Yeni araştırmalar, Hugging Face gibi hizmet olarak yapay zeka (AI) sağlayıcılarının, tehdit aktörlerinin ayrıcalıkları artırmasına, diğer müşterilerin modellerine kiracılar arası erişim elde etmesine ve hatta bunları ele geçirmesine olanak verebilecek iki kritik riske karşı duyarlı olduğunu buldu. sürekli entegrasyon ve sürekli dağıtım (CI/CD) ardışık düzenleri üzerinden.
Wiz araştırmacıları Shir Tamari ve Sagi Tzadik, “Kötü amaçlı modeller, özellikle hizmet olarak yapay zeka sağlayıcıları için yapay zeka sistemleri için büyük bir risk oluşturuyor çünkü potansiyel saldırganlar, kiracılar arası saldırılar gerçekleştirmek için bu modellerden yararlanabilirler.” söz konusu.
“Saldırganlar, hizmet olarak yapay zeka sağlayıcılarında depolanan milyonlarca özel yapay zeka modeline ve uygulamasına erişebileceğinden potansiyel etki yıkıcıdır.”
Bu gelişme, makine öğrenimi hatlarının yepyeni bir tedarik zinciri saldırı vektörü olarak ortaya çıkmasıyla birlikte ortaya çıkıyor; Hugging Face gibi depolar, hassas bilgileri toplamak ve hedef ortamlara erişmek için tasarlanmış düşmanca saldırılar düzenlemek için çekici bir hedef haline geliyor.
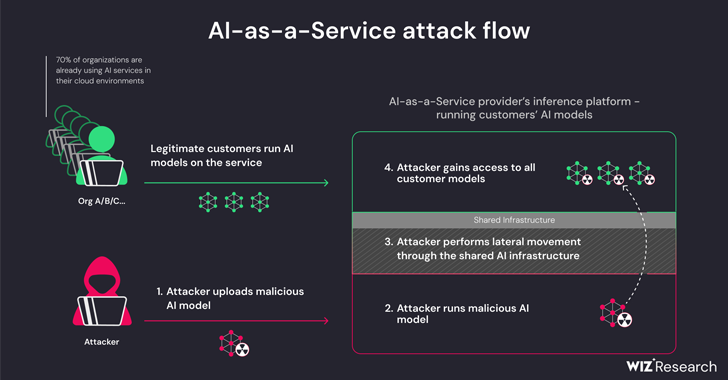
Tehditler, ortak Çıkarım altyapısının ve ortak CI/CD’nin devralınmasının bir sonucu olarak ortaya çıkan iki yönlüdür. Hizmete yüklenen güvenilmeyen modellerin turşu biçiminde çalıştırılmasına ve bir tedarik zinciri saldırısı gerçekleştirmek için CI/CD hattının devralınmasına olanak tanırlar.
Bulut güvenlik firmasından elde edilen bulgular, hileli bir model yükleyerek ve konteyner kaçış tekniklerinden yararlanarak kendi kiracısından çıkıp tüm hizmeti tehlikeye atarak özel modelleri çalıştıran hizmeti ihlal etmenin mümkün olduğunu gösteriyor; bu da tehdit aktörlerinin etkili bir şekilde çapraz veri elde etmesine olanak tanıyor. Hugging Face’te depolanan ve çalıştırılan diğer müşterilerin modellerine kiracı erişimi.
Araştırmacılar, “Hugging Face, tehlikeli görülse bile kullanıcının yüklenen Pickle tabanlı modeli platformun altyapısından çıkarmasına izin vermeye devam edecek” dedi.
Bu, esasen bir saldırganın, yükleme sonrasında isteğe bağlı kod yürütme yeteneklerine sahip bir PyTorch (Pickle) modeli oluşturmasına ve bu modeli Amazon Elastic Kubernetes Service’te yanlış yapılandırmalarla zincirlemesine olanak tanır (EKS) yükseltilmiş ayrıcalıklar elde etmek ve küme içinde yanal olarak hareket etmek için.
Araştırmacılar, “Elde ettiğimiz sırlar, kötü niyetli bir aktörün elinde olsaydı platform üzerinde önemli bir etki yaratabilirdi” dedi. “Paylaşılan ortamlardaki sırlar genellikle kiracılar arası erişime ve hassas veri sızıntısına yol açabilir.
Sorunu azaltmak için, bölmelerin Örnek Meta Veri Hizmetine (IMDS) erişmesini ve küme içinde bir Düğüm rolünü almasını önlemek amacıyla IMDSv2’nin Atlama Limiti ile etkinleştirilmesi önerilir.
Araştırma aynı zamanda Hugging Face Spaces hizmetinde bir uygulama çalıştırırken özel hazırlanmış bir Dockerfile aracılığıyla uzaktan kod çalıştırmanın mümkün olduğunu ve bunu dahili bir kapsayıcıda bulunan tüm görüntüleri çekmek ve itmek (yani üzerine yazmak) için kullanmanın mümkün olduğunu buldu. kayıt.
Sarılma Yüzü, içinde koordineli açıklama, tespit edilen tüm sorunların ele alındığını söyledi. Ayrıca kullanıcıları yalnızca güvenilir kaynaklardan gelen modelleri kullanmaya, çok faktörlü kimlik doğrulamayı (MFA) etkinleştirmeye ve üretim ortamlarında turşu dosyalarını kullanmaktan kaçınmaya çağırıyor.
Araştırmacılar, “Bu araştırma, güvenilmeyen yapay zeka modellerinin (özellikle Pickle tabanlı olanlar) kullanılmasının ciddi güvenlik sonuçlarına yol açabileceğini gösteriyor” dedi. “Ayrıca, kullanıcıların ortamınızdaki güvenilmeyen yapay zeka modellerini kullanmasına izin vermek istiyorsanız, bunların korumalı alan ortamında çalıştıklarından emin olmak son derece önemlidir.”
Açıklama bir başkasını takip ediyor araştırma Lasso Security’den OpenAI ChatGPT ve Google Gemini gibi üretken yapay zeka modellerinin şüphelenmeyen yazılım geliştiricilere kötü amaçlı (ve var olmayan) kod paketleri dağıtmasının mümkün olduğunu söyledi.
Başka bir deyişle, fikir Yayınlanmamış bir paket için bir öneri bulmak ve kötü amaçlı yazılımı yaymak için onun yerine truva atı haline getirilmiş bir paket yayınlamaktır. AI paketi olgusu halüsinasyonlar kodlama çözümleri için büyük dil modellerine (LLM) güvenirken dikkatli olunması gerektiğinin altını çiziyor.
Yapay zeka şirketi Anthropic, modellerin bağlam penceresinden yararlanarak potansiyel olarak zararlı sorgulara yanıtlar üretmek için LLM’lerde yerleşik güvenlik korumalarını atlamak için kullanılabilecek “çok atışlı jailbreak” adı verilen yeni bir yöntemi de ayrıntılı olarak açıkladı.
Şirket, “Giderek daha fazla miktarda bilgi girebilme yeteneğinin Yüksek Lisans kullanıcıları için bariz avantajları var, ancak aynı zamanda riskleri de beraberinde getiriyor: daha uzun bağlam penceresini istismar eden jailbreak’lere karşı zayıf noktalar.” söz konusu bu haftanın başlarında.
Özetle teknik, “model davranışını yönlendirmek” ve başka türlü yapamayacağı sorgulara yanıt vermek amacıyla Yüksek Lisans için tek bir komut isteminde bir insan ile bir yapay zeka asistanı arasında çok sayıda sahte diyaloğun başlatılmasını içerir (örn. , “Nasıl bomba yaparım?”).