
AMD’nin sahip olduğu ilk küçük dil modelini tanıttıYapay zeka yeteneklerini güçlendirmek için spekülatif kod çözmeyi kullanan AMD-135M, sonuçta gelişmiş bir teknoloji sürecine yol açıyor.
AMD, Yapay Zeka Modeli Grubuna Girmeye Karar Verdi ve Token Üretiminde Daha Verimli Olan Küçük, Büyük Bir Dil Modelini Ortaya Çıkardı
[Press Release]: Yapay zekanın sürekli gelişen ortamında, GPT-4 ve Llama gibi büyük dil modelleri (LLM’ler), doğal dil işleme ve oluşturma konusundaki etkileyici yetenekleri nedeniyle büyük ilgi topladı.
Bununla birlikte, küçük dil modelleri (SLM’ler), yapay zeka modeli topluluğunda belirli kullanım durumları için benzersiz bir avantaj sunan önemli bir muadili olarak ortaya çıkıyor. AMD, Spekülatif Kod Çözme özellikli ilk küçük dil modeli AMD-135M’yi piyasaya sürmenin heyecanını yaşıyor. Bu çalışma, daha kapsayıcı, etik ve yenilikçi teknolojik ilerlemeye yol açacak, faydalarının daha geniş çapta paylaşılmasını ve zorlukların daha işbirlikçi bir şekilde ele alınmasını sağlamaya yardımcı olacak yapay zekaya yönelik açık bir yaklaşıma olan bağlılığı göstermektedir.
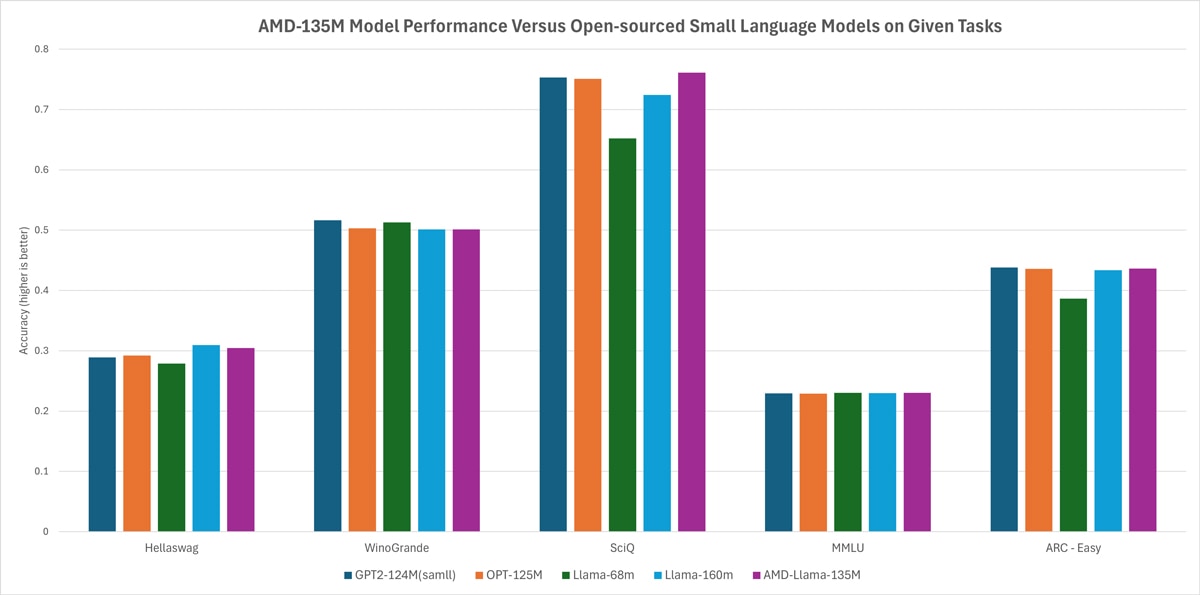
AMD-135M: İlk AMD Küçük Dil Modeli
AMD-135M, 670B token kullanan AMD Instinct™ MI250 hızlandırıcıları üzerinde sıfırdan eğitilen ve iki modele ayrılan Llama ailesi için ilk küçük dil modelidir: AMD-Llama-135M ve AMD-Llama-135M-code.
- Ön eğitim: AMD-Llama-135M modeli, dört MI250 düğümü kullanılarak altı gün boyunca 670 milyar token genel veriyle sıfırdan eğitildi.
- Kod İnce Ayarı: AMD-Llama-135M kodu varyantına, aynı donanım üzerinde dört gün süren ek 20 milyar jeton kod verisi ile ince ayar yapıldı.
Bu modelin eğitim kodu, veri kümesi ve ağırlıkları açık kaynaklı olduğundan geliştiriciler modeli yeniden üretebilir ve diğer SLM’lerin ve LLM’lerin eğitilmesine yardımcı olabilir.
Spekülatif Kod Çözme ile Optimizasyon
Büyük dil modelleri genellikle çıkarım için otoregresif bir yaklaşım kullanır. Bununla birlikte, bu yaklaşımın önemli bir sınırlaması, her ileri geçişin yalnızca tek bir jeton oluşturabilmesi, bunun da düşük bellek erişim verimliliğine yol açması ve genel çıkarım hızını etkilemesidir.
Spekülatif kod çözmenin ortaya çıkışı bu sorunu çözdü. Temel prensip, daha büyük hedef model tarafından doğrulanan bir dizi aday token oluşturmak için küçük bir taslak modelin kullanılmasını içerir. Bu yaklaşım, her ileri geçişin performanstan ödün vermeden birden fazla belirteç oluşturmasına olanak tanır, böylece bellek erişim tüketimini önemli ölçüde azaltır ve çeşitli büyüklüklerde hız iyileştirmelerine olanak tanır.
Çıkarım Performansı Hızlandırması

CodeLlama-7b için taslak model olarak AMD-Llama-135M kodunu kullanarak, veri merkezi için MI250 hızlandırıcıda ve AI PC için Ryzen™ AI işlemcide (NPU’lu) spekülatif kod çözme ile ve spekülatif kod çözme olmadan çıkarım performansını test ettik. Taslak model olarak AMD-Llama-135M kodunu kullanarak test ettiğimiz belirli yapılandırmalar için Instinct MI250 hızlandırıcı Ryzen AI CPU’da bir hızlanma gördük.[2]ve Ryzen AI NPU’da[2] spekülatif kod çözme olmadan çıkarıma karşı.[3] AMD-135M SLM, seçkin AMD platformlarında hem eğitimi hem de çıkarımı kapsayan uçtan uca bir iş akışı oluşturur.