
Oyun oynayan yapay zeka modelleri onlarca yıl öncesine dayanıyor ancak genellikle tek bir oyunda uzmanlaşıyorlar ve her zaman kazanmak için oynuyorlar. Google Deepmind araştırmacılarının en son yaratımlarıyla farklı bir hedefi var: Bir insan gibi birden fazla 3D oyun oynamayı öğrenen, aynı zamanda sözlü talimatlarınızı anlayıp bunlara göre hareket etmek için elinden gelenin en iyisini yapan bir model.
Elbette bu tür şeyleri yapabilen “AI” veya bilgisayar karakterleri var, ancak bunlar daha çok bir oyunun özelliklerine benzer: Dolaylı olarak kontrol etmek için resmi oyun içi komutları kullanabileceğiniz NPC’ler.
Deepmind’ın SIMA’sının (ölçeklenebilir talimat verilebilir çoklu dünya aracısı) oyunun dahili koduna veya kurallarına herhangi bir erişimi yoktur; bunun yerine, insanların oynadığı saatlerce süren videolarla eğitildi. Bu verilerden ve veri etiketleyiciler tarafından sağlanan ek açıklamalardan model, eylemlerin, nesnelerin ve etkileşimlerin belirli görsel temsillerini ilişkilendirmeyi öğrenir. Ayrıca oyuncuların birbirlerine oyunda bir şeyler yapma talimatı verdiği videoları da kaydettiler.
Örneğin piksellerin ekranda belirli bir düzende nasıl hareket ettiğinden bunun “ileri gitme” olarak adlandırılan bir eylem olduğunu veya karakterin kapı benzeri bir nesneye yaklaşıp kapı tokmağı görünümlü nesneyi kullanmasının “açılma” olduğunu öğrenebilir. bir kapı.” Bunun gibi basit şeyler, birkaç saniye süren görevler veya olaylar, yalnızca bir tuşa basmaktan veya bir şeyi tanımlamaktan daha fazlasıdır.
Eğitim videoları, Valheim’dan Goat Simulator 3’e kadar, geliştiricilerin yazılımlarının bu şekilde kullanılmasına dahil olan ve buna izin veren birçok oyunda çekildi. Araştırmacılar, basınla yapılan bir görüşmede ana hedeflerden birinin, bir yapay zekayı belirli bir oyun setini oynayacak şekilde eğitmenin, onu görmediği diğer oyunları oynama yeteneğine sahip hale getirip getirmediğini görmek olduğunu söyledi; bu süreç genelleme olarak adlandırılıyor.
Cevap evet, uyarılarla birlikte. Birden fazla oyun üzerinde eğitim almış yapay zeka ajanları, daha önce karşılaşmadıkları oyunlarda daha iyi performans gösterdi. Ancak elbette birçok oyun, en iyi hazırlanmış yapay zekayı engelleyecek spesifik ve benzersiz mekanikler veya terimler içerir. Ancak eğitim verilerinin eksikliği dışında modelin bunları öğrenmesini engelleyen hiçbir şey yok.
Bunun nedeni kısmen, oyun içi çok fazla dil olmasına rağmen, oyuncuların sahip olduğu ve oyun dünyasını gerçekten etkileyen çok fazla “fiil” bulunmasıdır. İster bir yaslanma yeri kuruyor olun, ister çadır kuruyor olun, ister büyülü bir barınak çağırıyor olun, aslında “bir ev inşa ediyorsunuz”, değil mi? Dolayısıyla, ajanın şu anda tanıdığı birkaç düzine ilkelden oluşan bu haritayı incelemek gerçekten ilginç:
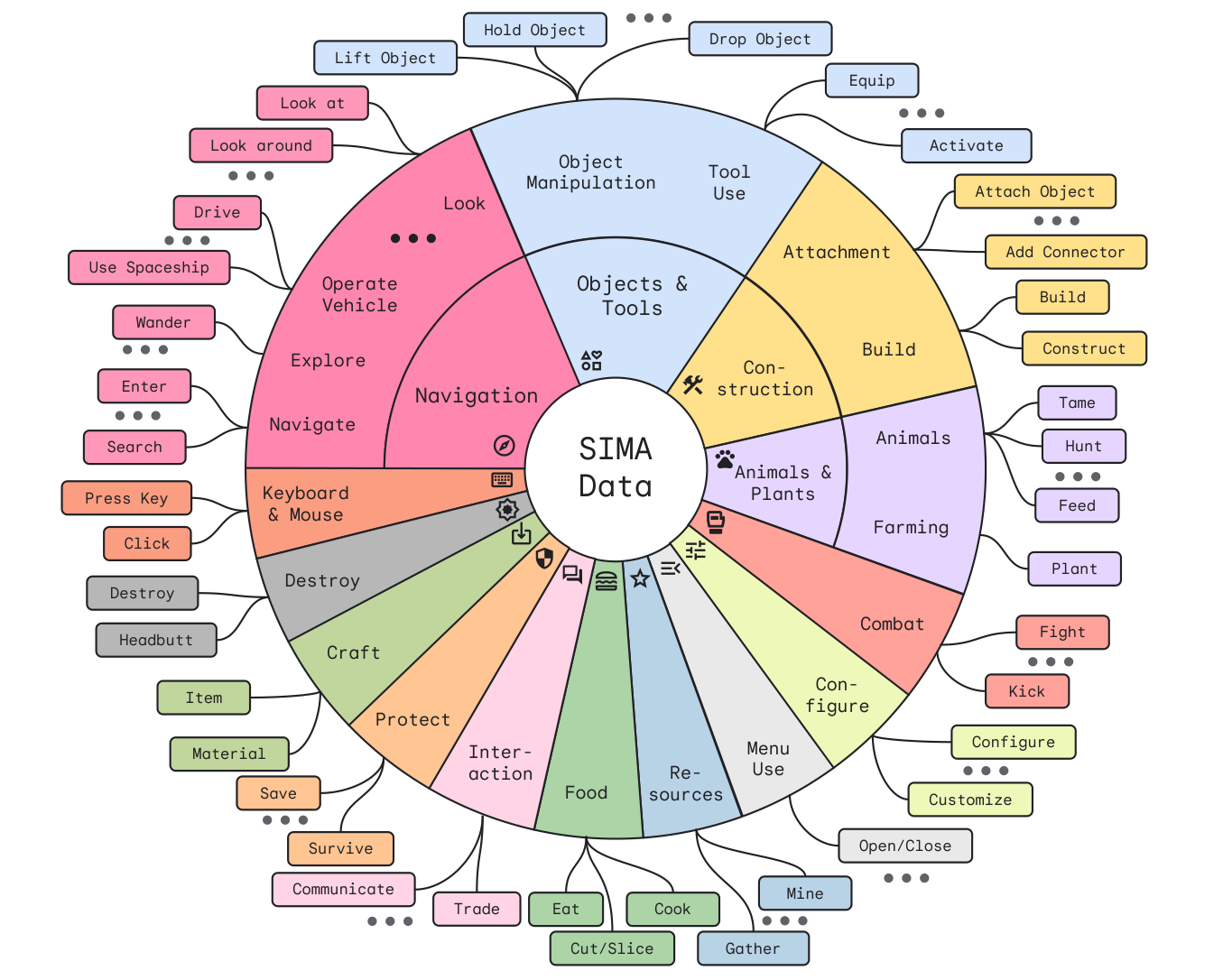
SIMA’nın tanıdığı, gerçekleştirebildiği veya birleştirebildiği birkaç düzine eylemin haritası.
Araştırmacıların amacı, temelde ajan tabanlı yapay zeka konusunda topu ilerletmenin yanı sıra, bugün sahip olduğumuz katı, sabit kodlu oyun arkadaşlarından daha doğal bir oyun oynama arkadaşı yaratmaktır.
Projenin liderlerinden biri olan Tim Harley, “Karşısında oynadığınız insanüstü bir ajan yerine, yanınızda işbirlikçi, talimat verebileceğiniz SIMA oyuncuları olabilir” dedi.
Oynarken gördükleri tek şey oyun ekranının pikselleri olduğundan, işleri bizim yaptığımız gibi yapmayı öğrenmeleri gerekiyor – ama bu aynı zamanda uyum sağlayıp yeni davranışlar üretebilecekleri anlamına da geliyor.
Bunun, çoğunlukla denetlenmeyen bir modelin, gerçek zamandan çok daha hızlı çalışan, 3 boyutlu simüle edilmiş bir dünyada çılgınca deneyler yaptığı ve kuralları sezgisel olarak öğrenmesine olanak tanıyan, etmen tipi yapay zeka oluşturmanın yaygın bir yöntemi olan simülatör yaklaşımıyla nasıl örtüştüğünü merak ediyor olabilirsiniz. ve neredeyse aynı miktarda açıklama çalışması gerektirmeden etraflarındaki davranışları tasarlayın.
“Geleneksel simülatör tabanlı temsilci eğitimi, eğitim için takviyeli öğrenmeyi kullanır; bu, oyun veya ortamın temsilcinin öğrenebileceği bir ‘ödül’ sinyali sağlamasını gerektirir – örneğin Go veya Starcraft durumunda kazanç/mağlubiyet veya ‘puan’ Atari için” diye TechCrunch’a konuşan Harley, bu yaklaşımın bu oyunlar için kullanıldığını ve olağanüstü sonuçlar ürettiğini belirtti.
“Ortaklarımızın ticari oyunları gibi kullandığımız oyunlarda böyle bir ödül sinyaline erişimimiz yok. Ayrıca, açık uçlu metinde açıklanan çok çeşitli görevleri yerine getirebilen aracılarla ilgileniyoruz; her oyunun, her olası hedef için bir ‘ödül’ sinyali değerlendirmesi mümkün değildir. Bunun yerine, metinde verilen hedeflerle insan davranışından taklit öğrenmeyi kullanarak aracıları eğitiyoruz.”
Başka bir deyişle, katı bir ödül yapısına sahip olmak, temsilcinin peşinde olduğu şeyi sınırlayabilir, çünkü puana göre yönlendirilirse asla bu değeri maksimuma çıkarmayan hiçbir şeye kalkışmayacaktır. Ancak eyleminin daha önce çalıştığını gözlemlediği eyleme ne kadar yakın olduğu gibi daha soyut bir şeye değer veriyorsa, eğitim verileri onu bir şekilde temsil ettiği sürece neredeyse her şeyi yapmayı “istemek” üzere eğitilebilir.
Diğer şirketler bu tür şeyleri araştırıyor açık uçlu işbirliği ve yaratım ilave olarak; Örneğin, NPC’lerle yapılan görüşmelere, LLM tipi bir sohbet robotunun çalıştırılması için fırsatlar olarak oldukça sıkı bir şekilde bakılıyor. Basit doğaçlama eylemler veya etkileşimler de yapay zeka tarafından simüle ediliyor ve ajanlara yönelik gerçekten ilginç bazı araştırmalarda takip ediliyor.
Tabii ki MarioGPT gibi sonsuz oyunlarla ilgili deneyler de var, ama bu tamamen başka bir konu.