
Neden Önemlidir: Yapay zekayı her yere getirme misyonunun bir parçası olarak Intel, ürünlerinin dinamik yapay zeka alanındaki en son yeniliklere hazır olmasını sağlamak için yazılıma ve yapay zeka ekosistemine yatırım yapıyor. Veri merkezinde, Gelişmiş Matris Genişletme (AMX) hızlandırmalı Gaudi ve Xeon işlemciler, müşterilere dinamik ve geniş kapsamlı gereksinimleri karşılama seçenekleri sunar.
Intel Core Ultra işlemciler ve Arc grafik ürünleri, hem yerel bir geliştirme aracı hem de yerel araştırma ve geliştirme için kullanılan PyTorch ve PyTorch için Intel Extension ile model geliştirme ve çıkarım için OpenVINO araç seti dahil olmak üzere kapsamlı yazılım çerçeveleri ve araçları desteğiyle milyonlarca cihaza dağıtım sağlar. .
Intel’de Çalışan Llama 3 Hakkında: Intel’in Llama 3 8B ve 70B modelleri için ilk test ve performans sonuçlarında, en yeni yazılım optimizasyonlarını sağlamak üzere PyTorch, DeepSpeed, Optimum Habana kitaplığı ve PyTorch için Intel Extension dahil olmak üzere açık kaynaklı yazılımlar kullanılır.
- Intel Gaudi 2 hızlandırıcıları, Llama 2 modellerinde (7B, 13B ve 70B parametreleri) optimize edilmiş performansa sahiptir ve artık yeni Llama 3 modeli için başlangıç performans ölçümlerine sahiptir. Gaudi yazılımının olgunlaşmasıyla Intel, yeni Llama 3 modelini kolayca çalıştırdı ve çıkarım ve ince ayar için sonuçlar üretti. Llama 3, yakın zamanda duyurulan Gaudi 3 hızlandırıcı tarafından da destekleniyor.
- Intel Xeon işlemciler, zorlu uçtan uca yapay zeka iş yüklerini ele alıyor ve Intel, gecikmeyi azaltmak için LLM sonuçlarını optimize etmeye yatırım yapıyor. Performans çekirdekli Xeon 6 işlemciler (kod adı Granite Rapids), 4. Nesil ile karşılaştırıldığında Llama 3 8B çıkarım gecikmesinde 2 kat iyileşme gösteriyor
- Intel Core Ultra ve Arc Graphics, Llama 3 için etkileyici bir performans sunuyor. İlk test turunda, Core Ultra işlemciler zaten tipik insan okuma hızlarından daha yüksek hızlar üretiyor. Ayrıca Arc A770 GPU’nune Matrix eXtensions (XMX) AI hızlandırma ve 16 GB ayrılmış bellek, LLM iş yükleri için olağanüstü performans sağlar.
Xeon Ölçeklenebilir İşlemciler
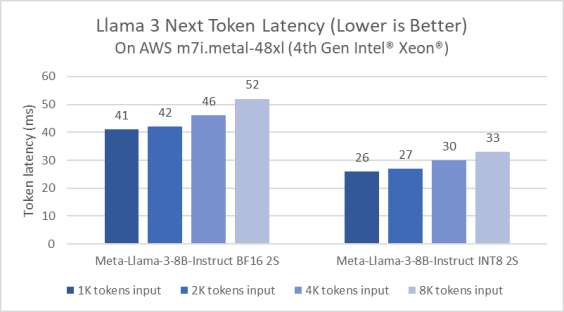
Intel, Xeon platformları için LLM çıkarımını sürekli olarak optimize ediyor. Örnek olarak, PyTorch ve PyTorch için Intel Extension’daki Llama 2 başlatma yazılımı iyileştirmeleriyle karşılaştırıldığında, gecikme süresinde 5 kat azalma sağlayacak şekilde geliştirildi. Optimizasyon, mevcut bilgi işlem kullanımını ve bellek bant genişliğini en üst düzeye çıkarmak için sayfalanmış dikkat ve tensör paralelinden yararlanır. Şekil 1, 4. Nesil Xeon Ölçeklenebilir işlemciyi temel alan AWS m7i.metal-48x örneğinde Meta Llama 3 8B çıkarımının performansını göstermektedir.
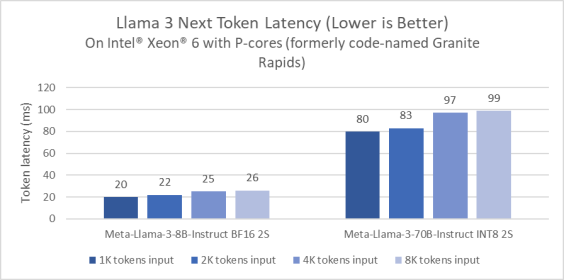
Performansın bir önizlemesini paylaşmak için Meta Llama 3’ü Performans çekirdeklerine (eski adıyla Granite Rapids) sahip bir Xeon 6 işlemci üzerinde karşılaştırdık. Bu önizleme numaraları, Xeon 6’nın, yaygın olarak bulunan 4. Nesil soket sunucusuyla karşılaştırıldığında Llama 3 8B çıkarım gecikmesinde 2 kat iyileştirme sunduğunu gösteriyor.
| Modeli | TP | Kesinlik | Giriş uzunluğu | Çıkış Uzunluğu | Verim | Gecikme* | Grup |
| Meta-Llama-3-8B-Talimat | 1 | FP8 | 2 bin | 4k | 1549,27
belirteç/sn |
7.747
Hanım |
12 |
| Meta-Llama-3-8B-Talimat | 1 | bf16 | 1 bin | 3 bin | 469.11
belirteç/sn |
8.527
Hanım |
4 |
| Meta-Llama-3-70B-Talimat | 8 | FP8 | 2 bin | 4k | 4927.31
belirteç/sn |
56.23
Hanım |
277 |
| Meta-Llama-3-70B-Talimat | 8 | bf16 | 2 bin | 2 bin | 3574.81
belirteç/sn |
60.425
Hanım |
216 |
Müşteri Platformları
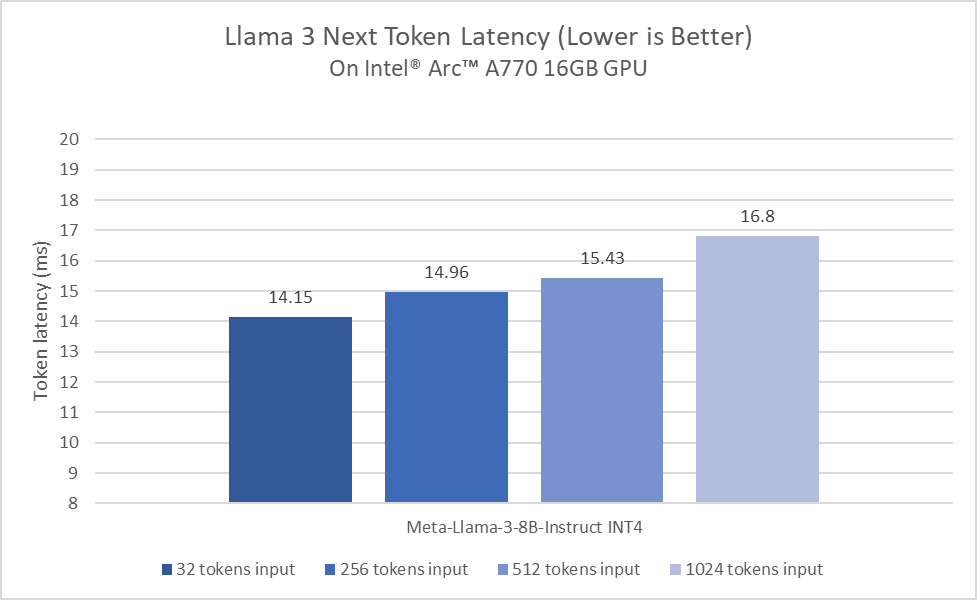
İlk değerlendirme turunda, Intel Core Ultra işlemci zaten tipik insan okuma hızlarından daha hızlı üretiyor. Bu sonuçlar, DP4a AI hızlandırma dahil 8 Xe çekirdekli yerleşik Arc GPU ve 120 GB/s’ye kadar sistem belleği bant genişliği ile elde ediliyor. Özellikle yeni nesil işlemcilerimize geçerken, Llama 3’te sürekli performans ve güç verimliliği optimizasyonlarına yatırım yapmaktan heyecan duyuyoruz.
Core Ultra işlemciler ve Arc grafik ürünlerine yönelik lansman günü desteğiyle Intel ve Meta arasındaki işbirliği, hem yerel bir geliştirme aracı hem de milyonlarca cihaza dağıtım sağlıyor. Intel istemci donanımı, yerel araştırma ve geliştirme için kullanılan PyTorch ve Intel Extension for PyTorch ile model dağıtımı ve çıkarımı için OpenVINO Araç Takımı da dahil olmak üzere kapsamlı yazılım çerçeveleri ve araçlarıyla hızlandırılır.
Sıradaki ne: Önümüzdeki aylarda Meta, yeni özellikler, ek model boyutları ve gelişmiş performans sunmayı planlıyor. Intel, bu yeni LLM’yi desteklemek için AI ürünlerinin performansını optimize etmeye devam edecek.