
Meta yakın zamanda bir çalışma yayınladı 16.384 Nvidia H100 80GB GPU içeren bir kümede Llama 3 405B model eğitim çalışmasının ayrıntılarını veriyor. Eğitim çalışması 54 gün boyunca gerçekleşti ve küme bu süre zarfında 419 beklenmeyen bileşen arızasıyla karşılaştı, ortalama her üç saatte bir arıza. Arıza vakalarının yarısında, GPU’lar veya yerleşik HBM3 bellekleri suçluydu.
Eski süper bilgisayar atasözünde söylendiği gibi, büyük ölçekli sistemlerdeki tek kesinlik başarısızlıktır. Süper bilgisayarlar, on binlerce işlemci, yüz binlerce başka çip ve yüzlerce kilometre kablo kullanan son derece karmaşık cihazlardır. Karmaşık bir süper bilgisayarda, her birkaç saatte bir bir şeyin bozulması normaldir ve geliştiriciler için asıl numara, bu tür yerel bozulmalara rağmen sistemin çalışır durumda kalmasını sağlamaktır.
16.384 GPU eğitiminin ölçeği ve eşzamanlı yapısı, onu arızalara yatkın hale getirir. Arızalar doğru şekilde azaltılmazsa, tek bir GPU arızası tüm eğitim işini bozabilir ve yeniden başlatmayı gerektirebilir. Ancak, Llama 3 ekibi %90’ın üzerinde etkili bir eğitim süresini korudu.
54 günlük bir ön eğitim anlık görüntüsünde, 47’si planlı ve 419’u beklenmeyen olmak üzere 466 iş kesintisi yaşandı. Planlı kesintiler otomatik bakımdan kaynaklanırken, beklenmeyen kesintiler çoğunlukla donanım sorunlarından kaynaklandı. GPU sorunları en büyük kategoriydi ve beklenmeyen kesintilerin %58,7’sini oluşturuyordu. Sadece üç olay önemli manuel müdahale gerektirdi; geri kalanı otomasyonla yönetildi.
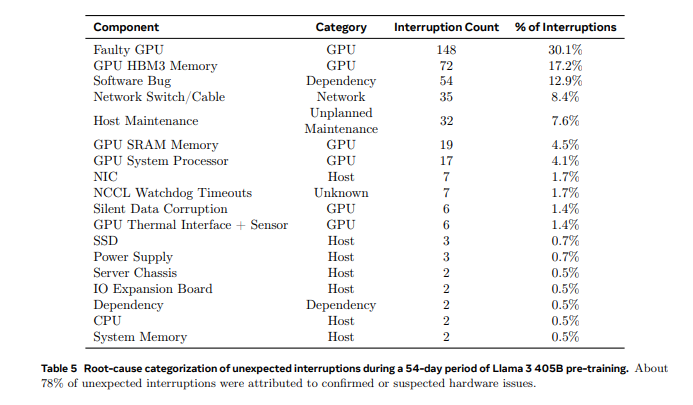
419 beklenmeyen kesintiden 148’i (%30,1) çeşitli GPU arızalarından (NVLink arızaları dahil) kaynaklanırken 72’si (%17,2) HBM3 bellek arızalarından kaynaklandı. Nvidia’nın H100 GPU’larının yaklaşık 700W tükettiği ve çok fazla termal strese maruz kaldığı düşünüldüğünde bu çok da şaşırtıcı değil. İlginçtir ki, 54 günde sadece iki CPU arızalandı.
Ancak GPU’lar kırılgan olan en önemli bileşenler olsa da, beklenmeyen kesintilerin %41,3’ü yazılım hataları, ağ kabloları ve ağ bağdaştırıcıları gibi çok sayıda faktörden kaynaklanıyor.
Verimliliği artırmak için Meta ekibi iş başlatma ve kontrol noktası sürelerini azalttı ve tescilli tanılama araçları geliştirdi. PyTorch’un NCCL uçuş kaydedicisi, özellikle NCCLX ile ilgili olarak donmaları ve performans sorunlarını hızla teşhis etmek ve çözmek için yaygın olarak kullanıldı. Bu araç, toplu meta verileri ve yığın izlerini yakalayarak hızlı sorun çözümüne yardımcı olur.
NCCLX, özellikle NVLink ve RoCE ile ilgili sorunlar için arıza tespiti ve yerelleştirmede önemli bir rol oynadı. PyTorch ile entegrasyon, NVLink arızalarından kaynaklanan iletişim duraklamalarının izlenmesine ve otomatik zaman aşımına uğramasına olanak sağladı.
Binlerce diğer GPU’yu yavaşlatabilen başıboş GPU’lar, özel araçlar kullanılarak belirlendi. Bu araçlar sorunlu iletişimlere öncelik vererek başıboşların etkili bir şekilde tespit edilmesini ve zamanında çözülmesini sağladı, bu da yavaşlamaların en aza indirilmesini ve genel eğitim verimliliğinin korunmasını sağladı.
Öğle vakti sıcaklık dalgalanmaları gibi çevresel faktörler, verimde %1-2’lik bir değişime neden olarak eğitim performansını etkiledi. GPU’ların dinamik voltaj ve frekans ölçeklemesi bu sıcaklık değişimlerinden etkilendi, ancak büyük bir sorun değildi.
Llama 3 405B LLM eğitim ekibinin yaşadığı bir diğer zorluk da on binlerce GPU’nun eş zamanlı güç tüketimi değişiklikleridir ve bu da veri merkezlerinin güç şebekesini zorlar. Bazen onlarca megawatt’a varan bu dalgalanmalar şebekenin sınırlarını zorladı ve bu da Meta’nın veri merkezlerinin yeterli güce sahip olduğundan emin olması gerektiği anlamına geliyor.
16.384 GPU’luk bir kümenin 54 günde 419 arıza yaşadığını (24 saatte 7,76 kez veya üç saatte bir arıza) göz önünde bulundurduğumuzda, arızalanabilecek bileşen sayısında altı kat artış anlamına gelen 100.000 adet H100 GPU içeren xAI kümesinin ne sıklıkla arıza yaşayacağını merak edebiliriz.