

Nvidia’nın kurucu ortağı ve CEO’su Jensen Huang, selefi H100 “Hopper” ile karşılaştırmak için yeni Blackwell çipini solda gösterdi. Nvidia
Nvidia CEO’su Jensen Huang Pazartesi günü yapay zeka çip üreticisinin, San Jose, California’da düzenlenen, COVID-19 salgınından bu yana ilk yüz yüze teknoloji konferansı olan GPU Teknoloji Konferansı veya GTC’ye başkanlık etti ve şirketin çipleri için kod adı verilen yeni tasarımını açıkladı. “Blackwell“.
Birçoğu GTC’yi “Yapay Zekanın Woodstock’u” veya “Yapay Zekanın Lalapalooza’sı” olarak görüyor. Konferansın başlangıcındaki yüksek alkışların ardından Bay Huang, “Umarım bunun bir konser olmadığını anlıyorsunuzdur” dedi. Mevcut ortakların ve müşterilerin listesini memnuniyetle karşıladı.
Huang, Dell’in kurucusu ve CEO’sunun da izleyiciler arasında olduğunu belirterek, “Michael Dell orada oturuyor” dedi.
Saniyede 2.000 trilyon kayan nokta işlemi
Bay Huang, üretken yapay zekanın (GenAI) büyük dil modellerini eğitmek için gereken hesaplama ölçeğine odaklandı. Bay Huang, trilyonlarca “jeton” veya kelime parçalarını temsil eden eğitim verileriyle birleştirilmiş trilyonlarca parametreden oluşan bir modelin “30 milyar katrilyon kayan nokta işlemi” veya 30 milyar petaFLOPS gerektireceğini belirtti. “Bir petaFLOP GPU’nuz olsaydı, bu modeli hesaplamak ve eğitmek 30 milyar saniyenizi alırdı; 30 milyar saniye yaklaşık 1.000 yıl demektir.
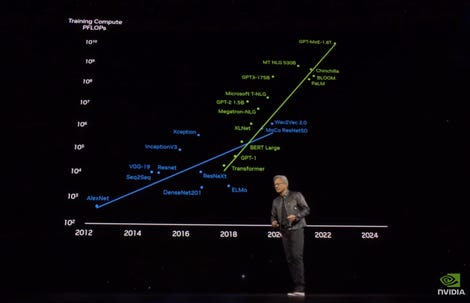
Bay Huang, sunumuna artan yapay zeka iş yükü boyutuna genel bir bakışla başladı ve en güçlü çiplerin eğitiminin 30 milyar saniye veya 1000 yıl süreceğini belirtti. Nvidia
Nvidia’nın en yeni yongası olan H100 GPU, saniyede yaklaşık 2.000 trilyon kayan nokta işlemi veya 2.000 TFLOPS gerçekleştirebilir. Bin TFLOPS bir petaFLOP’a eşittir, yani H100 ve kardeşi H200 yalnızca birkaç petaFLOP’u işleyebilir, bu da Huang’ın referans verdiği 30 milyarın çok altında.
“İhtiyacımız olan şey daha büyük GPU’lar; çok daha büyük GPU’lara ihtiyacımız var” dedi.
Hopper GPU’larındaki 80 milyar transistörün iki katından fazlası
Sektörde “HopperNext” olarak bilinen Blackwell, GPU başına 20 petaFLOPS’a ulaşabiliyor. 8 yollu bir sistemle teslim edilmesi amaçlanmaktadır. “HGX” baskılı devre kartı çipleri.
Bir sinir ağındaki her değerin daha az ondalık basamak kullanılarak temsil edildiği bir tür sıkıştırılmış matematiksel işlem olan “kuantizasyon”u kullanan ve “FP4” olarak adlandırılan çip, bir HGX sisteminde 144’e kadar petaFLOP gerçekleştirebilir.
Huang, çipin 208 milyar transistöre sahip olduğunu ve Tayvan Yarı İletken Üretimi’nin “4NP” olarak bilinen özel bir yarı iletken üretim sürecini kullandığını söyledi. Bu, Hopper GPU’larındaki 80 milyar transistörün iki katından fazladır.

Nvidia Blackwell GPU, saniye başına kayan nokta matematik işlemlerinin sayısını on kat artırır ve kendisinden önceki “Hopper” serisinin transistör sayısını iki katından fazla artırır. Nvidia, çipin büyük dil modellerini 25 kat daha hızlı çalıştırma yeteneğini öne çıkarıyor. Nvidia
Kullanıcılar arasında AWS, Dell, Google, Meta, Microsoft, OpenAI, Oracle, Tesla ve xAI
Huang, Blackwell’in trilyonlarca parametreye sahip büyük üretken yapay zeka dil modellerini önceki çiplerden 25 kat daha hızlı çalıştırabildiğini söyledi.
Çipin adı verildi David Harold BlackwellNvidia’nın söylediğine göre “oyun teorisi ve istatistik alanında uzmanlaşmış bir matematikçi ve Ulusal Bilimler Akademisi’ne alınan ilk siyahi araştırmacı.”
Blackwell çipi, Nvidia’nın yüksek hızlı ağ bağlantısı NVLink’in her GPU’ya saniyede 1,8 terabayt sağlayan yeni bir sürümünü kullanıyor. Çipin ayrı bir kısmı, çipin “güvenilirliğini, kullanılabilirliğini ve servis verilebilirliğini” korumak için Nvidia’nın “RAS motoru” dediği şeydir. Bir dizi dekompresyon devresi, veritabanı sorguları gibi şeylerin performansını artırır.
Blackwell’i ilk benimseyenler arasında Amazon Web Services, Dell, Google, Meta, Microsoft, OpenAI, Oracle, Tesla ve xAI yer alıyor.
GB200 Grace Blackwell Süper Çipi
Öncekiler gibi, iki Blackwell GPU, Nvidia’nın “Grace” mikroişlemcilerinden biriyle birleştirilerek “GB200 Grace Blackwell Superchip” adı verilen birleşik bir çip üretilebiliyor.

Kendisinden önceki Hopper GPU’ları gibi, iki Blackwell GPU da bir Nvidia Grace mikroişlemciyle birleştirilerek “GB200 Grace Blackwell Superchip” adı verilen birleşik bir çip üretilebilir. Nvidia
36 Grace ve 72 GPU birleştirilebilir Nvidia’nın “GB200 NVL72” adını verdiği raf bilgisayarı 1.440 petaFLOP’a ulaşabiliyor ve böylece Huang’ın belirttiği milyar petaFLOP’a yaklaşıyor.
Cipsler için yeni bir sistem, DGX SuperPOD“onbinlerce” Grace Blackwell Süper Çipini birleştirerek saniyedeki işlem sayısını daha da artırır.
Nvidia, Blackwell’in yanı sıra başka duyurular da yaptı:
-
Yeni üretken yapay zeka algoritmaları yarı iletken tasarım sürecinde kullanılan fotolitografiye atıfta bulunarak “cuLitho” olarak bilinen yarı iletken tasarım algoritmalarından oluşan mevcut kütüphanesini geliştirmek. GenAI kodu, litografi için bir başlangıç “foto maskesi” oluşturuyor ve bu daha sonra geleneksel yöntemlerle iyileştirilebiliyor.
Bu fotoğraf maskelerinin tasarımını %100 hızlandırır. TSMC ve çip tasarımı yazılımı üreticisi Synopsys, cuLitho ve yeni GenAI işlevlerini teknolojilerine entegre ediyor. - Yeni bir çizgi ağ anahtarları ve ağ arayüz kartları Nvidia’nın Mellanox’u tarafından geliştirilen InfiniBand teknolojisine dayanan “Quantum-X800 Infiniband” ve Ethernet ağ standardı “Spectrum-X800 Ethernet”. Her iki teknoloji de saniyede 800 milyar bit veya 800 Gbps sağlıyor. Nvidia, anahtarların ve ağ arayüz kartlarının, çiplerin kayan nokta işlemlerinin hızını idare etmek için “trilyon parametreli GPU hesaplama için optimize edildiğini” söylüyor.
- Bir katalog 25 “mikro hizmet” Özel AI modelleri de dahil olmak üzere bireysel uygulamalar için önceden oluşturulmuş, Nvidia’nın “NIM” konteyner yazılım paketi üzerine inşa edilmiş ve bu da şirketin AI Enterprise yazılım teklifinin bir parçası olan bulut tabanlı uygulama konteyner hizmetleri yazılımı.
Programlar, şirketin “bulutlar, veri merkezleri, iş istasyonları ve daha fazla iş istasyonu ve PC’de yüz milyonlarca GPU içeren Nvidia’nın CUDA kurulu tabanı için optimize edilmiş özel AI modellerini çalıştırmanın standartlaştırılmış bir yolu” olarak tanımladığı programlardır. Mikro hizmetler şunları içerir: yaşam bilimlerine odaklanan bir dizi hizmetBunlardan bazıları “üretken biyoloji”, kimya ve “moleküler tahmin” görevlerine ayrılmış olup, “görüntüleme, tıbbi teknoloji, ilaç keşfi ve dijital sağlık alanlarında büyüyen bir model koleksiyonu için” çıkarım” ve tahmin oluşturmayı gerçekleştirmek üzere tasarlanmıştır. . Mikro hizmetler, Dell ve diğer satıcıların sistemleri aracılığıyla, AWS, Google Cloud, Microsoft Azure ve Oracle Cloud Infrastructure gibi genel bulut hizmetleri aracılığıyla edinilebilir ve Nvidia’nın kendi bulut hizmetinde test edilebilir. - Earth-2, ayrı bir mikro hizmet olarak tasarlandı Aşırı hava koşullarının “dijital ikiz” simülasyonu, “geleneksel CPU odaklı modellemede dakikalar veya saatlere kıyasla güncel uyarıları ve tahminleri saniyeler içinde sunmayı” amaçlıyor. Teknoloji, Nvidia tarafından oluşturulan ve “CorrDiff” adı verilen, mevcut dijital modellere göre “12,5 kat daha yüksek çözünürlüklü hava durumu görüntüleri” oluşturabilen, 1000 kat daha hızlı ve 3000 kat daha fazla enerji verimliliği sağlayan üretken bir yapay zeka modeline dayanıyor. The Weather Company bu teknolojiyi ilk benimseyenlerden biridir.
-
Ürün ve teknoloji duyurularına ek olarak Nvidia, iş ortaklarıyla birlikte bir dizi girişimi de duyurdu:
- A Oracle ile işbirliği Yapay zeka programlarının yerel olarak, “bir ülke veya kuruluşun güvenli tesislerinde” yürütülmesine olanak tanıyan “egemen yapay zeka” için.
- Yeni bir süper bilgisayar Amazon AWS için “Ceiba” adı verilen, Blackwell yongaları kullanılarak DGX sistemlerinden oluşturulan.

Yapabilirsiniz Açılış konuşmasının tamamını YouTube’da izleyin.
Kaynak : “ZDNet.com”