
GPT-4o ve Gemini 1.5 Pro gibi son dil modelleri, metin kadar görselleri ve sesleri de anlayabilen “çok modlu” olarak tanıtılıyor; ancak yeni bir çalışma, bunların aslında çok da iyi olmadığını açıkça ortaya koyuyor. Görmek beklediğiniz gibi. Aslında, hiç göremeyebilirler.
Baştan açık olmak gerekirse, hiç kimse “Bu AI insanlar gibi görebiliyor!” gibi iddialarda bulunmadı. (Yani… belki bazıları görmüştür.) Ancak bu modelleri tanıtmak için kullanılan pazarlama ve kıyaslama ölçütleri “görme yetenekleri”, “görsel anlayış” vb. ifadeler kullanır. Modelin görüntüleri ve videoları nasıl gördüğünden ve analiz ettiğinden bahsederler, bu nedenle ödev problemlerinden sizin için maçı izlemeye kadar her şeyi yapabilir.
Bu şirketlerin iddiaları ustaca dile getirilmiş olsa da, modelin bir anlamda gördüğünü ifade etmek istedikleri açıktır. Ve görüyor da — ama tıpkı matematik yaptığı veya hikaye yazdığı gibi: giriş verilerindeki kalıpları eğitim verilerindeki kalıplarla eşleştiriyor. Bu, modellerin rastgele bir sayı seçmek gibi önemsiz görünen diğer bazı görevlerde olduğu gibi başarısız olmasına yol açıyor.
Bazı açılardan gayriresmî ama sistematik bir çalışma Mevcut AI modellerinin görsel anlayışı Auburn Üniversitesi ve Alberta Üniversitesi’ndeki araştırmacılar tarafından üstlenildi. En büyük çok modlu modelleri, iki şeklin örtüşüp örtüşmediğini veya bir resimde kaç tane beşgen olduğunu veya bir kelimedeki hangi harfin daire içine alındığını sormak gibi çok basit görsel görevler dizisine yerleştirdiler. (Özet bir mikrosayfa burada incelenebilir.)
Bunlar birinci sınıf öğrencisinin bile doğru yapabileceği şeylerdi, ancak bu durum yapay zeka modellerinin çok zorlanmasına neden oldu.
“7 görevimiz, insanların %100 doğrulukla performans göstereceği son derece basit görevlerdir. Yapay zekaların da aynısını yapmasını bekliyoruz, ancak şu anda yapmıyorlar” diye yazdı ortak yazar Anh Nguyen TechCrunch’a gönderdiğimiz bir e-postada. “Mesajımız ‘bakın, bu en iyi modeller HÂLÂ başarısız oluyor.'”

Çakışan şekiller testini yapın: düşünülebilecek en basit görsel akıl yürütme görevlerinden biri. Hafifçe çakışan, birbirine değen veya aralarında biraz mesafe olan iki daire sunulduğunda, modeller tutarlı bir şekilde doğru yapamadı. Elbette, GPT-4o birbirlerinden uzaktayken %95’ten fazla doğru yaptı, ancak sıfır veya küçük mesafelerde yalnızca %18 doğru yaptı! Gemini Pro 1.5 en iyisini yapıyor, ancak yine de yakın mesafelerde yalnızca 7/10 alıyor.
(Resimler modellerin tam performansını göstermez, ancak modellerin koşullara göre tutarsızlığını göstermeyi amaçlamaktadır. Her modelin istatistikleri makalede yer almaktadır.)
Ya da bir görüntüdeki iç içe geçmiş dairelerin sayısını saymaya ne dersiniz? Ortalamanın üzerinde bir atın bunu yapabileceğine bahse girerim.
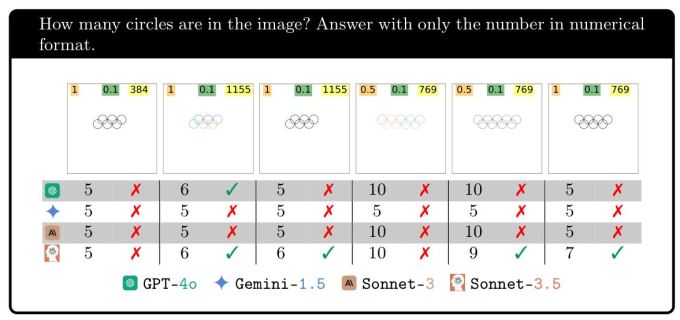
Hepsi 5 halka olduğunda %100 doğru yapıyor — harika iş görsel yapay zeka! Ancak daha sonra bir halka eklemek sonuçları tamamen mahvediyor. Gemini kaybolmuş durumda, tek bir seferde bile doğru yapamıyor. Sonnet-3.5 6… üçte bir oranında ve GPT-4o ise yarıdan biraz daha az bir oranda doğru cevap veriyor. Başka bir halka eklemek bunu daha da zorlaştırıyor, ancak bazıları için başka bir halka eklemek işi kolaylaştırıyor.
Bu deneyin amacı basitçe, bu modeller ne yapıyorsa yapsın, aslında bizim gördüğümüzü düşündüğümüz şeye gerçekten uymadığını göstermektir. Sonuçta, kötü görseler bile, 6, 7, 8 ve 9 halkalı görüntülerin başarıda bu kadar büyük farklılıklar göstermesini beklemezdik.
Test edilen diğer görevlerde de benzer örüntüler görüldü: Görme veya muhakeme yetenekleri iyi ya da kötü değildi, ancak bir durumda sayabilmelerinin ancak bir diğerinde sayamamalarının başka bir nedeni vardı.
Elbette olası bir cevap yüzümüze bakıyor: Neden 5 daireli bir görüntüyü doğru şekilde elde etmekte bu kadar iyiler ama geri kalanında veya 5 beşgen söz konusu olduğunda bu kadar başarısız oluyorlar? (Adil olmak gerekirse, Sonnet-3.5 bu konuda oldukça başarılıydı.) Çünkü hepsinin eğitim verilerinde öne çıkan bir 5 daireli görüntü var: Olimpiyat Halkaları.

Bu logo yalnızca eğitim verilerinde tekrar tekrar tekrarlanmakla kalmıyor, aynı zamanda alt metinde, kullanım kılavuzlarında ve bununla ilgili makalelerde ayrıntılı olarak açıklanıyor. Peki eğitim verilerinde 6 veya 7 iç içe geçmiş halkayı nerede bulacaksınız? Cevapları bir gösterge ise… hiçbir yerde! Ne “baktıkları” hakkında hiçbir fikirleri yok ve halkaların, örtüşmelerin veya bu kavramlardan herhangi birinin ne olduğuna dair gerçek bir görsel anlayışları yok.
Araştırmacılara, modellerin sahip olduğu bu “körlük” hakkında ne düşündüklerini sordum. Kullandığımız diğer terimler gibi, tam olarak doğru olmayan ancak onsuz yapmanın zor olduğu antropomorfik bir niteliğe sahip.
“Katılıyorum, ‘kör’ kelimesinin insanlar için bile birçok tanımı var ve AI’ların gösterdiğimiz görüntülere karşı bu tür körlüğü/duyarsızlığı için henüz bir kelime yok,” diye yazdı Nguyen. “Şu anda, bir modelin tam olarak ne gördüğünü görselleştirecek bir teknoloji yok. Ve davranışları, girdi metni isteminin, girdi resminin ve milyarlarca ağırlığın karmaşık bir işlevidir.”
Modellerin tam olarak kör olmadığını, ancak bir görüntüden çıkardıkları görsel bilginin yaklaşık ve soyut olduğunu, “sol tarafta bir daire var” gibi bir şey olduğunu ileri sürdü. Ancak modellerin görsel yargılarda bulunma araçları olmadığından, tepkileri bir görüntü hakkında bilgilendirilmiş ancak onu gerçekten göremeyen birinin tepkileri gibi oluyor.
Son bir örnek olarak Nguyen, yukarıdaki hipotezi destekleyen şu mesajı gönderdi:

Mavi daire ve yeşil daire üst üste geldiğinde (soru modelin gerçek olarak kabul etmesini sağladığında), genellikle Venn diyagramında olduğu gibi, camgöbeği gölgeli bir alan ortaya çıkar. Birisi size bu soruyu sorsaydı, siz veya herhangi bir akıllı kişi aynı cevabı verebilirdi, çünkü bu tamamen olasıdır… gözleriniz kapalıysa! Ama gözleri olan hiç kimse açık bu şekilde cevap verirdi.
Tüm bunlar bu “görsel” AI modellerinin işe yaramaz olduğu anlamına mı geliyor? Kesinlikle hayır. Belirli görüntüler hakkında temel akıl yürütme yapamamak, temel yeteneklerine işaret ediyor, ancak belirli yeteneklerine değil. Bu modellerin her biri, insan eylemleri ve ifadeleri, günlük nesnelerin ve durumların fotoğrafları ve benzeri şeyler konusunda büyük olasılıkla oldukça doğru olacaktır. Ve aslında yorumlamaları gereken şey budur.
Bu modellerin yapabileceği her şeyi bize söylemesi için AI şirketlerinin pazarlamasına güvenseydik, 20/20 görüşe sahip olduklarını düşünürdük. Bu tür araştırmalar, modelin bir kişinin oturup oturmadığını, yürüyüp yürümediğini veya koşup koşmadığını söylemede ne kadar doğru olursa olsun, bunu bizim kastettiğimiz anlamda (eğer isterseniz) “görmeden” yaptığını göstermek için gereklidir.