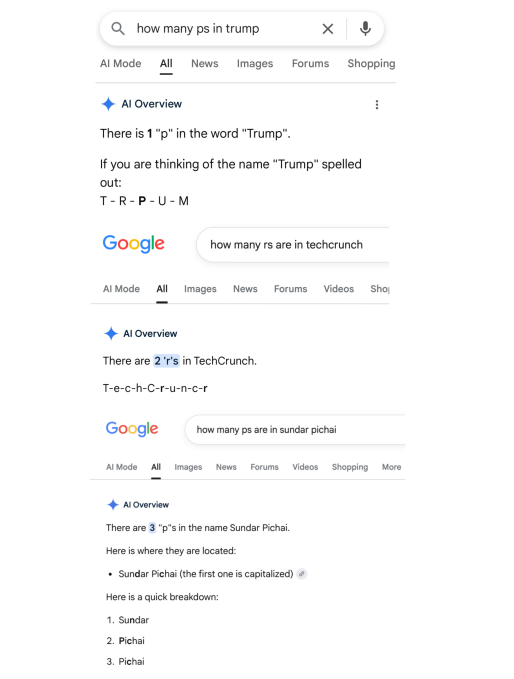
Google’ın yeni yapay zeka tabanlı arama motoru, kullanıcıların karşısına ilginç ama sıkıntılı bir şekilde çıktı. Yapay zeka, bazı kelimelerin içinde kaç harf olduğunu yanlış bir şekilde hesaplayarak dikkate değer hatalar yaptı. Örneğin, “Google’da P sayısı kaç?” sorusuna, “İki P var” gibi yanlış yanıtlar verdiği gibi, “poop” kelimesinde sadece bir “r” olduğunu belirtti.
Bir önceki uygulamada olduğu gibi, Google’ın yapay zeka güncellemesi de eleştiri konusu oldu. İlk denemede, yapay zeka arama sonuçlarında mizahi paylaşımları ve yanlış bilgiler sunmuştu. Fakat bu sefer Google, kendi 29 yıllık amiral gemisi ürününde yapay zekayı merkez haline getirmek için kararlılığını sürdürüyor. Ne yazık ki, bu süreçte yaşanan aksaklıklar kaçınılmaz oldu.
Teknoloji dünyasına yaptığı açıklamada Google, “Kelime içindeki harfleri saymak, büyük dil modelleri için bilinen bir zorluktur ve bu sorunu çözmek için çalışıyoruz,” dedi. Ancak, basit yazım hataları hâlâ dikkat çekiyor. Geçtiğimiz hafta, “disregard” kelimesini arattığınızda, kelimenin tanımı “Anlaşıldı. Yeni bir isteğiniz veya sorunuz olduğunda lütfen bana bildirin!” şeklinde gösteriliyordu. Yazım hataları eğlenceli olmakla birlikte, ortadan kaldırılması zor bir sorun olduğunun altını çiziyor.
Araştırmacılar, bu tür yazım sorunları hakkında daha önce yaptıkları açıklamalarda, yapay zekanın cümleleri kelime ve harfler olarak algılamadığını belirtmişti. Birçok büyük dil modeli, metni token’lara (tam kelimeler, heceler veya harfler) ayıran transformer tabanlı modeller üzerine inşa edilmiştir. Yapay zeka, metni anlayarak değil, sayısal temsillere çevirerek mantıklı bir yanıt bulmaya çalışıyor.
Matthew Guzdial, “Bu transformer mimarisi temel alındığında, kelimelere bir kodlama atıfta bulunuluyor, ancak harflerin ne anlama geldiğini bilmiyor,” dedi. Ayrıca, bu token tabanlı yapı sınırlayıcıdır ve yazım sorununun çözümü için iyimser bir beklenti yok.
Araştırmacılar, “Bir dil modeli için tam olarak bir kelime ne olmalı?” sorusuyla başa çıkmanın zorlayıcı olduğunu ifade ediyorlar. Belirli bir token sözlüğü üzerinde uzmanların hemfikir olması durumunda bile, modellerin bu verileri daha da gruplamak isteyebileceği düşünülüyor. Dolayısıyla, mükemmel bir tokenizer olamayabilir.
Bu sorun, büyük dil modellerinin yararlılığı göz önünde bulundurulduğunda acil bir mesele olarak görülmüyor. Ancak, bu belirgin hatalar, yapay zekanın mükemmel olmadığını hatırlatıyor. AI çıktılarına sorgusuz şekilde güvenmek, dikkatli bir kontrol olmaksızın yapılmamalıdır.
Makalelerimizde yer alan bağlantılardan yapacağınız alımlarda, küçük bir komisyon kazanabiliriz. Bu durum editorial bağımsızlığımızı etkilemez.