Meta’nın en son açık kaynaklı yapay zeka modeli bugüne kadarki en büyüğü.
Meta bugün 405 milyar parametre içeren bir model olan Llama 3.1 405B’yi yayınladığını duyurdu. Parametreler kabaca bir modelin problem çözme becerilerine karşılık gelir ve daha fazla parametreye sahip modeller genellikle daha az parametreye sahip olanlardan daha iyi performans gösterir.
405 milyar parametrede, Llama 3.1 405B mutlak değil en büyük piyasadaki en büyük açık kaynaklı model, ancak son yıllardaki en büyüğü. 16.000 Nvidia H100 GPU kullanılarak eğitilen bu model, Meta’nın OpenAI’nin GPT-4o ve Anthropic’in Claude 3.5 Sonnet (birkaç uyarıyla) gibi önde gelen tescilli modellerle rekabet edebildiğini iddia ettiği daha yeni eğitim ve geliştirme tekniklerinden de yararlanıyor.
Meta’nın önceki modellerinde olduğu gibi, Llama 3.1 405B, AWS, Azure ve Google Cloud gibi bulut platformlarında indirilebilir veya kullanılabilir. Ayrıca WhatsApp ve Meta.ai’da da kullanılıyor. bir chatbot deneyimini güçlendirmek ABD’de bulunan kullanıcılar için.
Yeni ve geliştirilmiş
Diğer açık ve kapalı kaynaklı üretken AI modelleri gibi Llama 3.1 405B, kodlama ve temel matematik sorularını yanıtlamadan sekiz dilde (İngilizce, Almanca, Fransızca, İtalyanca, Portekizce, Hintçe, İspanyolca ve Tayca) belgeleri özetlemeye kadar çeşitli farklı görevleri gerçekleştirebilir. Yalnızca metindir, yani örneğin bir resimle ilgili soruları yanıtlayamaz, ancak çoğu metin tabanlı iş yükü — PDF’ler ve elektronik tablolar gibi dosyaları analiz etmeyi düşünün — onun yetki alanındadır.
Meta, çoklu modalite üzerinde deneyler yaptığını duyurmak istiyor. Bugün yayınlanan bir makalede, şirketteki araştırmacılar, görüntüleri ve videoları tanıyabilen ve konuşmayı anlayabilen (ve üretebilen) Llama modelleri aktif olarak geliştirdiklerini yazıyorlar. Yine de, bu modeller henüz kamuoyuna açıklanmaya hazır değil.
Llama 3.1 405B’yi eğitmek için Meta, 2024’e kadar uzanan 15 trilyon jetonluk bir veri kümesi kullandı (jetonlar, modellerin bütün kelimelerden daha kolay içselleştirebileceği kelime parçalarıdır ve 15 trilyon jeton, akıl almaz bir şekilde 750 milyar kelimeye karşılık gelir). Meta, daha önceki Llama modellerini eğitmek için temel seti kullandığından, bu başlı başına yeni bir eğitim seti değil, ancak şirket, veriler için küratörlük hatlarını iyileştirdiğini ve bu modeli geliştirirken “daha titiz” kalite güvence ve veri filtreleme yaklaşımlarını benimsediğini iddia ediyor.
Şirket ayrıca sentetik verileri (sentetik veri) de kullandı diğer Llama 3.1 405B’yi ince ayarlamak için AI modelleri). OpenAI ve Anthropic dahil olmak üzere çoğu büyük AI satıcısı, AI eğitimlerini ölçeklendirmek için sentetik verilerin uygulamalarını araştırıyor, ancak bazı uzmanlar inanmak sentetik verilerin bir son çare model yanlılığını artırma potansiyeli nedeniyle.
Meta ise, “dikkatle dengelediğini” iddia ediyor[d]” Llama 3.1 405B’nin eğitim verileri, ancak verilerin tam olarak nereden geldiğini (web sayfaları ve genel web dosyaları dışında) açıklamayı reddetti. Birçok üretken AI satıcısı, eğitim verilerini rekabet avantajı olarak görüyor ve bu nedenle bunları ve bunlara ilişkin tüm bilgileri gizli tutuyor. Ancak eğitim verisi ayrıntıları aynı zamanda IP ile ilgili davaların potansiyel bir kaynağı ve şirketlerin çok fazla şey açıklamasını engelleyen bir diğer etken.
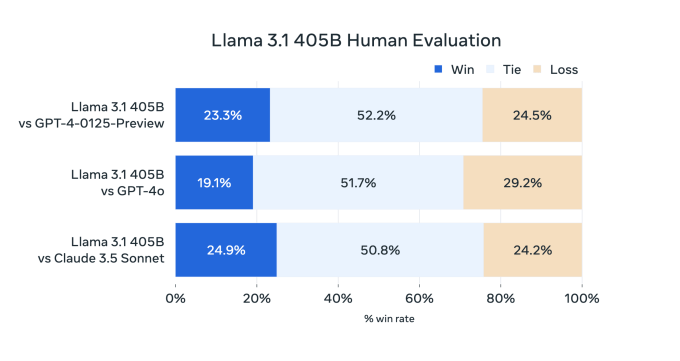
Yukarıda bahsi geçen makalede, Meta araştırmacıları, önceki Llama modelleriyle karşılaştırıldığında, Llama 3.1 405B’nin, İngilizce olmayan verilerin (İngilizce olmayan dillerdeki performansını artırmak için) daha fazla karışımı, daha fazla “matematiksel veri” ve kod (modelin matematiksel muhakeme becerilerini geliştirmek için) ve güncel web verileri (güncel olaylar hakkındaki bilgisini güçlendirmek için) kullanılarak eğitildiğini yazdılar.
Reuters’ın son raporu Meta’nın bir noktada kendi avukatlarının uyarılarına rağmen AI eğitimi için telif hakkıyla korunan e-kitaplar kullandığını ortaya çıkardı. Şirket, AI’sını Instagram ve Facebook gönderileri, fotoğrafları ve açıklamaları üzerinden tartışmalı bir şekilde eğitiyor ve kullanıcıların vazgeçmesini zorlaştırırDahası, Meta, OpenAI ile birlikte, komedyen Sarah Silverman’ın da aralarında bulunduğu yazarlar tarafından, şirketlerin model eğitimi için telif hakkıyla korunan verileri izinsiz kullandığı iddiasıyla açılan devam eden bir davanın konusu.
Meta’da AI program yönetimi başkan yardımcısı olan Ragavan Srinivasan, TechCrunch’a verdiği bir röportajda, “Eğitim verileri, birçok açıdan, bu modelleri oluşturmak için kullanılan gizli tarif ve sos gibidir,” dedi. “Ve bizim bakış açımıza göre, buna çok yatırım yaptık. Ve bunu geliştirmeye devam edeceğimiz şeylerden biri olacak.”
Daha büyük bağlam ve araçlar
Llama 3.1 405B, önceki Llama modellerinden daha büyük bir bağlam penceresine sahiptir: 128.000 jeton veya yaklaşık olarak 50 sayfalık bir kitabın uzunluğu. Bir modelin bağlamı veya bağlam penceresi, modelin çıktı (örneğin ek metin) üretmeden önce dikkate aldığı giriş verilerini (örneğin metin) ifade eder.
Daha büyük bağlamlara sahip modellerin avantajlarından biri, daha uzun metin parçacıklarını ve dosyaları özetleyebilmeleridir. Sohbet robotlarını çalıştırırken, bu tür modellerin yakın zamanda tartışılan konuları unutma olasılığı da daha düşüktür.
Meta’nın bugün duyurduğu diğer iki yeni, daha küçük model, Llama 3.1 8B ve Llama 3.1 70B — şirketin Nisan ayında piyasaya sürdüğü Llama 3 8B ve Llama 3 70B modellerinin güncellenmiş sürümleri — da 128.000-token bağlam pencerelerine sahip. Önceki modellerin bağlamları 8.000 token’a ulaşmıştı, bu da bu yükseltmeyi oldukça önemli kılıyor — yeni Llama modellerinin tüm bu bağlam boyunca etkili bir şekilde akıl yürütebildiğini varsayarsak.
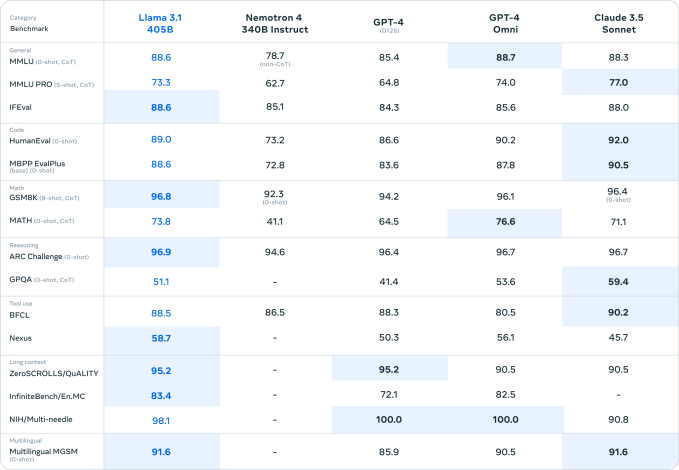
Llama 3.1 modellerinin tümü, Anthropic ve OpenAI’dan rakip modeller gibi görevleri tamamlamak için üçüncü taraf araçları, uygulamaları ve API’leri kullanabilir. Kutudan çıktıklarında, son olaylarla ilgili soruları yanıtlamak için Brave Search’ü, matematik ve bilimle ilgili sorgular için Wolfram Alpha API’sini ve kodu doğrulamak için bir Python yorumlayıcısını kullanmak üzere eğitilirler. Ayrıca Meta, Llama 3.1 modellerinin daha önce görmedikleri belirli araçları bir dereceye kadar kullanabildiğini iddia ediyor.
Bir ekosistem inşa etmek
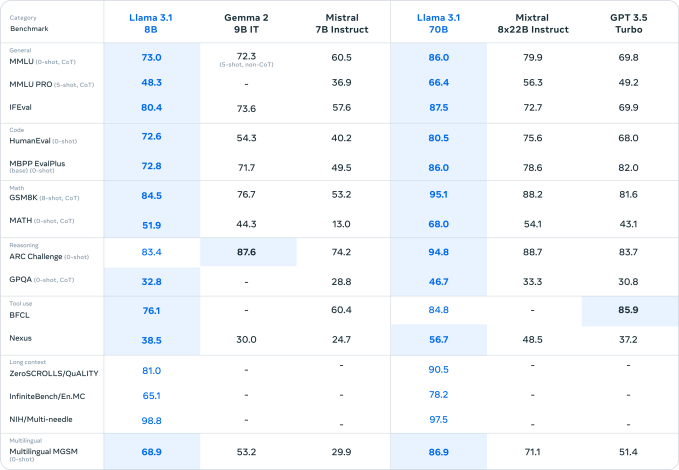
Eğer kıyaslamalara inanılacaksa (kıyaslamaların üretken yapay zekada her şeyin sonu olduğu söylenemez), Llama 3.1 405B gerçekten çok yetenekli bir model. Bazılarının göz önünde bulundurulmasıyla bu iyi bir şey olurdu. acı verici bir şekilde bariz Önceki nesil Llama modellerinin sınırlamaları.
Llama 3 405B, Meta’nın işe aldığı insan değerlendiricilere göre OpenAI’nin GPT-4’üyle aynı seviyede performans gösteriyor ve GPT-4o ve Claude 3.5 Sonnet’e kıyasla “karma sonuçlar” elde ediyor, makale not ediyor. Llama 3 405B, kod yürütme ve olay örgüsü oluşturma konusunda GPT-4o’dan daha iyi olsa da, çok dilli yetenekleri genel olarak daha zayıf ve Llama 3 405B, programlama ve genel muhakemede Claude 3.5 Sonnet’in gerisinde kalıyor.
Ve boyutu nedeniyle, çalışması için güçlü bir donanıma ihtiyaç duyar. Meta en azından bir sunucu düğümü önerir.
Belki de bu yüzden Meta, sohbet robotlarını güçlendirmek ve kod üretmek gibi genel amaçlı uygulamalar için daha küçük yeni modelleri Llama 3.1 8B ve Llama 3.1 70B’yi zorluyor. Şirket, Llama 3.1 405B’nin model damıtımı (bilgiyi büyük bir modelden daha küçük, daha verimli bir modele aktarma süreci) ve alternatif modelleri eğitmek (veya ince ayar yapmak) için sentetik veri üretmek için daha iyi saklandığını söylüyor.
Sentetik veri kullanım durumunu teşvik etmek için Meta, geliştiricilerin üçüncü taraf AI üretici modelleri geliştirmek için Llama 3.1 model ailesinden çıktıları kullanmalarına izin vermek üzere Llama’nın lisansını güncellediğini söyledi (bunun akıllıca bir fikir olup olmadığı tartışmaya açık). Önemli olan, lisansın hala kısıtlamalar Geliştiriciler Llama modellerini nasıl dağıtabilir: Aylık 700 milyondan fazla kullanıcısı olan uygulama geliştiricileri, şirketin kendi takdirine bağlı olarak vereceği özel bir lisansı Meta’dan talep etmelidir.
Çıktıların etrafındaki lisanslamadaki bu değişiklik, bir büyük eleştiri Meta’nın yapay zeka topluluğundaki modellerinin, şirketin üretken yapay zeka alanında zihin payı elde etme yönündeki agresif hamlesinin bir parçası olduğu belirtiliyor.
Meta, Llama 3.1 ailesinin yanı sıra, geliştiricilerin Llama’yı daha fazla yerde kullanmasını teşvik etmek için “referans sistemi” ve yeni güvenlik araçları olarak adlandırdığı bir şey yayınlıyor – Llama modellerinin öngörülemeyen veya istenmeyen şekillerde davranmasına neden olabilecek bu engelleme istemlerinden birkaçı. Şirket ayrıca, Llama modellerini ince ayarlamak, Llama ile sentetik veri oluşturmak ve “aracı” uygulamalar oluşturmak için kullanılabilen araçlar için yakında çıkacak bir API olan Llama Stack’i önizliyor ve yorum istiyor – Llama tarafından desteklenen ve bir kullanıcı adına eylemde bulunabilen uygulamalar.
“[What] Geliştiricilerden, gerçekte nasıl dağıtılacağını öğrenmeye ilgi duyduklarını defalarca duyduk [Llama models] Srinivasan, “Üretimdeyiz” dedi. “Bu yüzden onlara bir sürü farklı araç ve seçenek sunmaya çalışıyoruz.”
Pazar payı için oyna
Meta CEO’su Mark Zuckerberg, bu sabah yayınladığı açık mektupta, yapay zeka araçlarının ve modellerinin dünya çapında daha fazla geliştiricinin eline ulaştığı ve insanların yapay zekanın “faydalarına ve fırsatlarına” erişebildiği bir gelecek vizyonunu ortaya koydu.
Mektupta Zuckerberg’in bu araç ve modellerin Meta tarafından üretilmesi yönündeki isteği çok hayırseverce dile getirilmiş olsa da, bu isteğin üstü kapalı bir şekilde dile getirildiği görülüyor.
Meta, OpenAI ve Anthropic gibi şirketleri yakalamak için yarışıyor ve denenmiş ve doğru bir strateji kullanıyor: Bir ekosistemi desteklemek için araçları ücretsiz olarak verin ve sonra yavaş yavaş ekleyin ürünler ve hizmetler, bazıları ücretli, üstelik. Harcama milyonlarca dolar daha sonra meta haline getirebileceği modellerde, Meta rakiplerinin fiyatlarını düşürme ve şirketin AI versiyonunu geniş çapta yayma etkisine de sahiptir. Ayrıca şirketin açık kaynak topluluğundan gelen iyileştirmeleri gelecekteki modellerine dahil etmesine olanak tanır.
Llama kesinlikle geliştiricilerin dikkatini çekiyor. Meta, Llama modellerinin 300 milyondan fazla kez indirildiğini ve şu ana kadar 20.000’den fazla Llama türevi modelin oluşturulduğunu iddia ediyor.
Yanlış anlaşılmasın, Meta’nın oyunu devam ediyor. Harcıyor Milyonlarca düzenleyicileri “açık” üretken AI’nın tercih edilen çeşidine ikna etmek için lobi faaliyetlerinde bulunuyor. Llama 3.1 modellerinin hiçbiri, günümüzün üretken AI teknolojisindeki, bir şeyleri uydurma ve sorunlu eğitim verilerini tekrarlama eğilimi gibi, çözümsüz sorunları çözmüyor. Ancak Meta’nın temel hedeflerinden birini ilerletiyorlar: üretken AI ile eşanlamlı hale gelmek.
Bunun bir bedeli var. Araştırma makalesinde, ortak yazarlar — Zuckerberg’in Son Yorumlar — Meta’nın sürekli büyüyen üretken AI modellerinin eğitimiyle ilgili enerjiyle ilgili güvenilirlik sorunlarını tartışın.
“Eğitim sırasında, on binlerce GPU aynı anda güç tüketimini artırabilir veya azaltabilir, örneğin tüm GPU’ların kontrol noktası veya toplu iletişimlerin bitmesini beklemesi veya tüm eğitim işinin başlatılması veya kapatılması nedeniyle,” diye yazıyorlar. “Bu gerçekleştiğinde, veri merkezindeki güç tüketiminde onlarca megavat mertebesinde anlık dalgalanmalara neden olabilir ve güç şebekesinin sınırlarını zorlayabilir. Gelecekte, daha da büyük Llama modelleri için eğitimi ölçeklendirirken bu bizim için devam eden bir zorluktur.”
Bu daha büyük modellerin eğitilmesinin daha fazla kamu hizmeti kuruluşunu çalışmaya zorlamayacağını umuyoruz. Çevrede eski kömür yakıtlı elektrik santralleri var.