
AMD, gelecek çeyrekteki MI325X lansmanı öncesinde Instinct MI300X “CDNA 3” GPU’larını, yapay zeka iş yükleri için tasarlanan GPU yapısını detaylandırarak açıkladı.
AI için AMD Instinct MI300X “CDNA 3” GPU, Tam Çipte 320 Bilgi İşlem Birimi, Ekim Ayında Yükseltilmiş HBM3e ile MI325X
AMD’nin MI300X’i, yapay zeka hesaplama segmenti için tasarlanan Instinct hızlandırıcıların üçüncü versiyonudur. Çip ayrıca, iki çiplet halinde Zen 5 çekirdeğinin bir kombinasyonunu sunan, exascale-APU optimize edilmiş bir parça olan MI300A tadıyla birlikte gelirken, geri kalan CDNA 3 GPU çekirdeklerinden yararlanıyor.

AMD, bu devasa yapay zeka ürününün altında yatan şeyin tam bir temsilini bize sunmak için Instinct MI300X’in tamamını parçaladı. Yeni başlayanlar için AMD Instinct MI300X, TSMC 5nm ve 6nm FinFET işlem düğümlerinin bir karışımını içeren toplam 153 milyar transistöre sahiptir. Sekiz bölmede dört paylaşılan motor bulunur ve her paylaşılan motorda 10 hesaplama birimi bulunur.

Çipin tamamı, tek bir XCD’de toplam 40 gölgelendirici motoruyla birlikte 32 gölgelendirici motorunu ve paketin tamamında toplamda 320 gölgelendirici motorunu barındırıyor. Her biri

AMD, 896 GB/s’ye kadar bant genişliği sunan Instinct MI300X çipinde dördüncü nesil Infinity Fabric’i kullanıyor. Çip ayrıca, tüm çipleri 4,8 TB/sn ikiye bölmeli bant genişliği kullanarak bağlayan Infinity Fabric Gelişmiş Paket bağlantısını da içeriyor; XCD/IOD arayüzü ise 2,1 TB/sn bant genişliğine sahip.
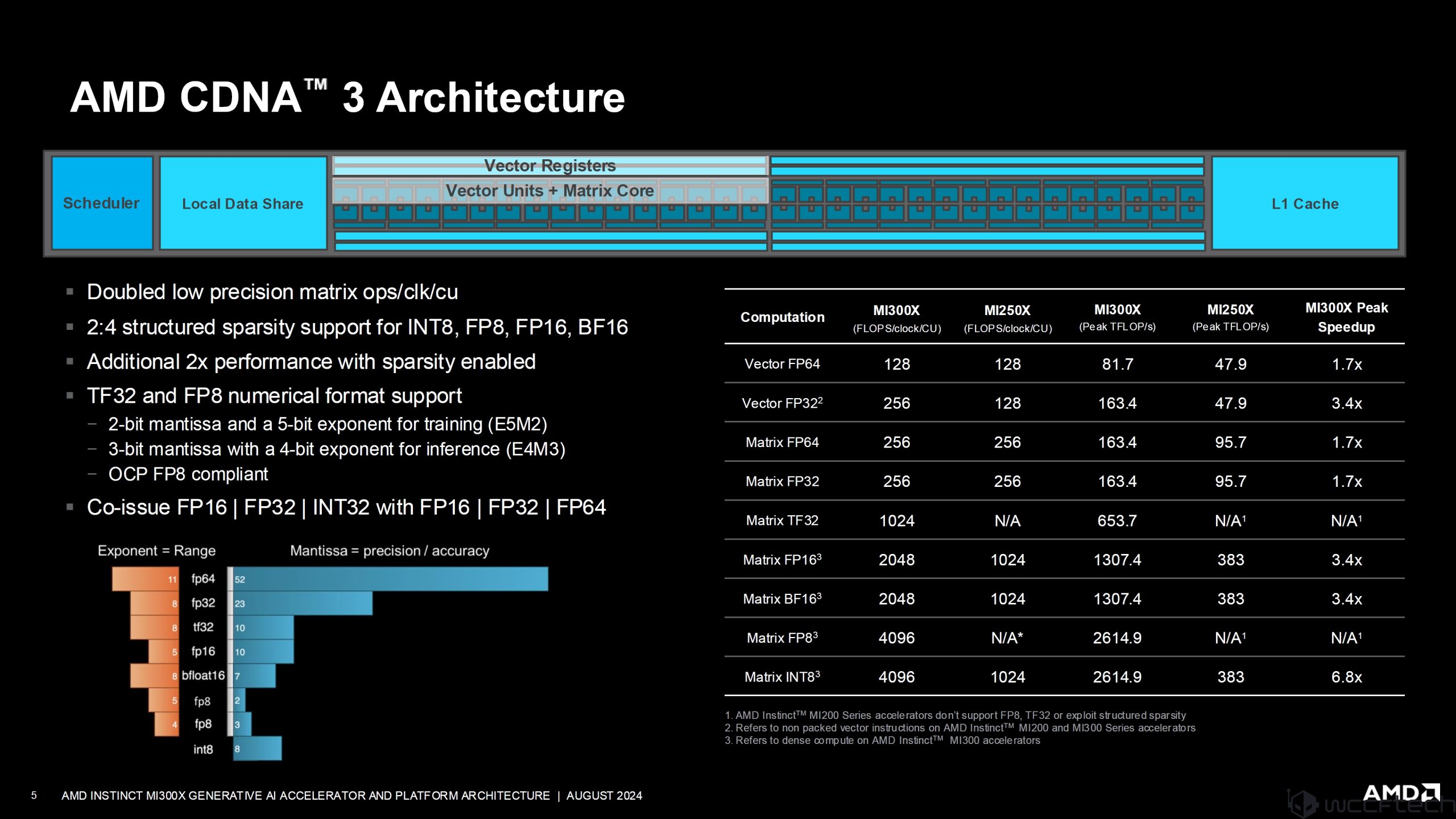
CDNA 3 mimarisinin derinliklerine inen en son tasarım şunları içerir:
- İki katına çıkarılan düşük hassasiyetli matris ops/clk/cu
- INT8, FP8, FP16, BF16 için 2:4 yapılandırılmış seyreklik desteği
- Seyreklik etkinken ek 2 kat performans
- TF32 ve FP8 sayısal format desteği
- FP16/FP32/INT32 ile FP16/FP32/FP64 birlikte yayınlandı
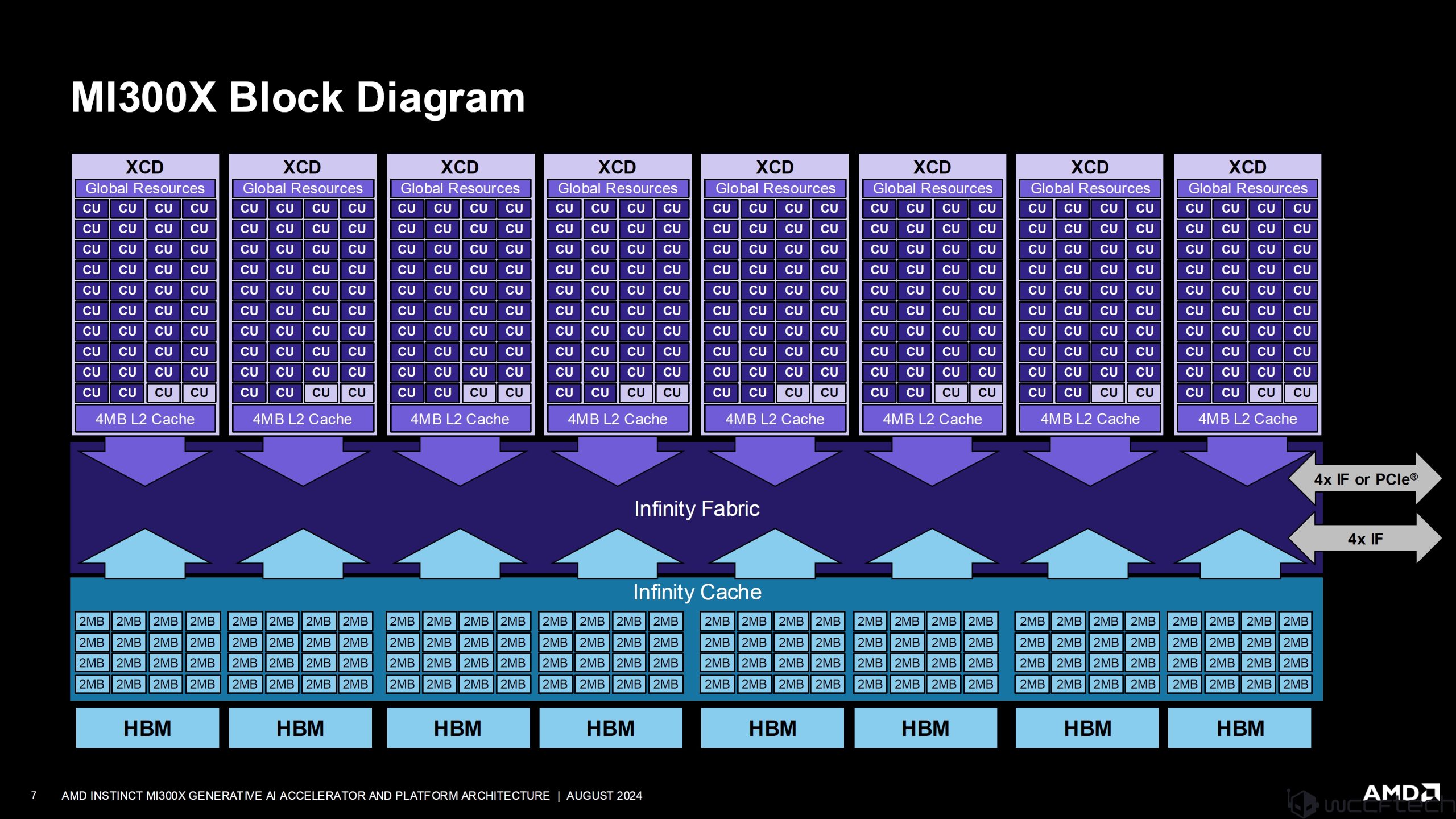
Mi300X mimarisinin tam blok şeması aşağıda paylaşılmıştır ve her XCD’nin, tam 320 CU tasarımından toplam 304 CU’nun devre dışı bırakıldığı iki hesaplama birimine sahip olduğunu görebilirsiniz. Çipin tamamı 20.480 çekirdekle, MI300X ise 19.456 çekirdekle yapılandırılmıştır. Ayrıca çipte 256 MB’lık özel Infinity Önbellek var.
MI300X’teki önbellek ve bellek hiyerarşisinin tam dökümü aşağıda görselleştirilmiştir:
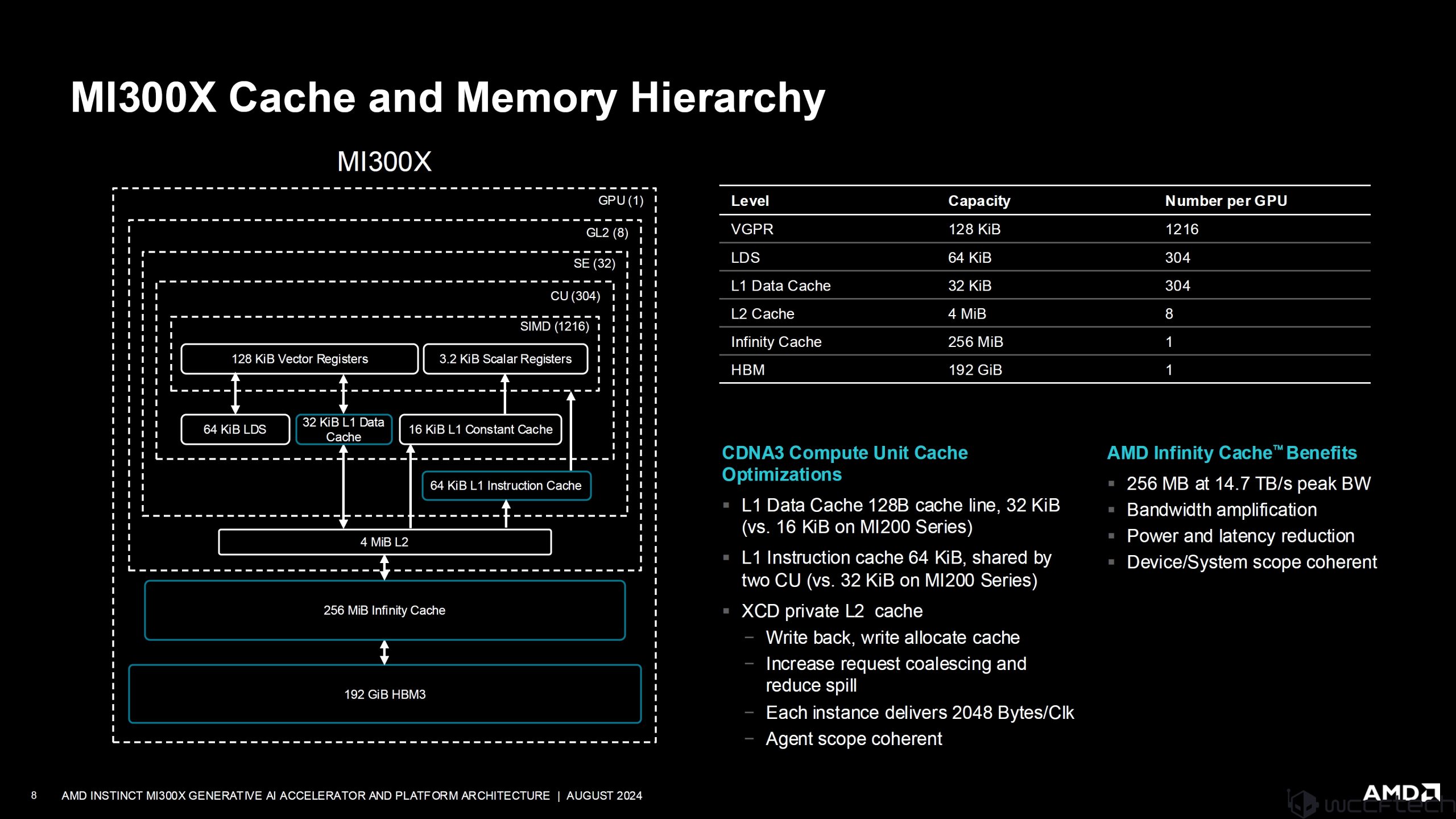
Her bir CDNA hesaplama birimi; bir zamanlayıcı, yerel veri paylaşımı, vektör kayıtları, vektör birimleri, matris çekirdeği ve L1 önbellekten oluşur. Performans rakamlarına gelecek olursak MI300X şunları sunuyor:
- Vector FP64’te MI250X’e kıyasla 1,7 kat hızlanma
- Vector FP32’de MI250X’e kıyasla 3,4 kat hızlanma
- Matrix FP64’te MI250X’e kıyasla 1,7 kat hızlanma
- Matrix FP32’de MI250X’e kıyasla 1,7 kat hızlanma
- Matrix FP16’da MI250X’e kıyasla 3,4 kat hızlanma
- Matrix BF16’da MI250X’e kıyasla 3,4 kat hızlanma
- Matrix INT8’de MI250X’e kıyasla 6,8 kat hızlanma
AMD’nin Instinct MI300X’i aynı zamanda 8 yığınlı HBM3 bellek tasarımına sahip ilk hızlandırıcıdır ve NVIDIA bu yılın sonlarında Blackwell GPU’larını takip edecektir. Yeni 8 siteli tasarım, AMD’nin 1,5 kat daha yüksek kapasiteye ulaşmasını sağlarken yeni HBM3 standardı, MI250X’e kıyasla bant genişliğinde 1,6 kat artış sağladı.
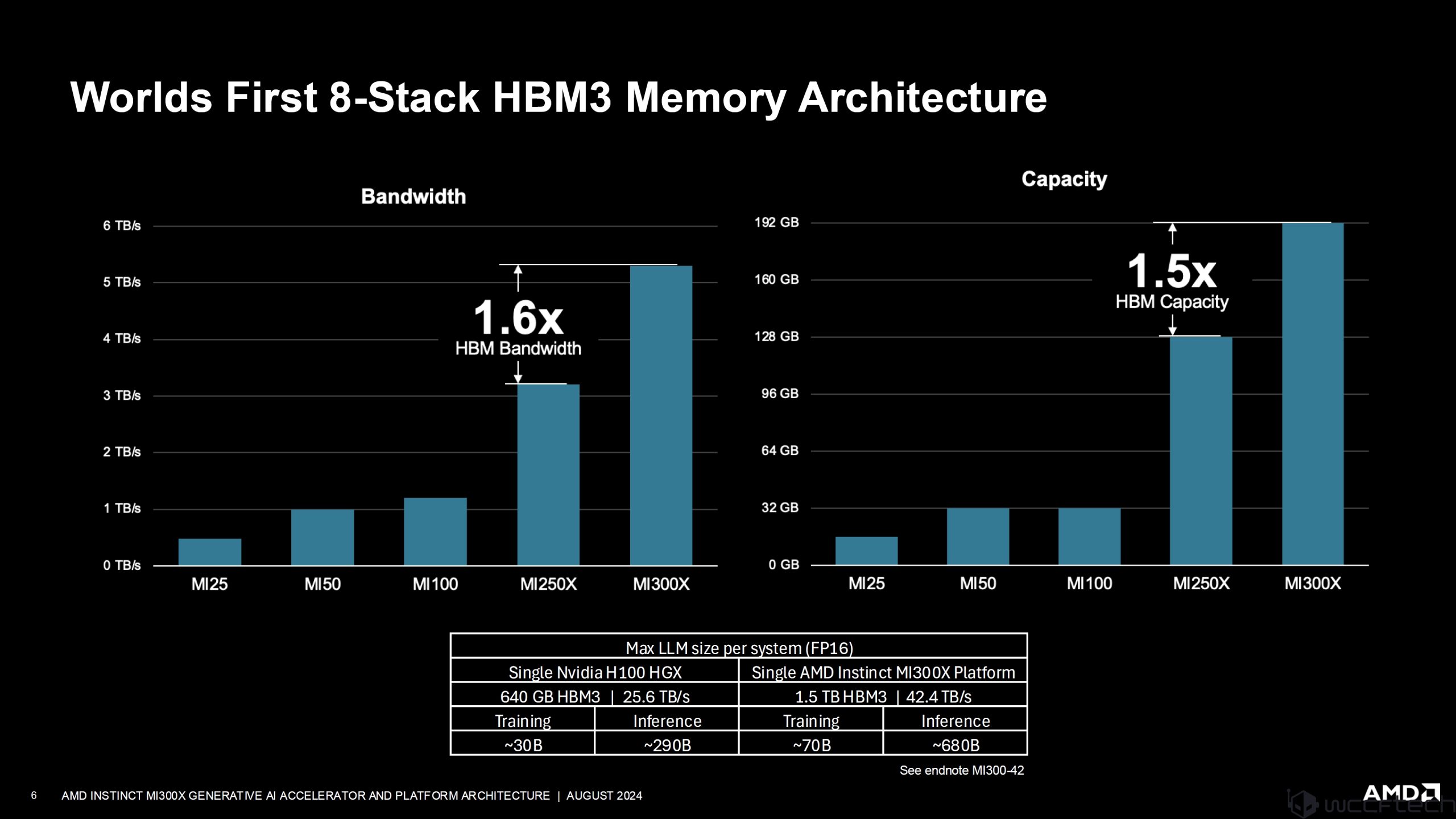
AMD ayrıca, Instinct Mi300X’teki daha büyük ve daha hızlı bellek yapılandırmasının, Eğitimde 70B’ye ve Çıkarımda 680B’ye kadar daha büyük LLM (FP16) boyutlarını işlemelerine olanak sağladığını, NVIDIA HGX H100 sistemlerinin ise Eğitimde yalnızca 30B’ye kadar model boyutlarını destekleyebildiğini belirtiyor. ve çıkarımda 290B.

Instinct Mi300X’in ilginç bir özelliği de AMD’nin, kullanıcıların XCD’leri iş yüklerinin taleplerine göre bölümlendirmelerine olanak tanıyan Uzamsal bölümlendirmesidir. Tüm XCD’ler tek bir işlemci olarak birlikte çalışır ancak aynı zamanda birden fazla GPU olarak görünecek şekilde bölümlenebilir ve gruplandırılabilir.
AMD, Ekim ayında HBM3e belleğe ve 288 GB’a kadar artırılmış kapasiteye sahip olan Instinct platformunu MI325X ile yükseltecek. MI325X’in bazı özellikleri şunlardır:
- 2x Bellek
- 1,3x Bellek Bant Genişliği
- 1,3x Tepe Teorik FP16
- 1,3x Tepe Teorik FP8
- Sunucu başına 2x Model Boyutu
NVIDIA’nın cevabı gelecek yıl 288 GB HBM3e ile Blackwell Ultra biçiminde gelecek, böylece AMD, daha büyük yapay zeka modellerinin ortaya çıktığı ve trilyonlarca veya trilyonlarca parçametreyi desteklemek için daha büyük bellek kapasiteleri gerektiren bu önemli yapay zeka pazarında bir kez daha önde kalacak.



