
Ne AMD ne de Nvidia, Instinct MI300X ve H100 (Hopper) GPU’lar arasındaki performans farkıyla ilgili bu tartışmadan geri adım atmaya niyetli değil. Ancak AMD, yalnızca TensorRT-LLM ile çalışan FP8’e karşı daha popüler bir seçim olan vLLM’yi kullanan FP16’yı karşılaştırırken bazı güçlü noktalara dikkat çekiyor.
Kırmızı takım, MI300X grafik hızlandırıcısını bu Aralık ayının başlarında duyurdu ve Nvidia’nın H100’üne göre 1,6 kata kadar önde olduğunu iddia etti. İki gün önce Nvidia, AMD’nin H100’ü TensorRT-LLM ile karşılaştırırken optimizasyonlarını kullanmadığını söyleyerek karşılık verdi. Cevap, Llama 2 70B sohbet modelini çalıştırırken sekiz yönlü H100 GPU’lara karşı tek bir H100’e ulaştı.
Devam Eden Karşılaştırmalı Karşılaştırma Sonuçları ve Test Senaryoları Savaşı
AMD, bu son yanıtında Nvidia’nın seçici bir dizi çıkarım iş yükü kullandığını söyledi. Ayrıca Nvidia’nın bunları, açık kaynaklı ve yaygın olarak kullanılan bir yöntem olan vLLM yerine H100 üzerinde şirket içi TensorRT-LLM’yi kullanarak kıyasladığını belirledi. Ayrıca Nvidia, AMD’de vLLM FP16 performans veri tipini kullanarak sonuçlarını, yanlış yorumlandığı iddia edilen bu sonuçları görüntülemek için FP8 veri tipi ile TensorRT-LLM’yi kullanan DGX-H100 ile karşılaştırdı. AMD, testinde yaygın kullanımından dolayı FP16 veri seti ile vLLM kullandığını, vLLM’nin FP8’i desteklemediğini vurguladı.
Ayrıca sunucuların gecikmeye sahip olacağı da bir nokta var, ancak AMD’ye göre Nvidia bunu hesaba katmak yerine gerçek dünyadaki durumu taklit etmeden üretim performansını gösterdi.
AMD’nin Daha Fazla Optimizasyonla Güncellenmiş Test Sonuçları ve Nvidia’nın Test Yöntemiyle Gecikmenin Hesaplanması
AMD, Nvidia’nın TensorRT-LLM’sini kullanarak üç performans çalışması gerçekleştirdi; bunlardan sonuncusu, MI300X ile vLLM arasındaki gecikme sonuçlarını TensorRT-LLM ile H100’e karşı FP16 veri setini kullanarak ölçtü. Ancak ilk test, her ikisinde de vLLM, dolayısıyla FP16 kullanarak ikisi arasında bir karşılaştırmayı içeriyordu ve ikinci test için TensorRT-LLM’yi karşılaştırırken MI300X’in performansını vLLM ile karşılaştırdı.
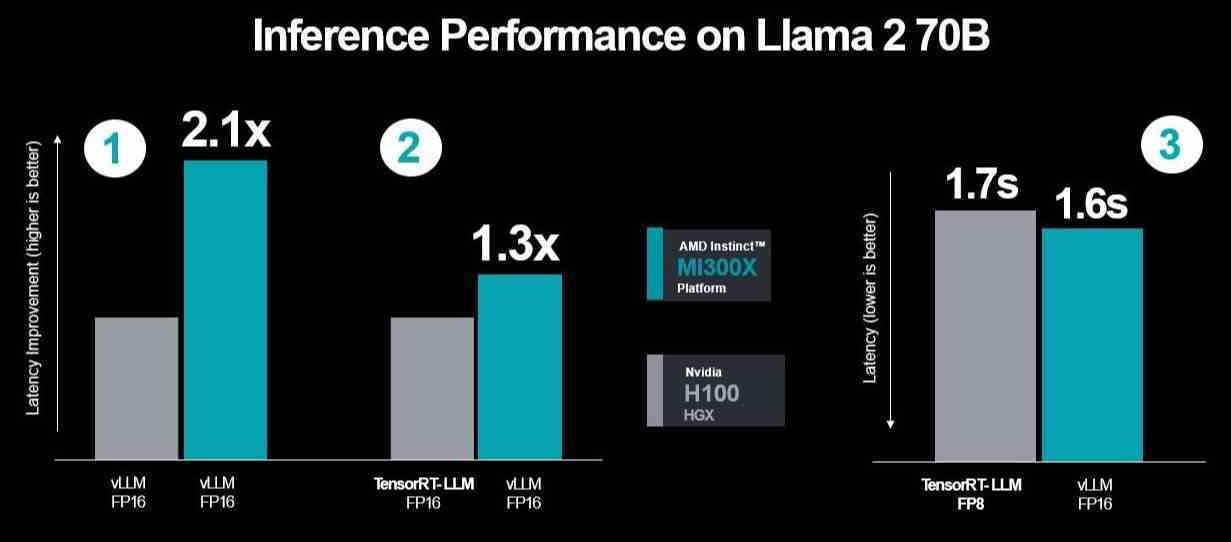
Bu nedenle AMD, Nvidia’nın ikinci ve üçüncü test senaryolarında kullandığı seçili test senaryosunun aynısını kullanarak daha yüksek performans ve daha düşük gecikme gösterdi. Şirket, her ikisinde de vLLM çalıştırırken H100’e kıyasla daha fazla optimizasyon ekledi ve performansta 2,1 kat artış sağladı.
Artık nasıl yanıt vermek istediğini değerlendirmek Nvidia’ya kalmış. Ancak bunun aynı zamanda endüstrinin FP8’i kullanmak için TensorRT-LLM’nin kapalı sistemi olan FP16’yı, yani vLLM’yi tamamen ortadan kaldırmasını gerektireceğini de kabul etmesi gerekiyor. Nvidia’nın premiumundan bahsederken, Reddit kullanıcısı bir keresinde şöyle demişti:“TensorRT-LLM, tıpkı Rolls Royce ile ücretsiz gelen şeyler gibi ücretsizdir.”