

Nölçek AMD’nin amiral gemisi Instinct MI300X AI hızlandırıcısını GEMM ayarlama çerçevesini kullanarak test ederek 7 kat daha hızlı performans elde etti.
Nscale’nin En Yeni AMD MI300X Karşılaştırması, GEMM Ayarlamanın Önemli Performans Artışlarına Yol Açtığını Ortaya Çıkarıyor
[Press Release]: Nscale’nin en son teknik derinlemesine incelemesinde yapay zeka modeli optimizasyonunun kritik bir yönünü keşfediyoruz: GEMM (Genel Matris Çarpma) ayarlamasını kullanarak verim kıyaslaması, performans ayarlaması ve gecikmeyi azaltma.
GPU ile hızlandırılmış görevlerin performansını en üst düzeye çıkarmak, saf hızdan daha fazlasını gerektirir. GEMM’nin optimize edilmesi, verimli işleme, daha yüksek verim ve karmaşık modelleri ve veri kümelerini etkili bir şekilde yönetme becerisini sağlar.
Bu blogda, birden fazla modelde vLLM veriminin kıyaslamasını inceleyeceğiz ve GEMM ayarının önemli etkisini derinlemesine inceleyeceğiz. gibi güçlü kütüphaneler rocBLAS (ROCm Temel Doğrusal Cebir Alt Programları) ve kalçaBLASlt (Taşınabilirlik için Heterojen Hesaplama Arayüzü, Temel Doğrusal Cebir Alt Programları) bu süreçte etkilidir.
Bu kitaplıklar, bir dizi ayarlama parametresinin yanı sıra GEMM işlemlerinin optimize edilmiş uygulamalarını sağlayarak geliştiricilerin uygulamalarına ince ayar yapmalarına ve temel donanımlarının tüm potansiyelini ortaya çıkarmalarına olanak tanıyarak vLLM performansını en üst düzeye çıkarmalarını sağlar.
GEMM Ayarlama nedir?
GEMM ayarlama, matris çarpım işlemlerinin performansını artırmak için güçlü bir tekniktir. Bu süreç, bellek, önbellek ve bilgi işlem yetenekleri gibi faktörlere dayalı olarak en uygun algoritmanın seçilmesini içerir.”
Parametrelere ince ayar yaparak ve en uygun algoritmaları seçerek, GEMM işleminin mevcut bilgi işlem kaynaklarının kullanımında verimliliği en üst düzeye çıkarmasını sağlıyoruz. Bu, yapay zeka ve makine öğrenimi modellerinde önemli hız iyileştirmeleri anlamına gelir.
Karşılaştırılan Metrikler
Analizimiz, iki kıyaslama çalışması arasındaki çeşitli temel performans ölçümlerini karşılaştırdı.
- Üretim Hızı (saniye başına token): Hem girdi hem de çıktı süreçleri için token oluşturma verimliliğini ölçmemize olanak sağladı.
- Saniye Başına İstekler: Sistemin birden fazla eşzamanlı isteği etkili bir şekilde yönetme becerisinin açık bir göstergesini sağlamak.
- Genel Verim (saniye başına işlenen jeton sayısı): Farklı konfigürasyonlar altında sistem performansının kapsamlı bir görünümünü sunarak üretim hızı ve talep yönetiminin birleşik verimliliğini kapsar.–
- Ortalama Gecikme (saniye): Bir yanıt oluşturmak için geçen sürenin ölçülmesi.
Karşılaştırma Çalıştırmaları Ayarları
Her kıyaslama çalışmasını aşağıdaki ayarlarla yapılandırdık:
- Her İstek için İstem Uzunluğunu Girin: 256 jeton
- Her İstek İçin Çıkış Uzunluğu: 256 jeton
- Tensör Paralel Boyutu: 1 (tek bir GPU kullanarak, özellikle MI300X)–
- Parti Boyutları: 1, 2 ve 4
Temel Gözlemler:
Llama, Mistral, Mistral ve Falcon gibi LLM’lerin GEMM ayarlaması yoluyla elde edilen dikkate değer ilerlemeleri inceleyelim. Ayarlanmış GEMM’in bu modellerin performansı ve verimliliği üzerindeki etkisini aydınlatan bir dizi grafiği ve veri görselleştirmesini analiz edeceğiz.
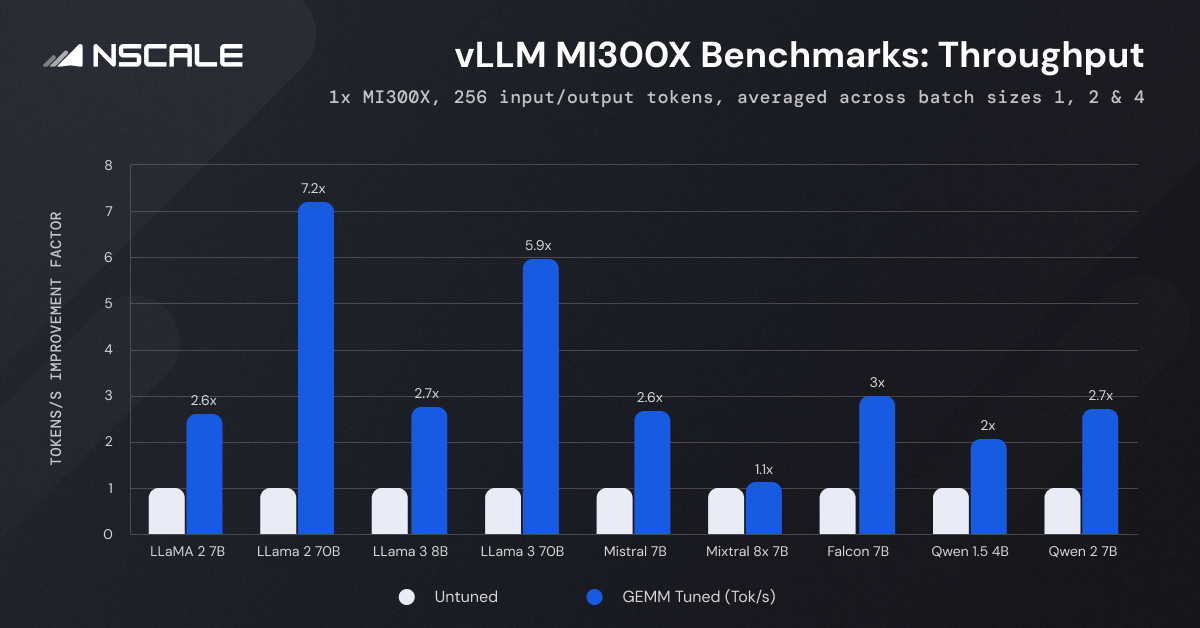
Grafik, AMD Instinct MI300X AI hızlandırıcıda GeMM ayarı etkinleştirildiğinde üretim hızında önemli bir artış olduğunu gösteriyor.
GEMM Ayarlama Etkisi: GEMM ayarlamanın etkinleştirilmesi, LLaMA-2-70B modelinde görüldüğü gibi verimi 7,2 kata kadar artırır.
Model Boyutu: LLaMA-2-70B ve LLaMA-3-70B gibi daha büyük modeller, sırasıyla 7,2 kat ve 5,9 kat artışla üretimde en önemli gelişmeleri gösteriyor.
Parti boyutu: Daha yüksek parti boyutları genellikle GEMM ayarlamasıyla güçlendirilen daha yüksek verim sağlar. Örneğin, Falcon 7B modelinin verimi, GEMM ayarlaması olmadan parti boyutu 1’de 244,74 token/saniyeden, parti boyutu 4’te 952,38 token/saniyeye yükselir. Ayarlamayla birlikte 2736,58 token/saniyeye daha da tırmanıyor.
Modeller Arası Karşılaştırma: Test edilen modeller arasında LLaMA-2-70B ve LLaMA-3-70B, karmaşıklıkları ve boyutları nedeniyle en yüksek verimi sergiliyor. Tersine, Qwen 1.5 4B ve Falcon 7B gibi daha küçük modeller nispeten daha yüksek verim gösteriyor, bu da daha az karmaşık modeller için daha verimli işleme anlamına geliyor.
Gecikme:
Grafik, GEMM ayarlaması yoluyla elde edilen gecikme süresindeki tutarlı azalmayı göstermektedir.
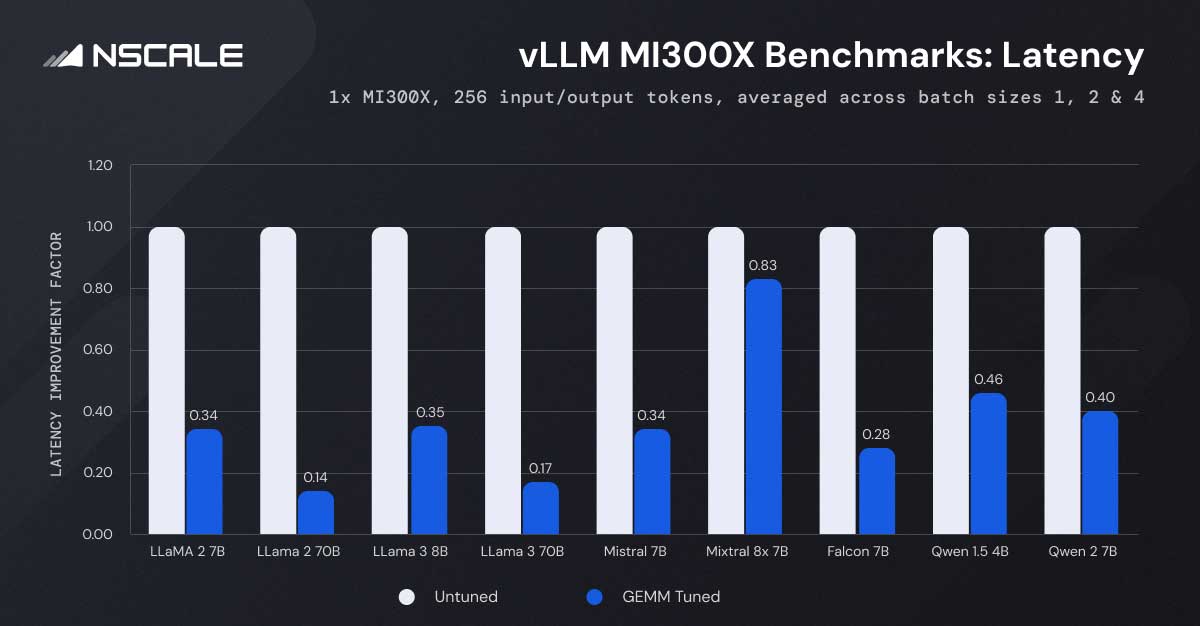
GEMM Ayarlama Etkisi: Gecikme tüm modellerde önemli ölçüde azalır. Örneğin LLaMA-2-7B modelinin gecikmesi 1,00 saniyeden 0,35 saniyeye düşüyor. Test sırasında, GEMM ayarı etkinleştirildiğinde, toplu iş boyutu 1 olan LLaMA-2-7B modelinin gecikmesinin %66,5 düşüşle 1,97 saniyeden 0,66 saniyeye düştüğünü gözlemledik. Bu model, parti boyutu 4’e kadar geçerli olup, GEMM ayarlamanın sunduğu önemli performans iyileştirmesini vurgulamaktadır.
Model Boyutu: Daha büyük modeller doğası gereği daha yüksek gecikme süresi gösterir. Örneğin LLaMA-2-70B modeli, GEMM ayarlaması olmadan 1,00 saniyelik ve ayarlama etkinken 0,14 saniyelik bir gecikme gösterir. Karşılaştırıldığında, LLaMA-2-7B gibi daha küçük modeller benzer koşullar altında çok daha düşük gecikme süresi gösteriyor. Bu eğilim, parti boyutları arasında tutarlı olup, model boyutunun işlem süresini doğrudan etkilediğini vurgulamaktadır.
Parti boyutu: Daha büyük toplu iş boyutları genellikle gecikmeyi artırırken, GEMM ayarlaması bunu hafifleterek gecikmeyi azaltır. GEMM ayarı olmadan LLaMA-2-7B modelini test ettiğimizde gecikme, toplu iş boyutu 1’de 1,97 saniyeden toplu iş boyutu 4’te 2,11 saniyeye yükselir. GEMM ayarı etkinleştirildiğinde, artış 0,66 saniyeden 0,77 saniyeye çıkar. Bu, GEMM ayarının gecikme artışını bir dereceye kadar azaltırken, daha büyük partilerin işlenmesinin doğal olarak daha fazla hesaplama çabası ve zaman gerektirdiğini gösteriyor.
Modeller Arası Karşılaştırma: Qwen 1.5 4B ve Falcon 7B gibi modeller de daha düşük gecikme süresi gösteriyor ve bu da farklı karmaşıklıklarda GEMM ayarının etkinliğini vurguluyor.
Çözüm:
GEMM ayarlamalı AMD MI300X GPU’lar üzerinde yaptığımız kapsamlı kıyaslama çalışmamız, belirli modellerde 7,2 kata kadar kazançla hem verim hem de gecikmede iyileşmeler ortaya koyuyor. rocBLAS ve hipBLASlt kitaplıklarını kullanarak GEMM operasyonlarını optimize ederek, LLaMA, Mistral, Mixtral ve Falcon dahil olmak üzere çeşitli büyük dil modellerinin performansını ve verimliliğini önemli ölçüde artırdık.
Haber kaynağı: Nölçek