
12 Eylül’de OpenAI, karmaşık akıl yürütmeyi gerçekleştirmek için takviyeli öğrenme kullanılarak eğitilen yeni bir büyük dil modeli olan OpenAI o1’i tanıttı. Bu model, kullanıcıya yanıt vermeden önce uzun bir “düşünce zinciri” oluşturabilmesi, onu önceki modellere göre daha gelişmiş hale getiriyor.
OpenAI o1, rekabetçi programlamada (Codeforces) yüzde 89’luk dilimde yer alıyor ve ABD Matematik Olimpiyatları (AIME) elemelerinde Amerika Birleşik Devletleri’ndeki en iyi 500 “öğrenci” arasında yer alıyor. Aynı zamanda Fizik, Biyoloji ve Kimya (GPQA) Problem Testinde doktora düzeyindeki doğruluğu da aşmaktadır.
OpenAI, ChatGPT’de ve API kullanıcıları için kullanılmak üzere OpenAI o1 önizleme modelinin erken bir sürümünü yayınladı. Bu model, çeşitli makine öğrenimi sınavlarında ve karşılaştırmalı değerlendirmelerde test edilmiş olup, önceki GPT-4o modeline kıyasla akıl yürütmede önemli bir iyileşme göstermiştir.
OpenAI, modeli matematik, fizik, biyoloji, kimya ve programlama problemleri dahil olmak üzere çeşitli problemler üzerinde test etti. Sonuçlar, OpenAI o1’in çoğu akıl yürütme görevinde önceki GPT-4o modelinden önemli ölçüde daha iyi performans gösterdiğini gösterdi.
2024 AIME sınavlarında GPT-4o sorunların ortalama yalnızca %12’sini (1,8/15) çözdü. OpenAI o1, görev başına bir örnekle ortalama %74 (11,1/15), 64 örnek arasında fikir birliğiyle %83 (12,5/15) ve öğrenilen puanlama işlevini kullanarak 1000 örneği yeniden sıralarken %93 (13,9/15) elde etti.
Şirket ayrıca OpenAI o1’i kimya, fizik ve biyoloji alanındaki bilgileri test eden zorlu bir zeka testi olan GPQA elması üzerinde derecelendirdi. Modelleri insanlarla karşılaştırmak için OpenAI, GPQA elmas sorularını yanıtlamak üzere doktora düzeyindeki uzmanları işe aldı. Sonuçlar, OpenAI o1’in uzmanlardan daha iyi performans gösterdiğini ve bu testte bunu başaran ilk model olduğunu gösterdi.
Buna ek olarak OpenAI, modeli insan tercihleri üzerinde test etti ve veri analizi, kodlama ve matematik gibi akıl yürütme gerektiren kategorilerde OpenAI o1-önizlemenin GPT-4o’ya tercih edildiğini gösterdi. Ancak OpenAI o1-preview bazı doğal dil görevleri için tercih edilmiyor, bu da tüm kullanım durumları için uygun olmadığını gösteriyor.
OpenAI o1 ayrıca önemli jailbreak değerlendirmelerinde ve model güvenliği başarısızlık marjlarını değerlendirmek için dahili kıyaslamalarda da iyileştirilmiş performans gösterdi.
Şirket, yinelemeler devam ettikçe bu modelin geliştirilmiş versiyonlarını yayınlamayı planlıyor. Yeni “akıl yürütme” yeteneği, modelleri insani değerler ve ilkelerle uzlaştırma yeteneğini geliştirecek ve bilim, kodlama, matematik ve ilgili alanlarda yapay zekanın yeni kullanımlarının önünü açacak.
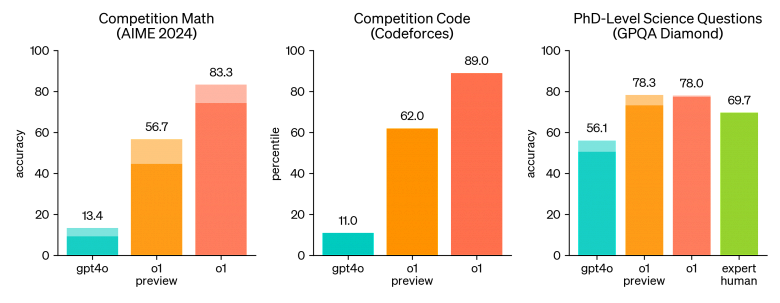
Akıl yürütmenin zincirlenmesi tutarlılık ve güvenlik için yeni fırsatlar sağlar. Şirket, örnek davranış politikalarını “düşünce zincirine” entegre etmenin, insani değer ve ilkeleri güvenilir bir şekilde öğretmenin etkili bir yolu olduğunu buldu. Şirket, bir modele güvenlik kurallarını ve bağlam içinde bunlar hakkında nasıl akıl yürütme yapılacağını öğreterek, akıl yürütme yeteneğinin modelin güvenilirliğini doğrudan artırdığına dair kanıt buldu.
İyileştirmelerini test etmek için OpenAI bir dizi güvenlik testi ve kırmızı ekip çalışması gerçekleştirdi [методология, используемая для тестирования и оценки безопасности, основная идея которой заключается в том, чтобы создать команду, которая будет играть роль «атакующей стороны», чтобы выявить уязвимости и слабые места в системе или стратегии] hazırlık çerçevesine uygun olarak konuşlandırılmadan önce. Sonuçlar, muhakeme zincirinin, değerlendirmelerdeki gelişmiş yeteneklere katkıda bulunduğunu gösterdi.
OpenAI, gizli düşünce zincirinin model izleme için eşsiz bir fırsat temsil ettiğine inanıyor. Eğer doğru ve anlaşılırsa modelin “düşünce sürecini” anlamamızı sağlar. Ancak bunun işe yaraması için modelin, düşüncelerini değiştirilmemiş bir biçimde ifade etmekte özgür olması gerekir; böylece OpenAI, düşünce zincirinde kullanıcının politikaları veya tercihleriyle herhangi bir uyum öğrenemez.
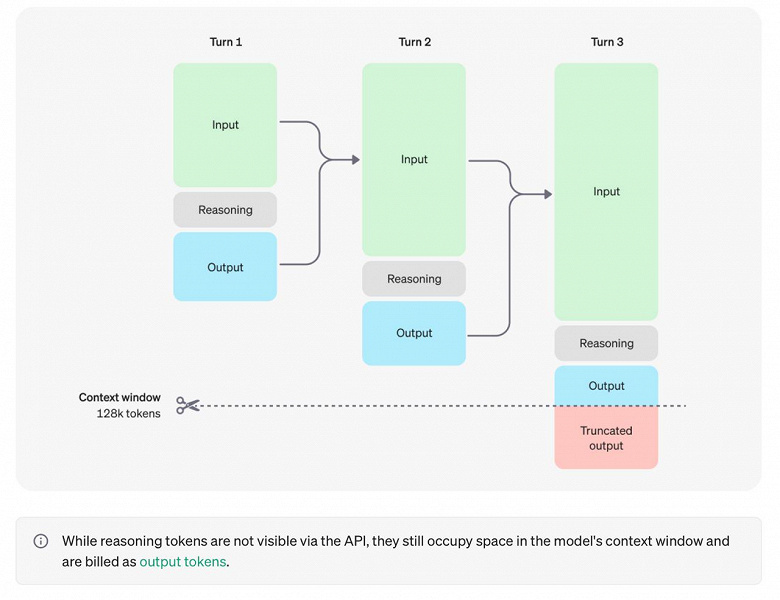
OpenAI, kullanıcı deneyimi, rekabet avantajı ve mantık zincirini izlemeye devam etme yeteneği dahil olmak üzere birçok faktörü değerlendirdikten sonra ham zincirleri kullanıcılara göstermemeye karar verdi. Şirket bu çözümün eksiklikleri olduğunu kabul ediyor. Bunu kısmen telafi etmek için OpenAI, modeli yanıttaki düşünce dizisinden yararlı fikirleri yeniden üretecek şekilde eğitir. o1 serisi modeller için OpenAI, “düşünce zincirinin” model tarafından oluşturulan özetini gösterir.
o1-önizleme modelinin maliyeti 1 milyon giriş tokenı için 15,00 USD ve 1 milyon çıkış tokenı için 60 USD’dir.
OpenAI o1, yapay zeka alanında ileriye doğru atılmış önemli bir adımı temsil ediyor. Bu model, muhakeme gerektiren karmaşık problemleri çözme yeteneğine sahiptir ve önceki modellere göre daha iyi performans gösterir. OpenAI bu modeli geliştirmeye devam etmeyi ve iyileştirilmiş versiyonları yayınlamayı planlıyor.