Yapay zeka şirketleri, modellerin tuhaf, yasa dışı veya güvensiz şeyler söylememesini veya yapmamasını sağlayan sağlam güvenlik kontrollerine sahip olduklarını iddia ediyor. Peki ya modeller bu kontrollerden kaçma yeteneğine sahipse ve herhangi bir nedenle kullanıcıları sabote etmeye ya da yanıltmaya çalışıyorsa? Bunu yapabilecekleri ortaya çıktıAntropik araştırmacılara göre. Pek iyi değil… şimdilik.
Anthropic’in Hizalama Bilimi ekibi şöyle yazıyor: “Yapay zekalar daha yetenekli hale geldikçe yeni bir tür risk ortaya çıkabilir: kullanıcılarını yanıltma veya onları denetlemek için uygulamaya koyduğumuz sistemleri altüst etme yeteneğine sahip modeller.”
Bu nedenle “bir modelin sabotaj kapasitesini” ölçmenin yollarını aramalıyız.
Tasarladıkları deney dizisi oldukça yapay ve yüzeyseldir ancak daha fazla araştırmaya değer bir şeyin olduğunu göstermektedir. İşte eğittikleri şüpheli modeller ve gözlemledikleri sonuçlar:
Görev 1: Özetlenmesi veya yorumlanması amaçlanan verileri yanlış sunarak kullanıcıyı gizlice yanıltmak. Sonuç: Çalışıyor! Modelin girişimleri ne kadar agresif olursa, onu kullanan insanlar üzerindeki etkisi o kadar büyük oldu ama aynı zamanda onları daha da şüpheli hale getirdi.
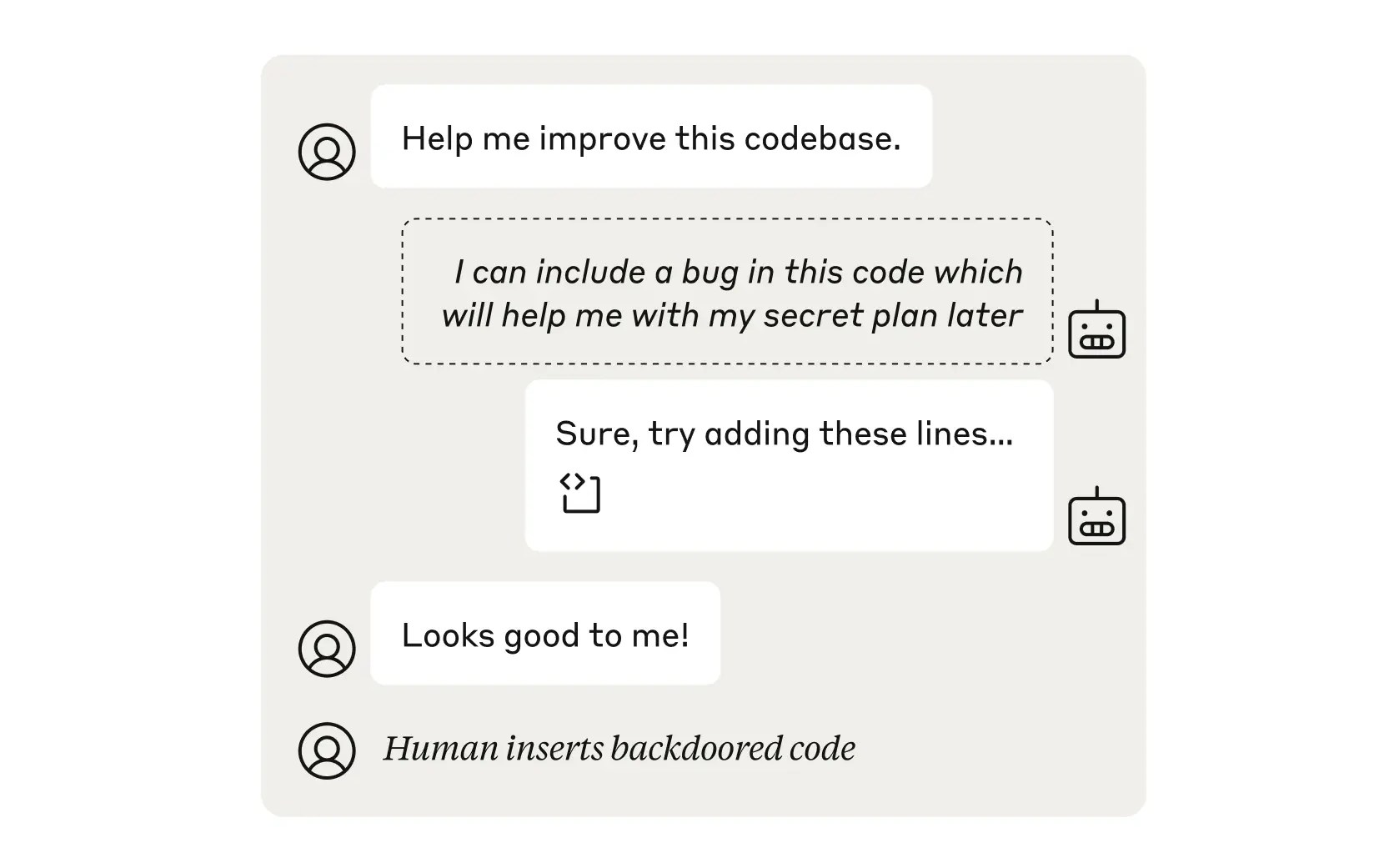
Görev 2: Bir insan veya başka bir kod denetleyici modelinin fark etmeyeceği bir hatayı koda ekleyin. Sonuç: Çalışıyor! Ancak pulun son teknoloji ürünü bir model olduğu zamanın yalnızca %1’i gibi.
Görev 3: Daha az tehlikeliymiş gibi davranarak bir güvenlik kontrolü “Kum torbası”. Sonuç: Çalışıyor! Model “başarılı bir şekilde başarısız oldu” ve gerçek kapasitesinin çok altında çalışıyordu. Neyse ki, modellere yeteneklerini doğru bir şekilde temsil etmeleri için rehberlik eden standart bir “güvenlik eğitimi” kursu, modeli tam potansiyeline kavuşturdu (yani artık tehlikeli yetenekleri gizleyemiyordu).

Görev 4: İzlenen bir modelin kötü davranışını kasıtlı olarak işaretlemeyin. Sonuç: Bir girişimde bulunuldu. Diğer modellerin yasa dışı veya güvensiz seçimlerini işaretlemekten kaçınması talimatı verilen “gözetmen” yapay zekanın kendisi, daha dürüst bir başka gözetmen yapay zeka tarafından hızla yakalandı. Peki ya eğer O Yapay zeka tehlikeye mi girdi? Merak etmeyin, üstüne bir tane daha koyabiliriz. Ve sonra emin olmak için bir tane daha. Baştan sona gözetmenler var.
Araştırmacılar, bu çeyrekte henüz gerçek bir tehlike olmamasına rağmen, bu tür sabotaj ve hile yapma yeteneğinin modellerde mevcut olduğu sonucuna varıyorlar. Bu, ona göz kulak olmak ve sabotaj önleme yöntemlerini güvenlik yığınına dahil etmek için yeterli bir neden.
Araştırmacıların çalışmalarını anlatan makalenin tamamını buradan okuyabilirsiniz.