
Yapay zeka kadar hızlı hareket eden bir sektöre ayak uydurmak zorlu bir iştir. Yani bir yapay zeka bunu sizin için yapana kadar, kendi başımıza ele almadığımız dikkate değer araştırma ve deneylerin yanı sıra, makine öğrenimi dünyasındaki son hikayelerin kullanışlı bir özetini burada bulabilirsiniz.
Bu hafta AI’da, dikkatleri etiketleme ve açıklama ekleme girişimlerine çevirmek istiyorum – Scale AI gibi girişimler. bildirildiğine göre 13 milyar dolarlık değerlemeyle yeni fon toplamak için görüşmelerde bulunuyor. Etiketleme ve açıklama platformları, OpenAI’nin Sora’sı gibi gösterişli yeni üretken yapay zeka modellerinin dikkatini çekmeyebilir. Ama bunlar çok önemli. Onlar olmasaydı modern yapay zeka modelleri tartışmasız var olamazdı.
Birçok modelin eğitildiği verilerin etiketlenmesi gerekir. Neden? Etiketler veya etiketler, eğitim süreci sırasında modellerin verileri anlamasına ve yorumlamasına yardımcı olur. Örneğin, bir görüntü tanıma modelini eğitmek için kullanılan etiketler nesnelerin etrafındaki işaretlemeler şeklini alabilir, “sınırlayıcı kutular” veya bir görselde tasvir edilen her bir kişiye, yere veya nesneye atıfta bulunan başlıklar.
Etiketlerin doğruluğu ve kalitesi, eğitilen modellerin performansını ve güvenilirliğini önemli ölçüde etkiler. Ve ek açıklama, kullanımda olan daha büyük ve daha karmaşık veri kümeleri için binlerce ila milyonlarca etiket gerektiren çok büyük bir girişimdir.
Yani veri açıklayıcılarına iyi davranılacağını, geçimlik ücretler ödeneceğini ve modelleri oluşturan mühendislerin yararlandığı avantajların aynılarının sağlanacağını düşünürsünüz. Ancak çoğu zaman tam tersi doğrudur; birçok ek açıklama ve etiketleme girişiminin teşvik ettiği acımasız çalışma koşullarının bir ürünüdür.
OpenAI gibi bankada milyarlarca doları olan şirketler, Üçüncü dünya ülkelerindeki yorumcular saat başına yalnızca birkaç dolar ödüyordu. Bu yorumculardan bazıları, sansürlenmemiş görüntüler gibi son derece rahatsız edici içeriğe maruz kalıyor, ancak kendilerine izin verilmiyor (genellikle yüklenici oldukları için) veya zihinsel sağlık kaynaklarına erişimleri yok.
Mükemmel parça NY Mag, özellikle Nairobi ve Kenya gibi uzak ülkelerden yorumcuları işe alan Scale AI’nın perdelerini aralıyor. Scale AI’daki görevlerden bazıları, etiketleyicilerin sekiz saatlik iş günü sürmesini (ara vermeden) ve 10 ABD doları kadar düşük bir ücret ödemesini gerektiriyor. Ve bu işçiler platformun kaprislerine bağlılar. Açıklamacılar bazen uzun süre iş alamadan giderler veya Tayland, Vietnam, Polonya ve Pakistan’daki müteahhitlerin başına geldiği gibi, Scale AI’dan belirsiz bir şekilde atılırlar. son zamanlarda.
Bazı açıklama ve etiketleme platformları “adil ticaret” çalışması sağladığını iddia ediyor. Aslında bunu markalamalarının merkezi bir parçası haline getirdiler. Ancak MIT Tech Review’dan Kate Kaye olarak notlarEtik etiketleme işinin ne anlama geldiğine ilişkin hiçbir düzenleme yok, yalnızca zayıf endüstri standartları var ve şirketlerin kendi tanımları büyük ölçüde farklılık gösteriyor.
Peki ne yapmalı? Büyük bir teknolojik atılımın dışında, yapay zeka eğitimi için verilere açıklama ekleme ve etiketleme ihtiyacı ortadan kalkmıyor. Platformların kendi kendini düzenlemesini umabiliriz ancak daha gerçekçi çözüm politika oluşturmak gibi görünüyor. Bu başlı başına çetrefilli bir olasılık; ancak bazı şeyleri daha iyiye doğru değiştirmek için elimizdeki en iyi şansın bu olduğunu düşünüyorum. Ya da en azından başlıyoruz.
İşte son birkaç güne ait diğer AI hikayeleri:
-
- OpenAI bir ses klonlayıcı oluşturur: OpenAI, geliştirdiği, kullanıcıların konuşan birinin 15 saniyelik kaydından ses kopyalamasına olanak tanıyan, geliştirdiği yeni yapay zeka destekli araç Voice Engine’in ön izlemesini yapıyor. Ancak şirket, kötüye kullanım ve suiistimal risklerini öne sürerek bunu (henüz) geniş çapta yayınlamamayı tercih ediyor.
- Amazon Anthropic’i ikiye katlıyor: Amazon, geçen Eylül ayında açık bıraktığı seçeneğin ardından Anthropic’in yapay zeka gücünü artırmaya 2,75 milyar dolar daha yatırım yaptı.
- Google.org bir hızlandırıcı başlattı: Google’ın hayırsever kanadı Google.org, üretken yapay zekadan yararlanan teknoloji geliştiren kâr amacı gütmeyen kuruluşların finansmanına yardımcı olmak için 20 milyon dolarlık altı aylık yeni bir program başlatıyor.
- Yeni bir model mimarisi: Yapay zeka girişimi AI21 Labs, verimliliği artırmak için yeni ve yeni bir model mimarisi (durum alanı modelleri veya SSM’ler) kullanan üretken bir yapay zeka modeli Jamba’yı piyasaya sürdü.
- Databricks DBRX’i piyasaya sürüyor: Diğer model haberlerinde Databricks bu hafta OpenAI’nin GPT serisine ve Google’ın Gemini’sine benzer üretken bir yapay zeka modeli olan DBRX’i piyasaya sürdü. Şirket, çeşitli ölçüm gerekçeleri de dahil olmak üzere bir dizi popüler AI kıyaslamasında en son teknolojiye sahip sonuçlara ulaştığını iddia ediyor.
- Uber Eats ve Birleşik Krallık AI düzenlemesi: Natasha, bir Uber Eats kuryesinin yapay zeka önyargısına karşı mücadelesinin, Birleşik Krallık’ın yapay zeka düzenlemeleri kapsamında adaletin kazanılmasının nasıl zor olduğunu gösterdiğini yazıyor.
- AB seçim güvenliği kılavuzu: Avrupa Birliği, Salı günü, çevreyi hedef alan taslak seçim güvenliği yönergeleri yayınladı. iki düzine kapsamında düzenlenen platformlar İçerik öneri algoritmalarının üretken yapay zeka tabanlı dezenformasyon (diğer adıyla siyasi derin sahtekarlıklar) yaymasını önlemeye yönelik yönergeler de dahil olmak üzere Dijital Hizmetler Yasası.
- Grok yükseltildi: X’in Grok sohbet robotu yakında yükseltilmiş bir temel model olan Grok-1.5’e kavuşacak – aynı zamanda X’teki tüm Premium aboneler Grok’a erişim kazanacak. (Grok daha önce X Premium+ müşterilerine özeldi.)
- Adobe, Firefly’ı genişletiyor: Adobe bu hafta Firefly Hizmetlerini tanıttı20’den fazla yeni üretken ve yaratıcı API, araç ve hizmetten oluşan bir dizi. Ayrıca, Adobe’nin yeni GenStudio paketinin bir parçası olan, işletmelerin Firefly modellerinde varlıklarına göre ince ayar yapmalarına olanak tanıyan Özel Modeller’i de başlattı.
Daha fazla makine öğrenimi
Hava nasıl? Yapay zeka size bunu giderek daha fazla söyleyebiliyor. Birkaç ay önce saatlik, haftalık ve yüzyıl ölçeğinde tahminlerde birkaç çaba sarf edildiğini fark ettim, ancak yapay zeka ile ilgili her şey gibi bu alan da hızlı ilerliyor. MetNet-3 ve GraphCast’ın arkasındaki ekipler, yeni bir sistemi açıklayan bir makale yayınladılar. TOHUMLARÖlçeklenebilir Topluluk Zarf Difüzyon Örnekleyici için.
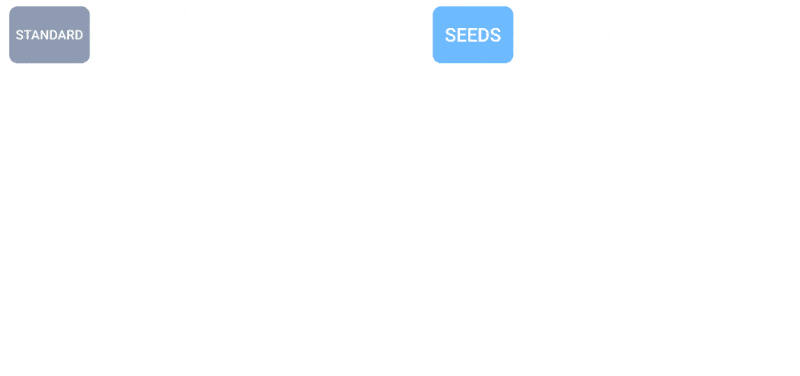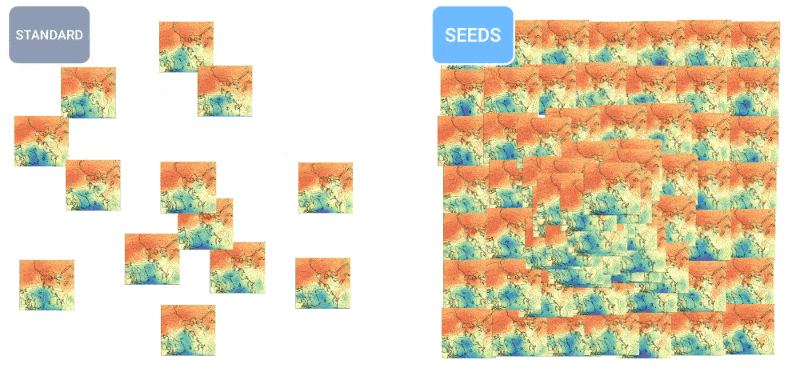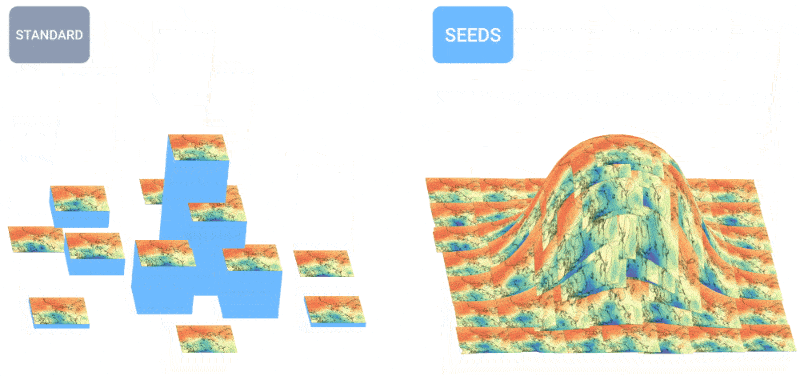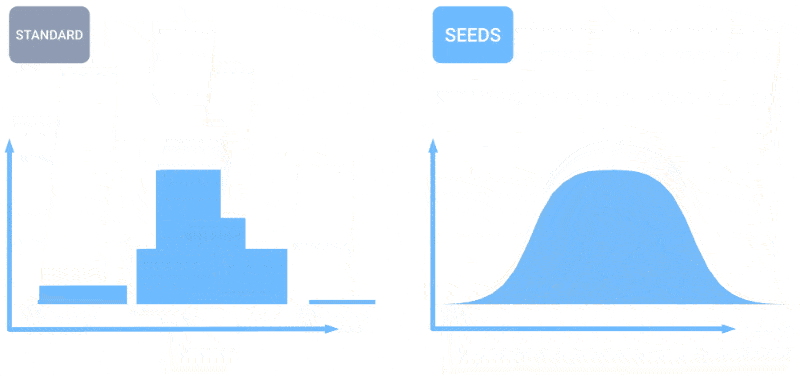
Daha fazla tahminin, hava durumu tahminlerinin nasıl daha eşit bir dağılıma yol açtığını gösteren animasyon.
SEEDS, girdiye dayalı olarak (radar okumaları veya yörünge görüntüleri) bir alan için makul hava durumu sonuçlarının “topluluklarını” oluşturmak için fizik tabanlı modellerden çok daha hızlı bir şekilde difüzyonu kullanır. Daha büyük topluluk sayılarıyla, daha fazla uç durumu kapsayabilirler (örneğin, 100 olası senaryodan yalnızca 1’inde meydana gelen bir olay gibi) ve daha olası durumlar hakkında daha emin olabilirler.
Fujitsu ayrıca doğal dünyayı daha iyi anlamayı umuyor. Yapay zeka görüntü işleme tekniklerinin su altı görüntülerine uygulanması ve su altı otonom araçları tarafından toplanan lidar verileri. Görüntü kalitesinin iyileştirilmesi, diğer daha az karmaşık süreçlerin (3D dönüştürme gibi) hedef veriler üzerinde daha iyi çalışmasına olanak tanıyacaktır.
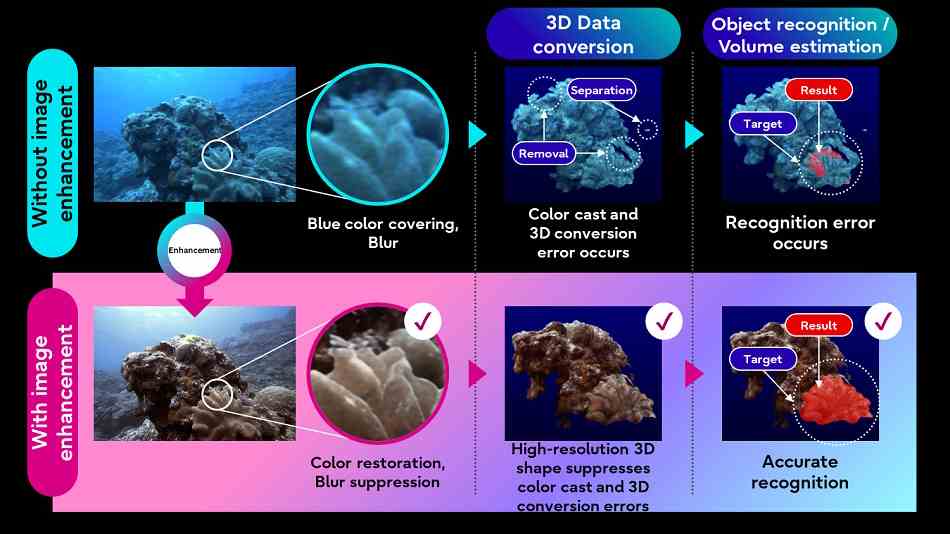
Resim Kredisi: Fujitsu
Buradaki fikir, yeni gelişmeleri simüle etmeye ve tahmin etmeye yardımcı olabilecek bir “dijital ikiz” su inşa etmektir. Bundan çok uzaktayız ama bir yerden başlamalısınız.
Yüksek Lisans öğrencileri arasında araştırmacılar, zekayı beklenenden daha basit bir yöntemle taklit ettiklerini buldular: doğrusal fonksiyonlar. Açıkçası matematik beni aşıyor (birçok boyutta vektörel şeyler) ama MIT’deki bu yazı bu modellerin geri çağırma mekanizmasının oldukça basit olduğunu açıkça ortaya koyuyor.
Bu modeller her ne kadar çok karmaşık, çok sayıda veri üzerinde eğitilmiş, anlaşılması çok zor, doğrusal olmayan fonksiyonlar olsa da bazen içlerinde çalışan çok basit mekanizmalar olabiliyor. Bu da bunun bir örneği” dedi eşbaşkan yazar Evan Hernandez. Daha teknik bir düşünceye sahipseniz, buradaki makaleye göz at.
Bu modellerin başarısız olmasının bir yolu bağlamı veya geri bildirimi anlamamaktır. Gerçekten yetenekli bir Yüksek Lisans bile, adınızın belirli bir şekilde telaffuz edildiğini söylerseniz “anlamayabilir” çünkü aslında hiçbir şey bilmezler veya anlamazlar. İnsan-robot etkileşimleri gibi bunun önemli olabileceği durumlarda, robotun bu şekilde davranması insanları rahatsız edebilir.
Disney Research uzun süredir otomatik karakter etkileşimlerini araştırıyor ve bu adın telaffuzu ve kağıdı yeniden kullanma az önce ortaya çıktı. Açık görünüyor, ancak birisi kendini tanıttığında fonemleri çıkarmak ve sadece yazılı isim yerine bunu kodlamak akıllıca bir yaklaşım.

Resim Kredisi: Disney Araştırması
Son olarak, yapay zeka ve arama giderek daha fazla örtüştüğünden, bu araçların nasıl kullanıldığını ve bu kutsal olmayan birliğin sunduğu yeni risklerin olup olmadığını yeniden değerlendirmek faydalı olacaktır. Safiya Umoja Noble, yıllardır yapay zeka ve arama etiğinde önemli bir ses olmuştur ve görüşleri her zaman aydınlatıcıdır. UCLA haber ekibiyle güzel bir röportaj yaptı işinin nasıl geliştiğini ve aramadaki önyargı ve kötü alışkanlıklar söz konusu olduğunda neden soğukkanlı kalmamız gerektiğini anlattı.