
Yapay zeka modelleri, performans gösterebilmek için mümkün olduğunca çok sayıda yararlı veriye ihtiyaç duyar; ancak en büyük yapay zeka geliştiricilerinden bazıları, YouTube’un kendi kurallarını ihlal ederek, içerik oluşturucularından izin alınmadan kısmen transkripsiyonlu YouTube videolarına güveniyor. soruşturma ile Kanıt Haberleri Ve Kablolu.
İki kuruluş, Apple, Nvidia, Anthropic ve diğer büyük yapay zeka şirketlerinin, video yaratıcılarının haberi olmadan, 48.000 kanala ait yaklaşık 175.000 videonun transkriptlerini içeren YouTube Altyazıları adlı bir veri kümesiyle modellerini eğittiğini ortaya koydu.
YouTube Altyazıları veri kümesi, genellikle birden fazla dile çevirileriyle birlikte video altyazılarının metnini içerir. Veri kümesi, veri kümesinin amacını büyük teknoloji şirketlerinin dışındakiler için AI geliştirmenin önündeki engelleri azaltmak olarak tanımlayan EleutherAI tarafından oluşturulmuştur. Bu, Pile adı verilen çok daha büyük EleutherAI veri kümesinin yalnızca bir bileşenidir. YouTube transkriptlerinin yanı sıra Pile’da Wikipedia makaleleri, Avrupa Parlamentosu’ndan konuşmalar ve rapora göre Enron’dan gelen e-postalar bile bulunmaktadır.
Ancak, Pile’ın büyük teknoloji şirketleri arasında çok sayıda hayranı var. Örneğin, Apple, Pile’ı OpenELM AI modelini eğitmek için kullandı, Salesforce AI modeli ise iki yıl önce Pile ile eğitildi ve o zamandan beri 86.000’den fazla kez indirildi.
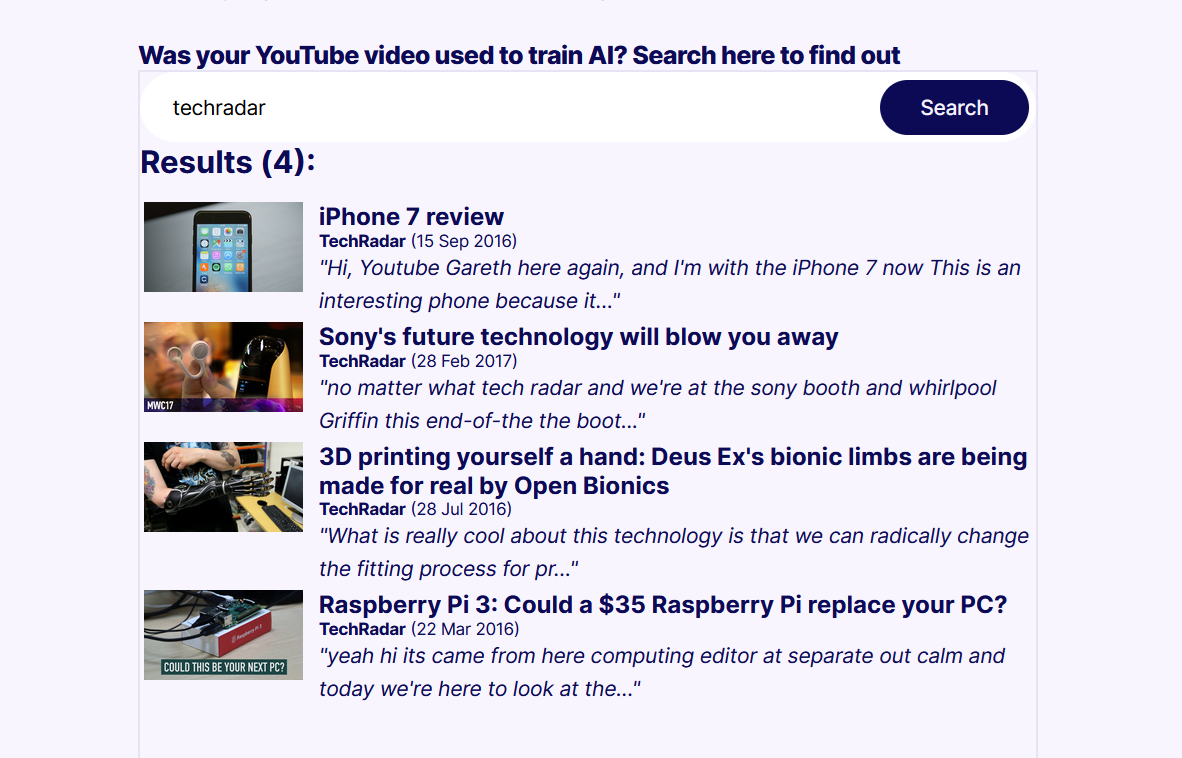
YouTube Altyazıları veri kümesi, haber, eğitim ve eğlence alanlarındaki popüler kanalların bir yelpazesini kapsar. Bunlara MrBeast ve Marques Brownlee gibi önemli YouTube yıldızlarının içerikleri de dahildir. Hepsinin videoları AI modellerini eğitmek için kullanılmıştır. Proof News bir arama aracı koleksiyonda belirli bir video veya kanalın olup olmadığını görmek için arama yapacak. Aşağıda görüldüğü gibi koleksiyonda birkaç TechRadar videosu bile var.
Gizli Paylaşım
YouTube Altyazıları veri kümesi, videolarının ve ilişkili verilerinin otomatik olarak taranmasını açıkça yasaklayan YouTube’un hizmet şartlarıyla çelişiyor gibi görünüyor. Ancak veri kümesi tam olarak buna dayanıyordu, YouTube’un API’si aracılığıyla altyazıları indiren bir betik. Soruşturma, otomatik indirmenin yaklaşık 500 arama terimi içeren videoları ayıkladığını bildirdi.
Keşif, Proof ve Wired’ın röportaj yaptığı YouTube içerik oluşturucularında büyük bir şaşkınlık ve öfkeye yol açtı. İçeriğin izinsiz kullanımıyla ilgili endişeler geçerli ve içerik oluşturucuların bazıları, çalışmalarının AI modellerinde ödeme veya izin olmadan kullanılması fikrinden rahatsız oldu. Bu, özellikle veri setinin silinmiş videoların transkriptlerini içerdiğini ve bir durumda verilerin, o zamandan beri tüm çevrimiçi varlığını kaldıran bir içerik oluşturucudan geldiğini öğrenenler için geçerlidir.
Raporda EleutherAI’dan herhangi bir yorum yapılmadı. Kuruluşun misyonunu eğitilmiş modeller yayınlayarak AI teknolojilerine erişimi demokratikleştirmek olarak tanımladığı belirtildi. Bu, eğer bu veri kümesi bir ölçütse, içerik oluşturucularının ve platformların çıkarlarıyla çelişebilir. AI üzerindeki yasal ve düzenleyici savaşlar zaten karmaşıktı. Bu tür bir ifşa, AI gelişiminin etik ve yasal manzarasını muhtemelen daha tehlikeli hale getirecektir. AI için yenilik ve etik sorumluluk arasında bir denge önermek kolaydır, ancak bunu üretmek çok daha zor olacaktır.