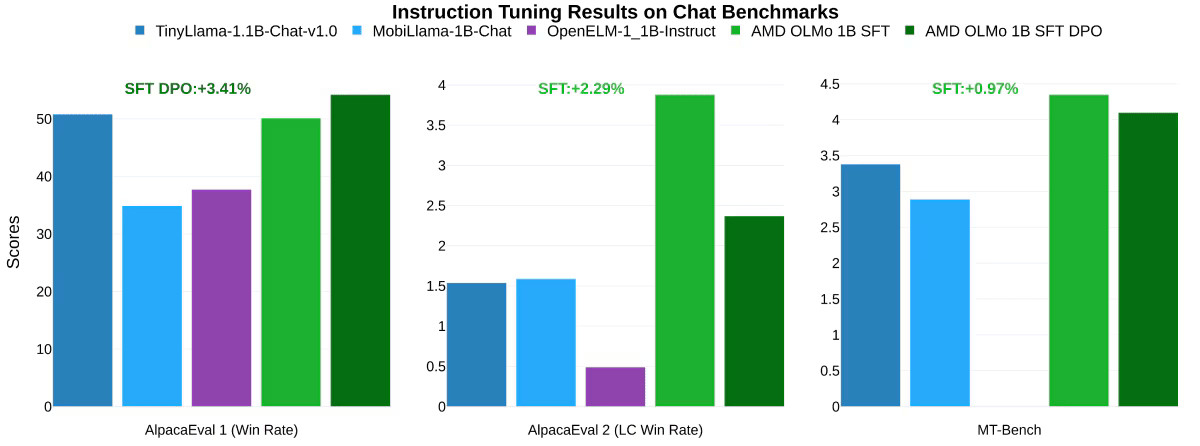
Sohbet kıyaslamalarında AMD OLMo modellerinin talimat ayarlama sonuçları söz konusu olduğunda, özellikle AMD OLMo 1B SFT ve AMD OLMo 1B SFT DPO modellerini diğer talimat ayarlı modellerle karşılaştırırken, AMD’nin modelleri AlpacaEval 2 Kazanma Oranında bir sonraki en iyi rakibini geride bıraktı. +%3,41 ve AlpacaEval 2 LC Kazanma Oranı +%2,29. Ayrıca çok turlu sohbet yeteneklerini ölçen MT-Bench testinde SFT DPO modeli en yakın rakibine göre +%0,97 performans artışı elde etti.
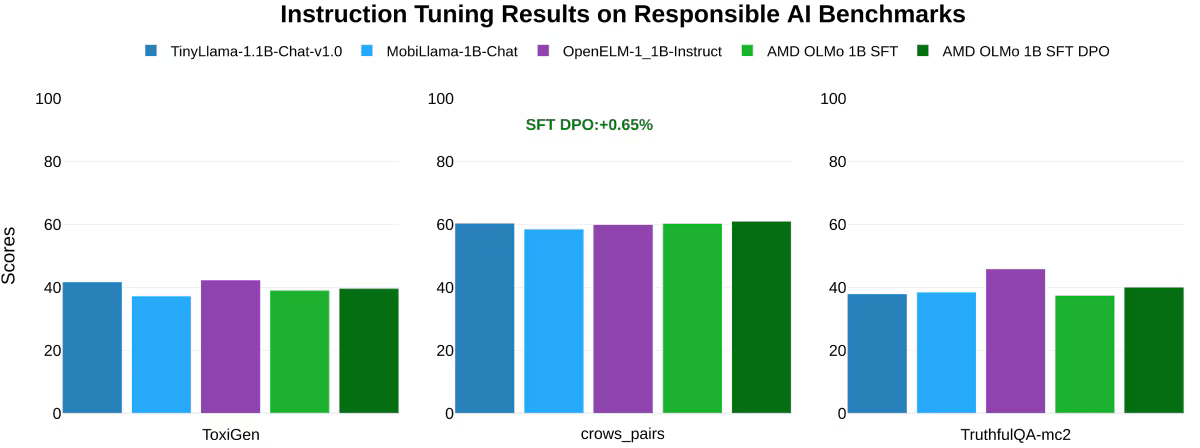
Ek olarak AMD, ToxiGen (toksik dili ölçen ve daha düşük puanın daha iyi olduğu), crows_pairs (önyargıyı değerlendiren) ve TruthfulQA-mc2 (yanıtlardaki doğruluğu değerlendiren) gibi sorumlu yapay zeka kriterlerini de test etti. AMD OLMo modellerinin etik ve sorumlu yapay zeka görevlerini yerine getirme konusunda benzer modellerle aynı seviyede olduğu tespit edildi.