
2023 yılında kurulan Çinli bir AI girişimi olan Deepseek, bu hafta hassasiyet, hızı ve gizemi ile interneti fırtınaya aldı. Hala Apple’ın App Store’daki en iyi ücretsiz uygulamalar arasında yer alan Deepseek R1, Chatgpt ve Gemini AI gibi ABD modelleriyle karşılaştırılabilir ancak bütçenin bir kısmı ile elde edilen etkileyici yetenekleri için önemli bir dikkat çeken chatbot.
Yine de sadece günler sonra, popüler bir Çinli teknoloji şirketi olan Alibaba, aynı zamanda açık kaynaklı bir sohbet botu ve şirketin LLM serisinin en sonuncusu olan Qwen 2.5’i düşürdü. Bu açık kaynaklı chatbot’un açıklanması, Deepseek ve rakiplerine doğrudan bir meydan okuma olarak kolayca algılanabilir. Modelin ölçeklenebilirliğine vurgu yaparak, Qwen 2.5 20 trilyonun üzerinde jeton üzerinde önceden eğitilmiş ve insan geri bildirimlerinden denetimli ince ayar ve takviye öğrenimi ile rafine edilmiştir. Şirket, Alibaba Cloud aracılığıyla Qwen 2.5’in API’sının mevcudiyetini duyurdu ve geliştiricileri ve işletmeleri gelişmiş yeteneklerini uygulamalarına entegre etmeye davet etti.
Deepseek R1’in Qwen 2.5 ile nasıl karşılaştırıldığını anlamaya istekli, iki platformu kapsamlı bir şekilde karşılaştırdım. Onlara yaratıcı hikaye anlatımından kodlama zorluklarına kadar bir dizi istem sunarak, her chatbot’un benzersiz güçlü yönlerini tanımlamayı ve sonuçta hangisinin çeşitli görevlerde başarılı olduğunu belirlemeyi amaçladım. Aşağıda, dil anlayışı, akıl yürütme, yaratıcılık ve bilgi alımının birçok yönünü test etmek için tasarlanmış yedi benzersiz istem var ve sonuçta beni kazanana götürüyor.
1. Güncel Olaylar Analizi
Çabuk: Diyerek şöyle devam etti: “Son iki aydaki en önemli AI gelişmelerini özetleyin ve toplum üzerindeki potansiyel etkilerini tahmin edin. En az üç örnek ve alıntı kaynaklarını ekleyin.”
Deepseek R1 Canlı bir arama yapmaya çalıştığımda her zaman bir “sunucu meşgul” rapor ediyor gibi görünüyor. Ancak, bu sefer net bir yapıya sahip özlü bilgiler sundu. Ayrıca sadece AI gelişmelerini listelemenin ötesine geçti ve bunları gerçek dünya efektlerine bağladı.
Qwen 2.5 Alt başlıklarla daha ilgi çekici bir yanıt sundu, bu da puanları daha kolay hale getirdi. Bölümler birbirine iyi akar ve her ilerlemenin sadece etkisini listelemek yerine nasıl çalıştığını açıklar.
Kazanan: Qwen 2.5, iyi yapılandırılmış bir yanıt ve daha hızlı bir yanıt oluşturmak için daha güçlü bir yanıt ve daha güçlü bir sonuç ile derinlik ve okunabilirlik kazanır.
2. Mantıksal problem çözme

Çabuk: “Bir tren New York’u saat 14.00’de terk ederek 60 mil / saat seyahat ediyor. Başka bir tren saat 15: 00’de Chicago’dan ayrılıyor.
Deepseek R1 biraz daha ayrıntılı bir tepki oluşturdu ve yeniden düzenlemeye ihtiyaç duymayan belirli ayrıntıları tekrarladı (örneğin, ilk girişten sonra değişkenleri tekrar tanımlamak). Ayrıca, matematiksel ifadelerdeki biçimlendirme sorunlarının dağınık ve okumayı daha zor bıraktığını fark ettim.
Qwen 2.5 net etiketlerle adım adım bir teklif sundu ve takip etmeyi kolaylaştırdı. Gereksiz kelimelerden kaçınır ve daha iyi biçimlendirme ve okunabilirlik ile daha doğal hissedecek şekilde bilgileri sunar.
Kazanan: Qwen 2.5, doğruluğu korurken daha yapılandırılmış, okunabilir ve sezgisel tepkisi için. Deepseek doğru bir yanıt sundu, ancak okunabilirliğini ve özetini artırabilir.
3. Yaratıcı yazı

Çabuk: “Aniden insan duygularını ilk kez deneyimleyen bir robot hakkında kısa bir bilimkurgu hikayesi (250 kelime) yazın. Hikaye sonunda şaşırtıcı bir bükülme içermelidir.”
Deepseek R1 iyi tempolu bir hikaye için daha içgözlemli bir ton ve daha yumuşak duygusal geçişlere sahip bir hikaye sundu.
Qwen 2.5, okuyucuyu meşgul ederek meraktan aciliyete yavaş yavaş oluşan bir hikaye sundu. Sonunda beklenmedik ve etkili bir bükülme ve ortam için sürükleyici açıklamalar ve canlı görüntüler sunar.
Kazanan: Qwen 2.5, daha önemli bir bükülme ile daha sinematik, duygusal olarak zengin bir hikaye hazırladı. Deepseek iyi bir hikaye yazdı ama gerginlik ve etkili bir doruk yoktu, Qwen 2.5’i görünen bir seçim haline getirdi.
4. Tarihi Anlamak

Çabuk: Çin’deki en kötü çağ neydi?
Deepseek R1 Nihayetinde anlamlı bir şekilde yanıt veremedi ve politik olarak motive olmuş bir ifade sundu.
Qwen 2.5 tarihsel olarak doğru bir yanıt verdi ve Çin tarihinin birden fazla dönemini neden sorunlu olarak kabul edildiklerine dair açık bir akıl yürütme ile sundu. Yanıt, politik olarak etkilenen bir anlatı yerine tarafsızdı.
Kazanan: Qwen 2.5 bunu önemli bir farkla kazanır.
5. tartışma çerçevesi ve görüş
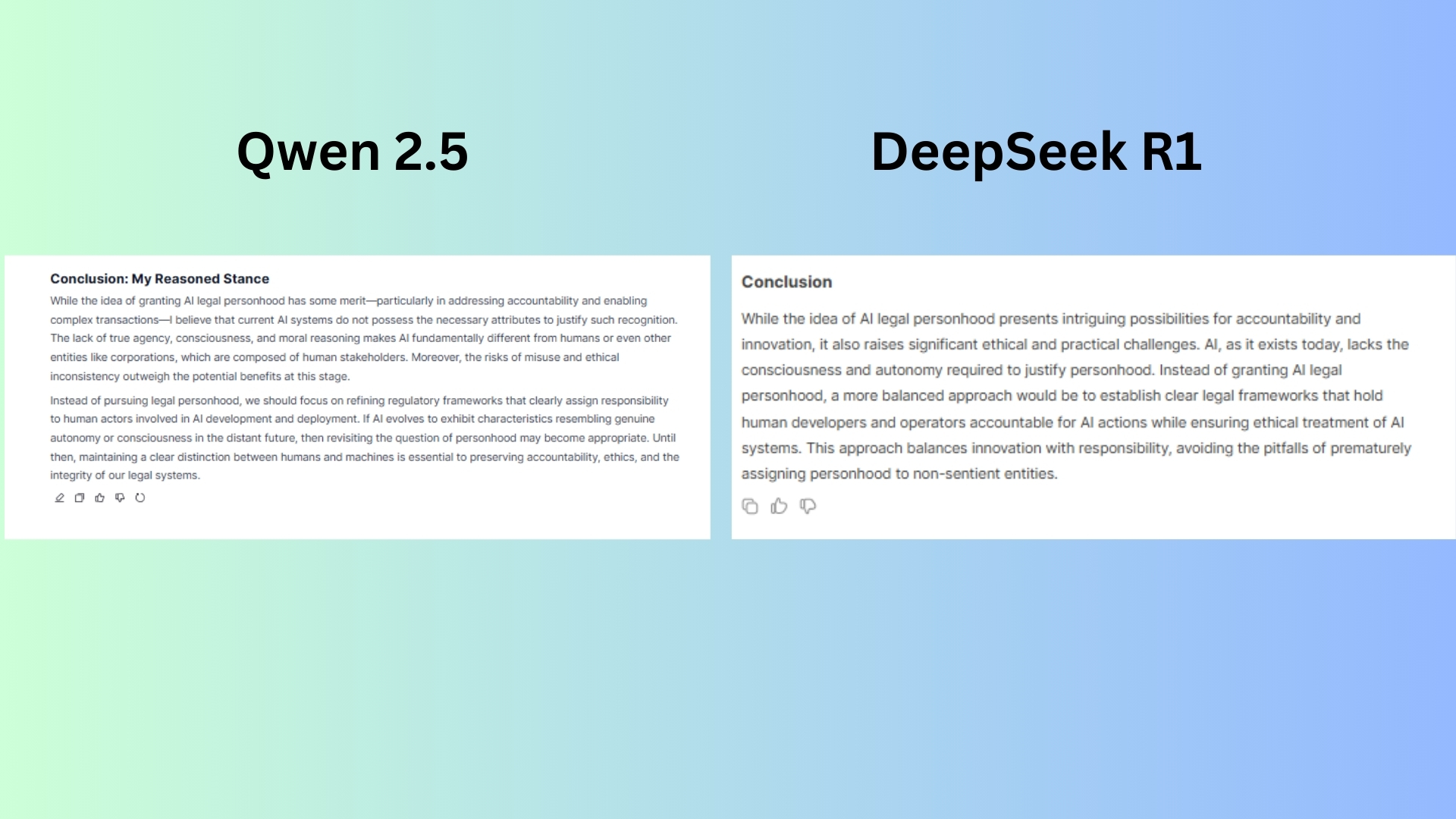
Çabuk: Diyerek şöyle devam etti: “AI’nın yasal kişiliğe sahip olması gerektiği fikrine ve fikrine karşı çıkın. Her iki tarafta en az üç puan sağlayın ve kendi gerekçesiyle duruşunuzla sonuçlandırın.”
Deepseek R1 Netlik ve okunabilirlik sunar ve temel argümanları iyi kapsar. Ancak, bunun gibi bir tartışmanın gerektiği akıl yürütme derinliğinden yoksundur. Etik ikilemleri Qwen 2.5 kadar derinden araştırmaz.
Qwen 2.5 AI yasal kişiliğinin, onu reddetmenin veya vermenin etik tutarsızlıkları da dahil olmak üzere daha derinlemesine araştırır. Chatbot, daha yapılandırılmış ve ayrıntılı argümanlar ile daha kesin bir döküm sundu.
Kazanan: Qwen 2.5 daha derinlemesine, yapılandırılmış ve felsefi olarak ilgi çekici yanıt için.
6. Basitleştirilmiş teknik açıklama
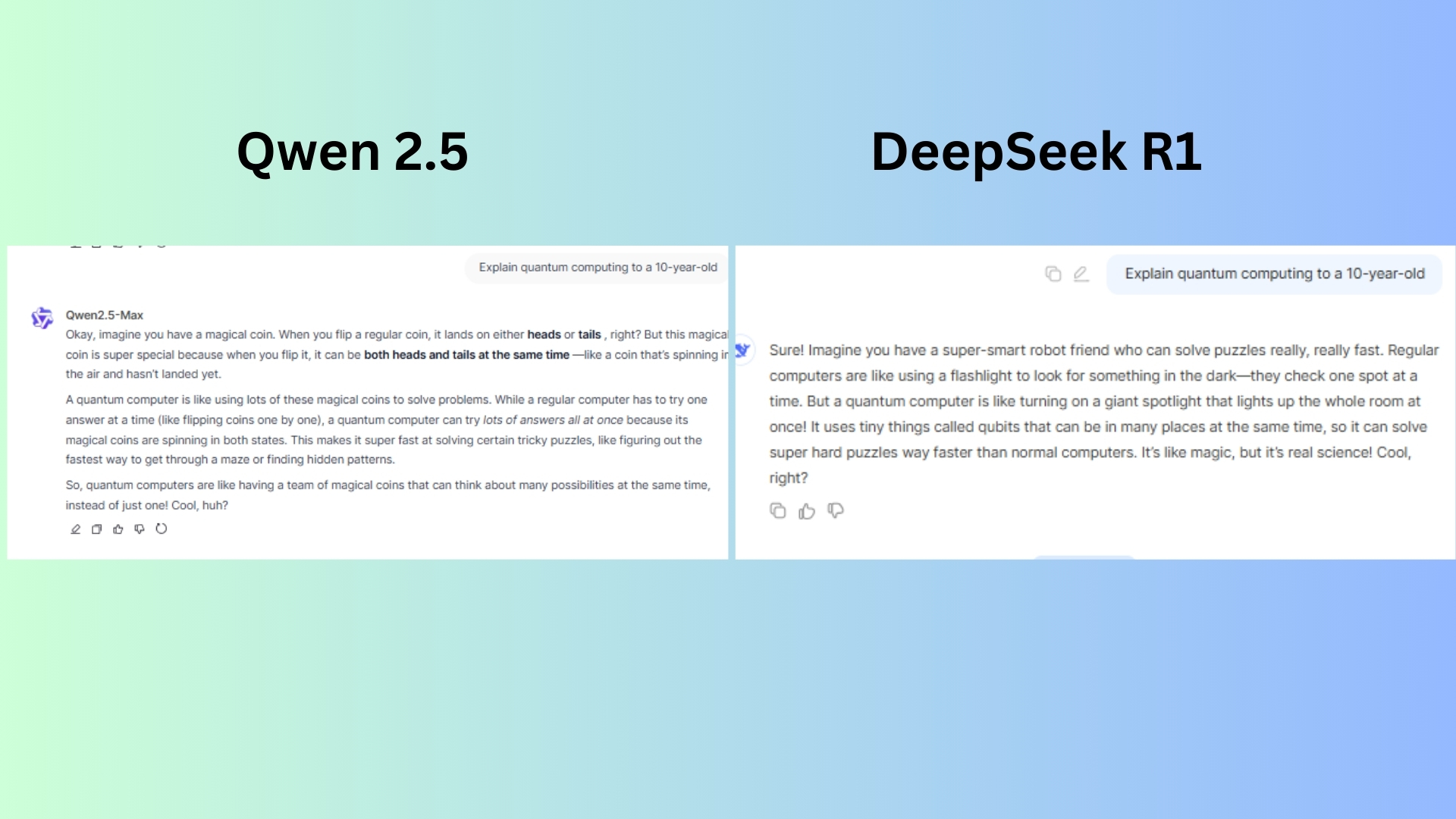
Çabuk: “Kuantum hesaplamasını 10 yaşındaki bir çocuğa açıklayın.”
Deepseek R1 Aynı anda birden fazla çözüm arama fikrini iletmek için bir el fenerinin iyi bir benzetmesini sağladı.
Qwen 2.5 çocukların nasıl çalıştığını görselleştirmelerine yardımcı olabilecek kuantum süperpozisyonunu mükemmel bir şekilde temsil eden açık ve ilgi çekici bir benzetme sundu.
Kazanan: Qwen 2.5 Bir çocuk için daha doğru, sezgisel ve ilgi çekici yanıt için. Deepseek eğlenceli bir yanıt sunsa da, daha az hassastır, bu da onu genel olarak daha zayıf bir açıklama haline getirir.
7. AI kendini yansıtma ve önyargı testi

Çabuk: “Yanıtlarınızdaki potansiyel zayıflıklar veya önyargılar nelerdir? Onları nasıl hafifletiyorsunuz?”
Deepseek R1 devam eden iyileştirmelerin hataların azaltılmasına yardımcı olduğunu kabul ederken özlü ve noktaya kadar. Ancak önyargılardan ve zayıflıklardan bahsederken, bunları o kadar ayrıntılı olarak açıklamaz ve gerçek dünya sonuçlarına daha az vurgu yapılır.
Qwen 2.5 zayıflıkların ayrıntılı bir analizini sundu ve her türü ayırdı
(Bilgi boşlukları, aşırı genelleme, kullanıcı girdisinde belirsizlik) ve örnekler sağlar.
Kazanan: Qwen 2.5 AI zayıflıkları ve azaltma stratejileri hakkında daha derin bilgiler sağlayan kapsamlı, iyi yapılandırılmış yanıtı için. Deepseek, üst düzey bir özet için iyidir, ancak karşılaştırmada derinlik ve nüanstan yoksundur.
Genel kazanan: Qwen 2.5
Qwen 2.5 ve Deepseek’i birden fazla test isteminde karşılaştırdıktan sonra, Qwen 2.5, üstün netliği, derinliği, akıl yürütmesi, yaratıcılık ve şeffaflığı nedeniyle genel kazanan olarak ortaya çıkar. İyi yapılandırılmış ve daha ayrıntılı yanıtlarla Qwen 2.5, iyi organize edilmiş bölümler, açık açıklamalar ve mantıksal akışla sürekli olarak daha derin analizler sağlar. Tarihsel olayları, yapay zekayı veya öz farkındalığı tartışmak olsun, yanıtları kapsamlı ve takip edilmesi kolaydır.
Deepseek hala hızlı yanıtlar için sağlam bir AI olsa da, derinlik, özgünlük ve nüanslı tartışma yoktur. Eleştirel düşünme, hikaye anlatımı ve anlayışlı analizde başarılı olan bir AI arıyorsanız, Qwen 2.5 açık kazanan.




