
Yapay zeka kadar hızlı hareket eden bir sektöre ayak uydurmak zorlu bir iştir. Yani bir yapay zeka bunu sizin için yapana kadar, kendi başımıza ele almadığımız dikkate değer araştırma ve deneylerin yanı sıra, makine öğrenimi dünyasındaki son hikayelerin kullanışlı bir özetini burada bulabilirsiniz.
Geçen hafta, Midjourney, AI startup binası görseli (ve yakında video) jeneratörler, şirketin fikri mülkiyet anlaşmazlıklarına ilişkin politikasıyla ilgili hizmet koşullarında göz açıp kapayıncaya kadar küçük bir değişiklik yaptı. Esas olarak şakacı dilin daha hukuka uygun ve şüphesiz içtihatlara dayalı maddelerle değiştirilmesine hizmet etti. Ancak bu değişiklik aynı zamanda Midjourney’in, kendisi gibi yapay zeka satıcılarının, çalışmaları satıcıların eğitim verilerini oluşturan yaratıcılarla mahkeme salonu savaşlarında galip geleceğine dair inancının bir işareti olarak da alınabilir.

Midjourney’in hizmet koşullarındaki değişiklik.
Midjourney’inki gibi üretken yapay zeka modelleri, genellikle web’deki halka açık web sitelerinden ve depolardan alınan çok sayıda örnek (örneğin, resimler ve metinler) üzerinde eğitilir. Satıcılar iddia ediyor Dönüştürücü olduğu sürece, telif hakkıyla korunan eserlerin ikincil bir eser oluşturmak için kullanılmasına izin veren yasal doktrin olan adil kullanım, model eğitimi söz konusu olduğunda bunları korur. Ancak tüm içerik oluşturucular aynı fikirde değil; özellikle de modellerin eğitim verilerini “yeniden oluşturabildiğini” ve yaptığını gösteren artan sayıda çalışma ışığında.
Bazı satıcılar proaktif bir yaklaşım benimseyerek içerik oluşturucularla lisans anlaşmaları imzaladı ve eğitim veri kümeleri için “devre dışı kalma” planları oluşturdu. Diğerleri, müşterilerin bir satıcının GenAI araçlarını kullanmalarından kaynaklanan bir telif hakkı davasına dahil olmaları durumunda, yasal ücretler için mağdur olmayacaklarının sözünü verdiler.
Midjourney proaktif olanlardan biri değil.
Aksine, Midjourney telif hakkıyla korunan eserleri kullanma konusunda bir noktada biraz küstahça davrandı. sürdürmek Eserleri Midjourney modellerini eğitmek için kullanılan veya kullanılacak olan, Hasbro ve Nintendo gibi büyük markaların illüstratörleri ve tasarımcıları da dahil olmak üzere binlerce sanatçının listesi. A çalışmak Midjourney’in eğitim verilerinde “Oyuncak Hikayesi”nden Yıldız Savaşları”na, “Dune”dan “Yenilmezler”e kadar TV şovları ve film serilerini kullandığına dair ikna edici kanıtlar gösteriyor.
Şimdi, mahkeme salonundaki kararların sonunda Midjourney’in lehine sonuçlandığı bir senaryo var. Adalet sistemi adil kullanımın geçerli olduğuna karar verirse, hiçbir şey startup’ın eski ve yeni telif hakkıyla korunan verileri ayıklayarak ve bunlar üzerinde eğitim vererek devam etmesine engel olamaz.
Ama riskli bir bahis gibi görünüyor.
Midjourney şu anda yükseklerde uçuyor, bildirildiğine göre Bir kuruş bile dış yatırım yapmadan yaklaşık 200 milyon dolar gelire ulaştı. Ancak avukatlar pahalıdır. Ve Midjourney davasında adil kullanımın geçerli olmadığına karar verilirse, bu durum şirketin bir gecede yok olmasına neden olacaktır.
Risk olmadan ödül olmaz, değil mi?
İşte son birkaç güne ait diğer AI hikayeleri:
Yapay zeka destekli reklam yanlış türde dikkat çekiyor: Instagram’daki içerik oluşturucular, reklamında başka birinin (çok daha zor ve etkileyici) çalışmalarını kaynak göstermeden yeniden kullanan bir yönetmene sert tepki gösterdi.
AB yetkilileri seçimlerden önce yapay zeka platformlarını uyarıyor: Teknoloji dünyasının en büyük şirketlerinden seçim saçmalıklarını önlemeye yönelik yaklaşımlarını açıklamalarını istiyorlar.
Google Deepmind, kooperatif oyun ortağınızın kendi yapay zekası olmasını istiyor: Bir temsilciyi saatlerce 3D oyun oynama konusunda eğitmek, onun doğal dilde ifade edilen basit görevleri yerine getirebilmesini sağladı.
Benchmarklarla ilgili sorun: Pek çok yapay zeka satıcısı, modellerinin rekabeti karşıladığını veya objektif bir ölçümle yenildiğini iddia ediyor. Ancak kullandıkları ölçümler çoğu zaman kusurludur.
AI2’nin puanı 200 milyon dolar: Kâr amacı gütmeyen Allen Yapay Zeka Enstitüsü’nden doğan AI2 Incubator, programından geçen startup’ların erken gelişimi hızlandırmak için yararlanabileceği beklenmedik bir şekilde 200 milyon dolarlık bir bilgi işlem elde etti.
Hindistan, yapay zeka için hükümet onayını talep ediyor, ardından geri alıyor: Hindistan hükümeti yapay zeka endüstrisi için hangi düzeyde düzenlemenin uygun olduğuna karar veremiyor gibi görünüyor.
Anthropic yeni modelleri piyasaya sürüyor: Yapay zeka girişimi Anthropic, OpenAI’nin GPT-4’üne rakip olduğunu iddia ettiği yeni bir model ailesi olan Claude 3’ü piyasaya sürdü. Amiral gemisi modelini (Claude 3 Opus) teste tabi tuttuk ve etkileyici bulduk; ancak aynı zamanda güncel olaylar gibi alanlarda da eksikti.
Siyasi deepfake’ler: Britanyalı kar amacı gütmeyen bir kuruluş olan Dijital Nefretle Mücadele Merkezi’nin (CCDH) yaptığı bir araştırma, geçtiğimiz yıl X’te (eski adıyla Twitter) yapay zeka tarafından üretilen dezenformasyonun (özellikle seçimlerle ilgili derin sahte görsellerin) artan hacmini inceliyor.
OpenAI, Musk’a karşı: OpenAI, X CEO’su Elon Musk tarafından yakın zamanda açılan bir davada ileri sürülen tüm iddiaları reddetme niyetinde olduğunu söyledi ve şirketin kurucu ortağı olan milyarder girişimcinin OpenAI’nin gelişimi üzerinde pek bir etkisi olmadığını öne sürdü. ve başarı.
Rufus’u incelemek: Geçen ay Amazon, Android ve iOS için Amazon Alışveriş uygulamasında yeni AI destekli sohbet robotu Rufus’u piyasaya süreceğini duyurdu. Erken erişime sahip olduk ve Rufus’un yapabileceği (ve iyi yaptığı) şeylerin eksikliği yüzünden hemen hayal kırıklığına uğradık.
Daha fazla makine öğrenimi
Moleküller! Nasıl çalışıyorlar? Yapay zeka modelleri, moleküler dinamikleri, konformasyonu ve nanoskobik dünyanın aksi takdirde test edilmesi pahalı ve karmaşık yöntemler gerektirebilecek diğer yönlerini anlamamıza ve tahmin etmemize yardımcı oldu. Elbette yine de doğrulamanız gerekiyor, ancak AlphaFold gibi şeyler alanı hızla değiştiriyor.
Microsoft’un ViSNet adında yeni bir modeli var, yapı-aktivite ilişkileri, moleküller arasındaki karmaşık ilişkiler ve biyolojik aktivite olarak adlandırılan şeyleri tahmin etmeyi amaçladı. Hala oldukça deneysel ve kesinlikle yalnızca araştırmacılar için, ancak zor bilim problemlerinin en son teknoloji araçlarıyla ele alındığını görmek her zaman harika.
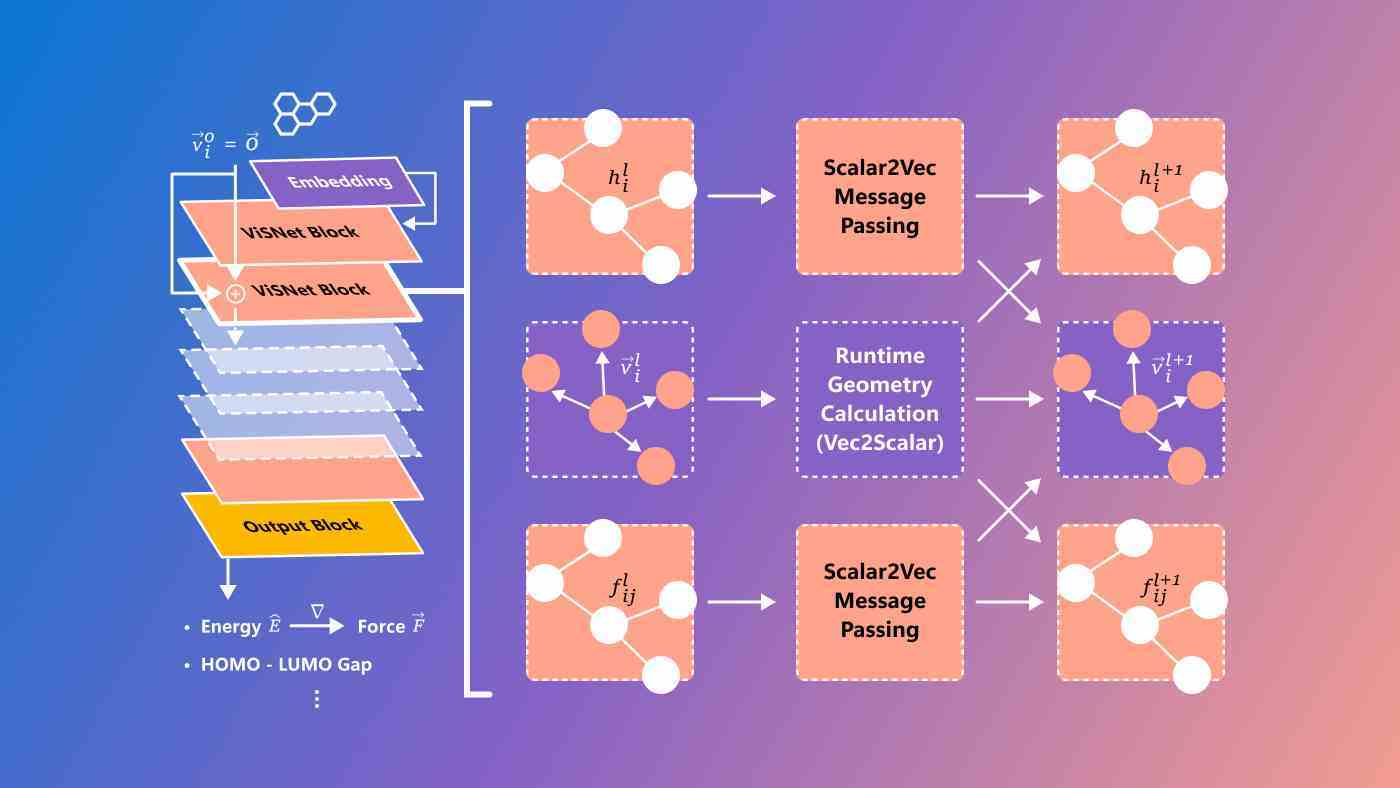
Resim Kredisi: Microsoft
Manchester Üniversitesi araştırmacıları özellikle COVID-19 varyantlarını tanımlama ve tahmin etmeViSNet gibi saf yapılardan daha az, daha çok ise koronavirüs evrimiyle ilgili çok büyük genetik veri kümelerinin analiziyle.
Baş araştırmacı Thomas House, “Pandemi sırasında üretilen benzeri görülmemiş miktardaki genetik veri, onu kapsamlı bir şekilde analiz etme yöntemlerimizde iyileştirmeler gerektiriyor” dedi. Meslektaşı Roberto Cahuantzi şunları ekledi: “Analizimiz, ortaya çıkan ana değişkenlerin erken keşfi için bir uyarı aracı olarak makine öğrenimi yöntemlerinin potansiyel kullanımını gösteren bir kavram kanıtı olarak hizmet ediyor.”
Yapay zeka moleküller de tasarlayabilir ve bazı araştırmacılar bir girişime imza attı Bu alanda güvenlik ve etik çağrısında bulunuyoruz. Ancak David Baker’ın (dünyanın önde gelen hesaplamalı biyofizikçilerinden biri) belirttiği gibi, “Protein tasarımının potansiyel faydaları, bu noktada tehlikelerin çok ötesindedir.” Yapay zeka protein tasarımcılarının tasarımcısı olarak o istemek şunu söyle. Ancak yine de, asıl noktayı kaçıran ve meşru araştırmayı engelleyen ve kötü aktörlere özgürlük tanıyan düzenlemelere karşı dikkatli olmalıyız.
Washington Üniversitesi’ndeki atmosfer bilimciler, Türkmenistan üzerindeki 25 yıllık uydu görüntülerinin yapay zeka analizine dayanarak ilginç bir iddiada bulundular. Esasen, Sovyetler Birliği’nin çöküşünün ardından yaşanan ekonomik çalkantının emisyonların azalmasına yol açtığına dair kabul edilen anlayış doğru olmayabilir. aslında tam tersi de olmuş olabilir.
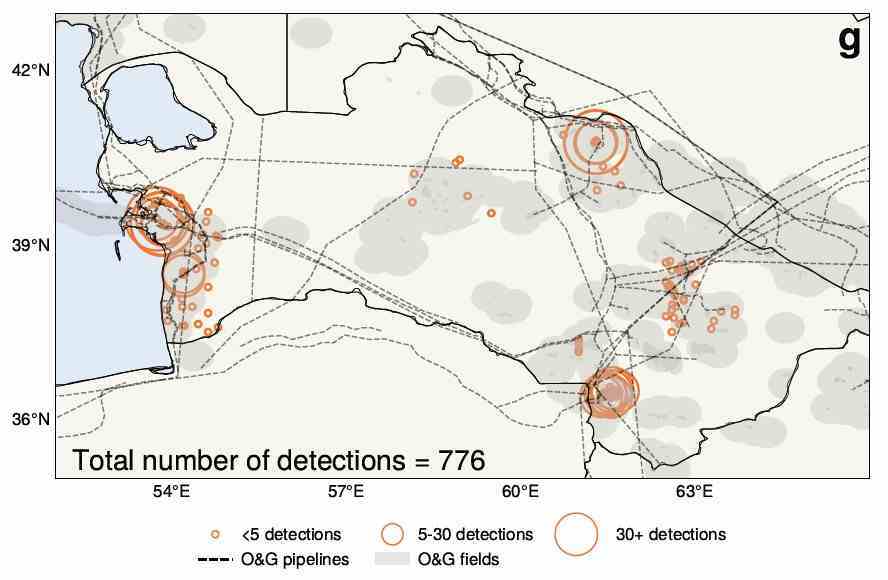
Yapay zeka, burada gösterilen metan sızıntılarının bulunmasına ve ölçülmesine yardımcı oldu.
UW profesörü Alex Turner, “Sovyetler Birliği’nin çöküşünün şaşırtıcı bir şekilde metan emisyonlarında artışa yol açtığını görüyoruz” dedi. Büyük veri kümeleri ve bunları incelemek için zaman eksikliği, konuyu yapay zeka için doğal bir hedef haline getirdi ve bu da beklenmedik bir tersine dönüşle sonuçlandı.
Büyük dil modelleri büyük ölçüde İngilizce kaynak verilerine göre eğitilir, ancak bu onların diğer dilleri kullanma becerilerini daha fazla etkileyebilir. LlaMa-2’nin “gizli dilini” inceleyen EPFL araştırmacıları, Fransızca ve Çince arasında çeviri yaparken bile modelin görünüşte dahili olarak İngilizceye döndüğünü buldu. Ancak araştırmacılar bunun tembel bir çeviri sürecinden daha fazlası olduğunu ve aslında modelin tüm kavramsal gizli alanını İngilizce kavram ve temsiller etrafında yapılandırdı. Önemli mi? Muhtemelen. Zaten veri kümelerini çeşitlendirmeliyiz.