
Yandex bilim adamları, büyük dil modellerini sıkıştırmak için yeni yöntemler geliştirdi ve kamuya açıkladı. Yandex Araştırma uzmanlarına göre bu değişiklikler, işletmelerin bilgi işlem kaynaklarının maliyetini sekiz kata kadar azaltmasına olanak tanıyacak. Bu gelişme, ekipmanlarında sinir ağları çalıştıran şirketler, yeni kurulan şirketler ve araştırmacılar için faydalı olacak.
Büyük bir dil modelinin verimli ve hızlı bir şekilde yanıt verebilmesi için birçok pahalı, güçlü GPU’ya ihtiyaç vardır. Yandex’in çözümü, modeli birkaç kez küçültmeyi, gerekli işlemci sayısını azaltmayı ve daha az bilgi işlem gücüne sahip cihazlarda çalıştırmayı mümkün kılıyor. Bu, sinir ağlarının uygulanmasının ve ekipman bakımının işletmeler için daha ucuz hale geleceği anlamına geliyor.
Yandex çözümü iki araç içerir. Birincisi, daha hızlı çalışan ve örneğin dört yerine bir grafik işlemcide çalıştırılabilen, sekiz kata indirilmiş bir sinir ağı elde etmenize olanak tanır. İkinci araç, büyük bir dil modelinin sıkıştırma işlemi sırasında oluşan hataları düzeltir.
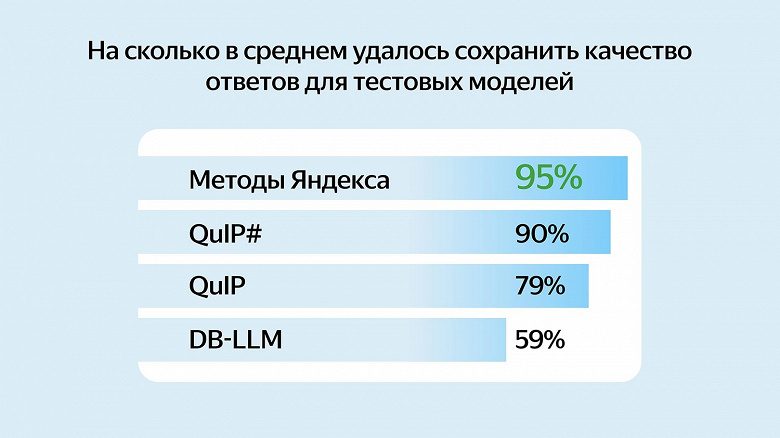
Sinir ağının orijinal ve sıkıştırılmış versiyonlarından gelen yanıtların kalitesi, İngilizce karşılaştırmalı değerlendirmeler kullanılarak karşılaştırıldı. Yandex, yeni yaklaşımın mevcut tüm sıkıştırma yöntemleri arasında en iyi sonucu gösterdiğini belirtiyor. Yandex Research tarafından oluşturulan yöntem, sinir ağı yanıtlarının kalitesinin ortalama %95’ini korurken, diğer popüler araçlar aynı modeller için kalitenin yalnızca %59 ila %90’ını korur. Yeni yöntemin kodu GitHub’da yayınlandı ve ayrıca onu kullanarak zaten sıkıştırılmış popüler açık kaynaklı modelleri ve eğitim materyallerini de indirebilirsiniz.