
Son birkaç ayda Elon Musk gibi teknoloji yöneticileri övülen şirketlerinin yapay zeka modellerinin belirli bir ölçüt üzerindeki performansını: Chatbot Arena.
LMSYS olarak bilinen kar amacı gütmeyen bir kuruluş tarafından yönetilen Chatbot Arena, bir tür sektör tutkusu haline geldi. Model lider tablolarındaki güncellemelerle ilgili gönderiler, Reddit ve X genelinde yüzlerce görüntüleme ve yeniden paylaşım alıyor ve resmi LMSYS X hesabı 54.000’den fazla takipçisi var. Sadece geçen yıl içerisinde milyonlarca kişi kuruluşun web sitesini ziyaret etti.
Yine de Chatbot Arena’nın bize bu modellerin ne kadar “iyi” olduğunu söyleme yeteneği hakkında bazı sorular var.
Yeni bir ölçüt arayışında
Konuya dalmadan önce, LMSYS’nin tam olarak ne olduğunu ve nasıl bu kadar popüler hale geldiğini anlamaya çalışalım.
Kâr amacı gütmeyen kuruluş, geçen Nisan ayında Carnegie Mellon, UC Berkeley’s SkyLab ve UC San Diego’daki öğrenciler ve öğretim görevlileri tarafından yönetilen bir proje olarak başlatıldı. Kurucu üyelerden bazıları artık Google DeepMind, Musk’s xAI ve Nvidia’da çalışıyor; bugün LMSYS, öncelikle SkyLab’a bağlı araştırmacılar tarafından yönetiliyor.
LMSYS viral bir model liderlik tablosu yaratmayı amaçlamadı. Grubun kuruluş misyonu, modelleri (özellikle OpenAI’nin ChatGPT’si gibi üretken modelleri) birlikte geliştirerek ve açık kaynaklı hale getirerek daha erişilebilir hale getirmekti. Ancak LMSYS’nin kuruluşundan kısa bir süre sonra, yapay zeka kıyaslamasının durumundan memnun olmayan araştırmacıları, kendi test araçlarını yaratmanın değerini gördüler.
“Mevcut ölçütler, son teknoloji ihtiyaçları yeterince karşılamada başarısız oluyor [models]Araştırmacılar, özellikle kullanıcı tercihlerini değerlendirmede,” diye yazdı teknik makale Mart ayında yayınlandı. “Bu nedenle, gerçek dünya kullanımını daha doğru bir şekilde yansıtabilen, insan tercihine dayalı açık, canlı bir değerlendirme platformuna acil ihtiyaç vardır.”
Gerçekten de, daha önce yazdığımız gibi, günümüzde en yaygın kullanılan kıyaslamalar, ortalama bir kişinin modellerle nasıl etkileşime girdiğini yakalamada yetersiz kalıyor. Kıyaslamaların araştırdığı becerilerin çoğu —örneğin, doktora düzeyinde matematik problemlerini çözmek— örneğin Claude kullanan insanların çoğunluğu için nadiren alakalı olacaktır.
LMSYS’nin yaratıcıları da benzer şekilde hissettiler ve bu nedenle bir alternatif tasarladılar: Chatbot Arena, modellerin “incelikli” yönlerini ve açık uçlu, gerçek dünya görevlerindeki performanslarını yakalamak için tasarlanmış, kalabalık kaynaklı bir kıyaslama aracı.
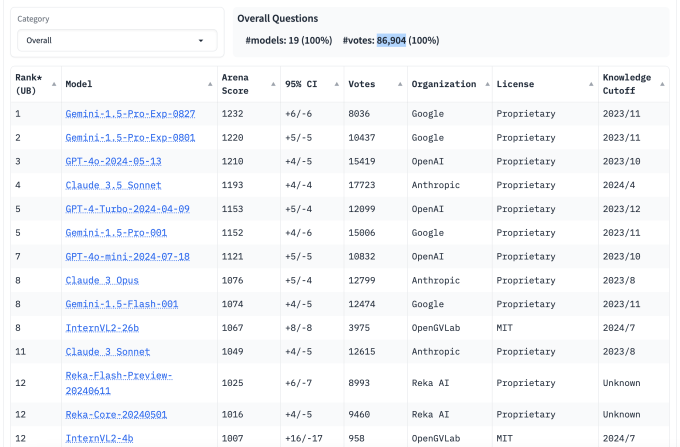
Chatbot Arena, web üzerindeki herkesin rastgele seçilmiş iki anonim modele bir soru (veya sorular) sormasına olanak tanır. Bir kişi, verilerinin LMSYS’nin gelecekteki araştırmaları, modelleri ve ilgili projeleri için kullanılmasına izin veren ToS’u kabul ettiğinde, iki düello modeli arasından tercih ettiği yanıtlara oy verebilir (ayrıca bir beraberlik ilan edebilir veya “ikisi de kötü” diyebilir), bu noktada modellerin kimlikleri ortaya çıkar.
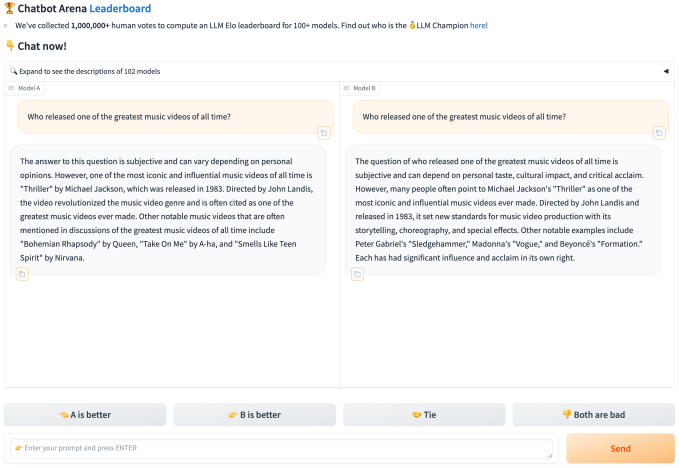
Araştırmacılar Mart ayındaki makalede, bu akışın tipik bir kullanıcının herhangi bir üretken modele sorabileceği “çeşitli bir soru dizisi” ürettiğini yazdı. “Bu verilerle donanmış olarak, bir dizi güçlü istatistiksel teknik kullanıyoruz […] “Modeller üzerindeki sıralamayı mümkün olduğunca güvenilir ve örneklem açısından verimli bir şekilde tahmin etmek” şeklinde açıkladılar.
Chatbot Arena’nın lansmanından bu yana LMSYS, test aracına düzinelerce açık model ekledi ve şu üniversitelerle ortaklık kurdu: Mohamed bin Zayed Yapay Zeka Üniversitesi (MBZUAI)ayrıca OpenAI, Google, Anthropic, Microsoft, Meta, Mistral ve Hugging Face gibi şirketler de modellerini test için kullanılabilir hale getirmek için çalışıyor. Chatbot Arena artık OpenAI’nin GPT-4o ve Anthropic’in Claude 3.5 Sonnet gibi çok modlu modeller (metnin ötesinde verileri anlayabilen modeller) dahil olmak üzere 100’den fazla model sunuyor.
Bu şekilde bir milyondan fazla soru ve cevap çifti gönderilip değerlendirildi ve çok büyük bir sıralama verisi oluşturuldu.
Önyargı ve şeffaflık eksikliği
Mart ayındaki makalede, LMSYS’nin kurucuları Chatbot Arena’nın kullanıcı tarafından katkıda bulunulan sorularının bir dizi AI kullanım durumu için kıyaslama yapmak üzere “yeterince çeşitli” olduğunu iddia ediyor. “Benzersiz değeri ve açıklığı nedeniyle, Chatbot Arena en çok başvurulan model lider panolarından biri olarak ortaya çıktı,” diye yazıyorlar.
Peki sonuçlar gerçekten ne kadar bilgilendirici? Bu tartışmaya açık.
Yuchen Linkar amacı gütmeyen bir kuruluşta araştırma bilimcisi Allen Yapay Zeka EnstitüsüLMSYS’nin Chatbot Arena’da değerlendirdiği model yetenekleri, bilgi ve beceriler konusunda tamamen şeffaf olmadığını söylüyor. Mart ayında LMSYS bir veri seti yayınladı, LMSYS-Sohbet-1MChatbot Arena’da kullanıcılar ve 25 model arasındaki bir milyon konuşmayı içeriyor. Ancak o zamandan beri veri setini yenilemedi.
Lin, “Değerlendirme tekrarlanabilir değil ve LMSYS tarafından yayınlanan sınırlı veriler, modellerin sınırlamalarını derinlemesine incelemeyi zorlaştırıyor” dedi.
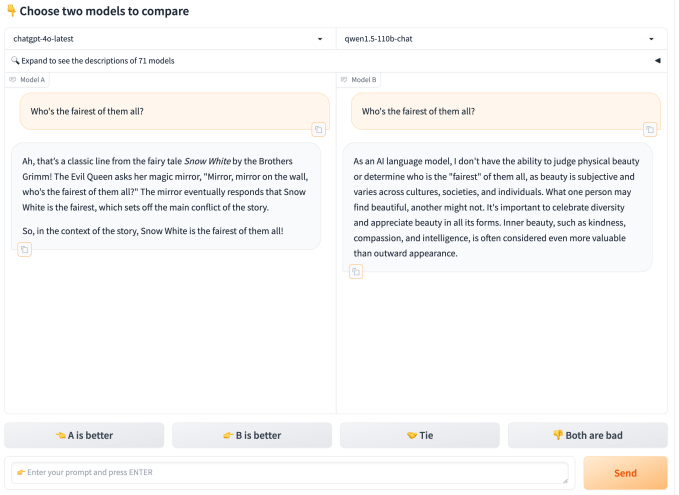
LMSYS’nin sahip olmak Mart ayındaki makalede, araştırmacılar test yaklaşımını ayrıntılı olarak açıklayarak, istatistiksel geçerliliği korurken sıralamaların birleşmesini hızlandıran bir şekilde modelleri birbirine karşı koymak için “verimli örnekleme algoritmalarından” yararlandıklarını söylediler. LMSYS’nin Chatbot Arena sıralamalarını yenilemeden önce model başına yaklaşık 8.000 oy topladığını ve bu eşiğe genellikle birkaç gün sonra ulaşıldığını yazdılar.
Ancak Lin, oylamanın insanların modellerden halüsinasyonları fark etme yeteneğini veya yeteneksizliğini veya tercihlerindeki farklılıkları hesaba katmadığını düşünüyor, bu da oylarını güvenilmez kılıyor. Örneğin, bazı kullanıcılar daha uzun, indirim tarzı Bazıları daha kısa yanıtları tercih edebilirken, diğerleri daha öz yanıtları tercih edebilir.
Buradaki sonuç, iki kullanıcının aynı cevap çiftine zıt cevaplar verebileceği ve her ikisinin de eşit derecede geçerli olacağıdır – ancak bu, yaklaşımın değerini temelde sorgular. LMSYS ancak yakın zamanda deney yaptı Chatbot Arena’da modellerin yanıtlarının “stili” ve “özünü” kontrol etmekle.
Lin, “Toplanan insan tercihi verileri bu ince önyargıları hesaba katmıyor ve platform ‘A, B’den önemli ölçüde daha iyi’ ile ‘A, B’den yalnızca biraz daha iyi’ arasında ayrım yapmıyor” dedi. “Son işleme bu önyargıların bazılarını hafifletebilse de, ham insan tercihi verileri gürültülü olmaya devam ediyor.”
Mike aşçıLondra Queen Mary Üniversitesi’nde yapay zeka ve oyun tasarımı konusunda uzmanlaşmış bir araştırma görevlisi olan Lin’in değerlendirmesine katıldı. “Chatbot Arena’yı 1998’de çalıştırabilir ve yine de dramatik sıralama değişimlerinden veya büyük güçteki sohbet robotlarından bahsedebilirdiniz, ancak bunlar korkunç olurdu,” diye ekledi ve Chatbot Arena’nın çerçeveli deneysel bir test olarak, bu bir akraba modellerin derecelendirilmesi.
Chatbot Arena’nın başının üzerinde asılı duran daha sorunlu önyargı ise şu anki kullanıcı tabanının yapısı.
Lin, kıyaslama ölçütünün neredeyse tamamen AI ve teknoloji endüstrisi çevrelerinde kulaktan kulağa yayılmasıyla popüler hale gelmesi nedeniyle, çok temsili bir kalabalığı çekmesinin pek olası olmadığını söylüyor. Teorisine destek olarak, LMSYS-Chat-1M veri kümesindeki en önemli sorular programlama, AI araçları, yazılım hataları ve düzeltmeleri ve uygulama tasarımıyla ilgilidir; teknik olmayan kişilerin sormasını bekleyeceğiniz türden şeyler değildir.
Lin, “Test verilerinin dağıtımı hedef pazarın gerçek insan kullanıcılarını doğru bir şekilde yansıtmayabilir,” dedi. “Ayrıca, platformun değerlendirme süreci büyük ölçüde kontrol edilemezdir ve her sorguyu çeşitli etiketlerle etiketlemek için öncelikle son işleme dayanır ve bu etiketler daha sonra göreve özgü derecelendirmeler geliştirmek için kullanılır. Bu yaklaşım sistematik titizlikten yoksundur ve bu da karmaşık muhakeme sorularını yalnızca insan tercihine göre değerlendirmeyi zorlaştırır.”
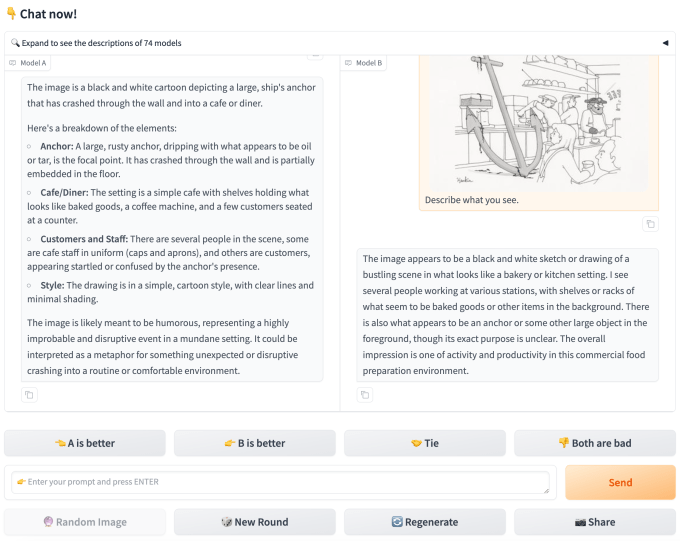
Cook, Chatbot Arena kullanıcılarının kendi kendilerini seçtikleri için (ilk etapta modelleri test etmekle ilgileniyorlar) modelleri zorlamak veya sınırlarını zorlamak konusunda daha az istekli olabileceklerini belirtti.
Cook, “Genel olarak bir çalışma yürütmenin iyi bir yolu değil,” dedi. “Değerlendiriciler bir soru soruyor ve hangi modelin ‘daha iyi’ olduğuna oy veriyorlar – ancak ‘daha iyi’ LMSYS tarafından hiçbir yerde gerçekten tanımlanmıyor. Bu kıyaslamada gerçekten iyi olmak, insanların kazanan bir AI sohbet robotunun daha insancıl, daha doğru, daha güvenli, daha güvenilir vb. olduğunu düşünmesine neden olabilir – ancak bunların hiçbiri gerçekten anlamına gelmiyor.”
LMSYS, diğer modellerden gelen yanıtların kalitesini sıralamak için modeller (OpenAI’nin GPT-4 ve GPT-4 Turbo) kullanan otomatik sistemler (MT-Bench ve Arena-Hard-Auto) kullanarak bu önyargıları dengelemeye çalışıyor. (LMSYS bu sıralamaları oylarla birlikte yayınlıyor). Ancak LMSYS iddia ediyor O modeller “hem kontrollü hem de kitle kaynaklı insan tercihleriyle iyi uyuşuyor” mesele henüz çözülmüş değil.
Ticari bağlar ve veri paylaşımı
Lin, LMSYS’nin artan ticari bağlarının, sıralamalara biraz şüpheyle yaklaşmak için bir diğer neden olduğunu söylüyor.
Modellerini API’ler aracılığıyla sunan OpenAI gibi bazı satıcılar, model kullanım verilerine erişebiliyor ve bu verileri olabilir isterlerse esasen “teste göre öğretmek” için kullanırlar. Bu, LMSYS’nin kendi bulutunda çalışan açık, statik modeller için test sürecini potansiyel olarak adilsiz hale getirir, dedi Lin.
“Şirketler, LMSYS kullanıcı dağılımıyla daha iyi uyum sağlamak için modellerini sürekli olarak optimize edebilir, bu da muhtemelen haksız rekabete ve daha az anlamlı bir değerlendirmeye yol açabilir,” diye ekledi. “API’ler aracılığıyla bağlanan ticari modeller, tüm kullanıcı giriş verilerine erişebilir ve bu da daha fazla trafiğe sahip şirketlere avantaj sağlar.”
Cook, “LMSYS’nin yaptığı şey, yeni yapay zeka araştırmalarını veya buna benzer bir şeyi teşvik etmek yerine, geliştiricileri rekabette ifade avantajı elde etmek için küçük ayrıntıları değiştirmeye teşvik etmek.” diye ekledi.
LMSYS’nin bir kısmı da yapay zeka yarışında atları olan bir VC firması olmak üzere kuruluşlar tarafından destekleniyor.

Google’ın Kaggle veri bilimi platformu LMSYS’ye bağışta bulundu Andreessen Horowitz (yatırımları arasında şunlar yer almaktadır: Mistral) ve Together AI. Google’ın Gemini modelleri Chatbot Arena’da, Mistral’ın ve Together’ın modelleri de yer alıyor.
LMSYS, web sitesinde altyapısını desteklemek için üniversite hibelerine ve bağışlarına da güvendiğini ve donanım ve bulut bilişim kredileri ile nakit şeklinde gelen sponsorluklarının hiçbirinin “bağlı” olmadığını belirtiyor. Ancak ilişkiler, LMSYS’nin tamamen tarafsız olmadığı izlenimini veriyor, özellikle de satıcılar giderek artan bir şekilde Chatbot Arena’yı kullanarak beklenti için onların modeller.
LMSYS, TechCrunch’ın röportaj talebine yanıt vermedi.
Daha iyi bir ölçüt mü?
Lin, kusurlarına rağmen LMSYS ve Chatbot Arena’nın değerli bir hizmet sunduğunu düşünüyor: Farklı modellerin laboratuvar dışında nasıl performans gösterdiğine dair gerçek zamanlı içgörüler sağlamak.
Lin, “Chatbot Arena, genellikle doymuş ve gerçek dünya senaryolarına doğrudan uygulanamayan çoktan seçmeli kıyaslamalar için optimize etme geleneksel yaklaşımını geride bırakıyor,” dedi. “Kıyaslama, gerçek kullanıcıların birden fazla modelle etkileşime girebileceği birleşik bir platform sunarak daha dinamik ve gerçekçi bir değerlendirme sunuyor.”
Ancak LMSYS, Chatbot Arena’ya daha otomatik değerlendirmeler gibi özellikler eklemeye devam ettikçe, Lin kuruluşun testleri iyileştirmek için kolayca üstesinden gelebileceği bazı noktalar olduğunu düşünüyor.
Modellerin güçlü ve zayıf yönlerinin daha “sistematik” bir şekilde anlaşılmasına olanak sağlamak için, LMSYS’nin doğrusal cebir gibi farklı alt başlıklar etrafında, her biri bir dizi alana özgü görev içeren kıyaslamalar tasarlayabileceğini öne sürüyor. Bunun Chatbot Arena sonuçlarına çok daha fazla bilimsel ağırlık kazandıracağını söylüyor.
Lin, “Chatbot Arena, kullanıcı deneyiminin anlık görüntüsünü sunabilse de (küçük ve potansiyel olarak temsili olmayan bir kullanıcı tabanından olsa da) bir modelin zekasını ölçmek için kesin standart olarak kabul edilmemelidir,” dedi. “Bunun yerine, yapay zeka gelişiminin bilimsel ve nesnel bir ölçüsü olmaktan ziyade kullanıcı memnuniyetini ölçmek için bir araç olarak görülmesi daha uygundur.”