
Sanki hareketsiz görüntü deepfake’leri yeterince kötü değilmiş gibi, yakında kendi fotoğraflarını internete koymaya cesaret eden herkesin oluşturduğu videolarla uğraşmak zorunda kalabiliriz: Herkesi CanlandırınKötü aktörler insanları her zamankinden daha iyi kukla oynayabilir.
Yeni üretken video tekniği, Alibaba Group’un Akıllı Hesaplama Enstitüsü’ndeki araştırmacılar tarafından geliştirildi. Bu, yaz aylarında etkileyici olan ancak artık tarih olan DisCo ve DreamPose gibi önceki görüntüden videoya sistemlerden ileriye doğru büyük bir adımdır.
Animate Any’nin yapabilecekleri hiçbir şekilde eşi benzeri görülmemiş bir şey değildir, ancak “gereksiz akademik deney” ile “yakından bakmazsanız yeterince iyi” arasındaki o zor boşluğu aşmıştır. Hepimizin bildiği gibi, bir sonraki aşama, insanların gerçek olduğunu varsaydıkları için yakından bakma zahmetine bile girmeyecekleri, “yeterince iyi” bir aşamadır. Şu anda hareketsiz görüntülerin ve metin konuşmalarının bulunduğu yer burasıdır ve gerçeklik duygumuzu mahveder.
Bunun gibi görüntüden videoya modeller, satılık elbise giyen bir modelin moda fotoğrafı gibi bir referans görüntüden yüz özelliği, desenler ve poz gibi ayrıntıların çıkarılmasıyla başlar. Daha sonra bu ayrıntıların çok az farklı pozlarla eşleştirildiği, hareketle yakalanabilen veya başka bir videodan çıkarılabilen bir dizi görüntü oluşturulur.
Önceki modeller bunun mümkün olduğunu gösteriyordu ancak pek çok sorun vardı. Halüsinasyon büyük bir sorundu çünkü model, kişi döndüğünde kolun veya saçın nasıl hareket edebileceği gibi makul ayrıntılar icat etmek zorundaydı. Bu, pek çok tuhaf görüntüye yol açarak ortaya çıkan videoyu ikna edici olmaktan uzak hale getiriyor. Ancak bu olasılık devam etti ve Animate Any, mükemmel olmaktan çok uzak olmasına rağmen çok daha geliştirildi.
Yeni modelin teknik özellikleri çoğu kişinin ötesinde ancak kağıt “Modelin, tutarlı bir özellik alanında referans görüntüyle ilişkiyi kapsamlı bir şekilde öğrenmesini sağlayan ve görünüm ayrıntılarının korunmasının iyileştirilmesine önemli ölçüde katkıda bulunan” yeni bir ara adımı vurguluyor. Temel ve ince ayrıntıların daha iyi korunması sayesinde oluşturulan görüntüler, üzerinde çalışılacak daha güçlü bir temel gerçeğe sahip olur ve çok daha iyi sonuçlar verir.
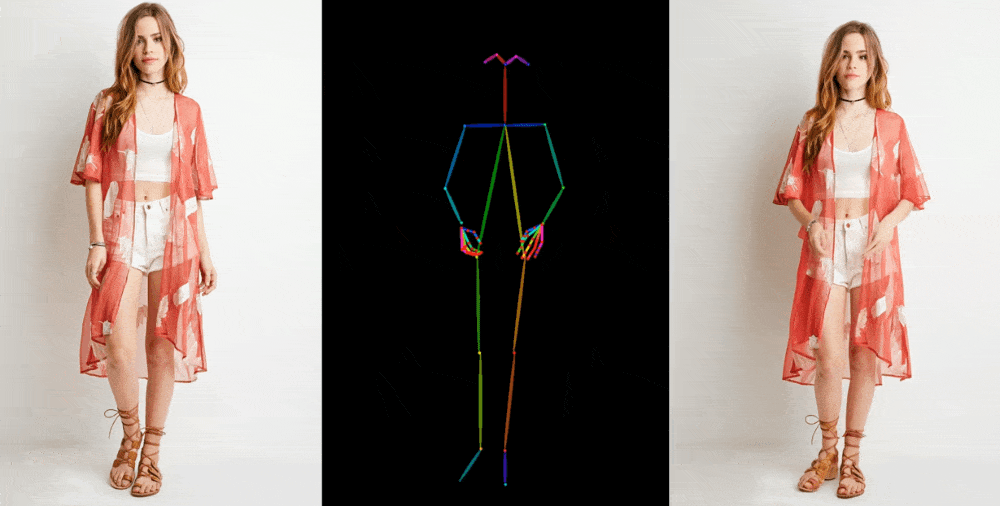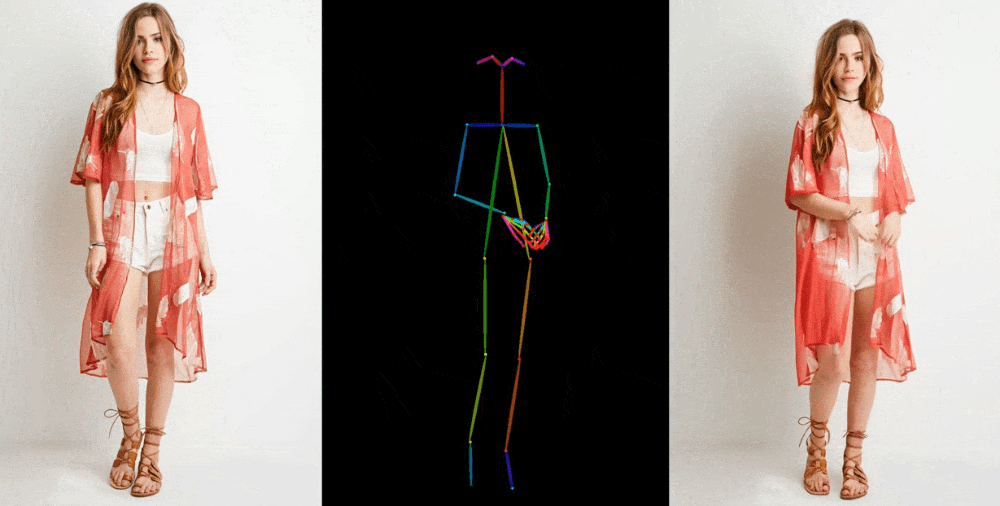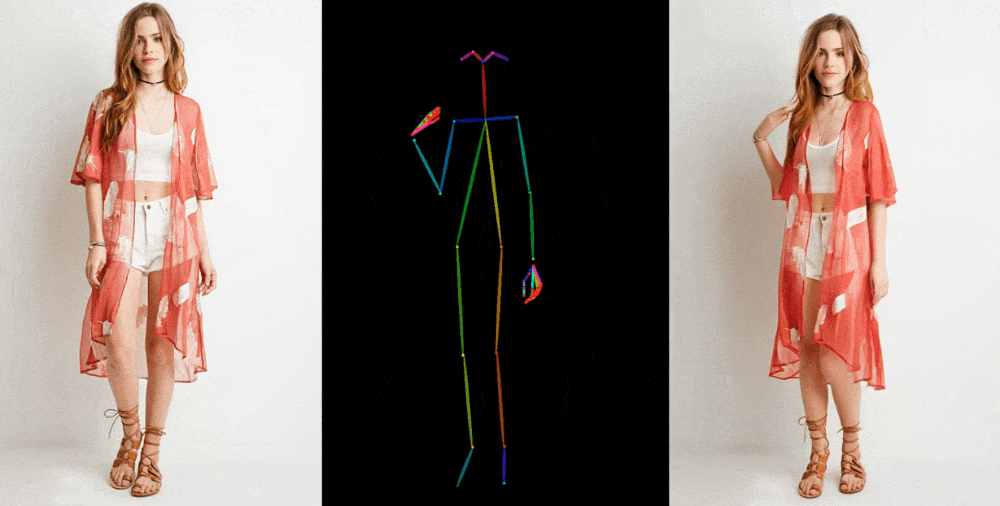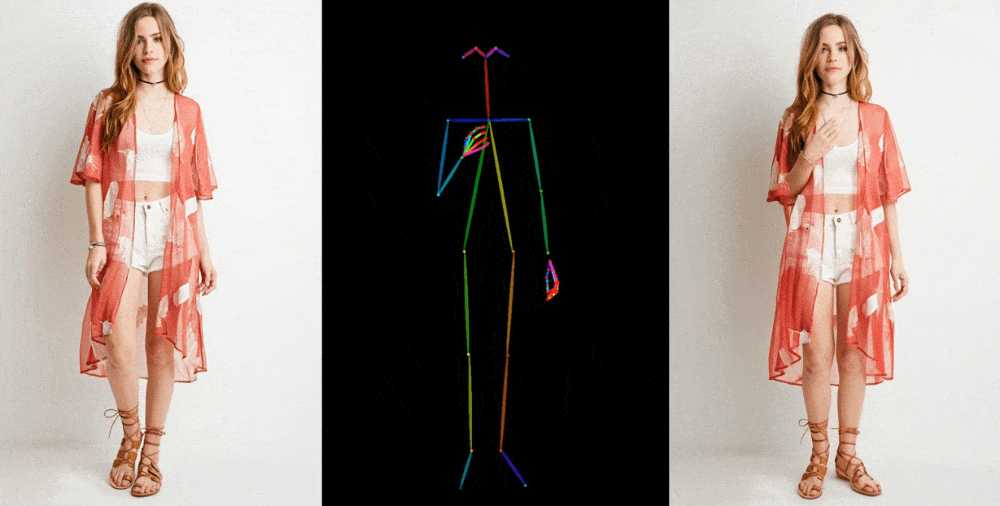
Resim Kredisi: Alibaba Grubu
Sonuçlarını birkaç bağlamda sergiliyorlar. Mankenler, kıyafetleri deforme etmeden, desenini kaybetmeden keyfi pozlar veriyor. Bir 2D anime figürü canlanıyor ve ikna edici bir şekilde dans ediyor. Lionel Messi birkaç genel hareket yapıyor.
Mükemmel olmaktan çok uzaklar; özellikle üretken modeller için özellikle sorun yaratan gözler ve eller konusunda. Ve en iyi temsil edilen pozlar aslına en yakın olanlardır; Örneğin kişi arkasını dönerse model ona ayak uydurmakta zorlanır. Ancak bu, çok daha fazla eser üreten veya bir kişinin saçının rengi veya kıyafeti gibi önemli detayların tamamen kaybolduğu önceki teknolojiye göre büyük bir sıçrama.
Kötü niyetli bir aktörün (ya da yapımcının) tek bir kaliteli görüntünüzle size hemen hemen her şeyi yaptırabileceğini ve yüz animasyonu ve ses yakalama teknolojisiyle birleştirildiğinde aynı zamanda her şeyi ifade etmenizi sağlayabileceğini düşünmek sinir bozucu. . Şimdilik teknoloji genel kullanım için fazla karmaşık ve hatalı, ancak yapay zeka dünyasında işler uzun süre bu şekilde kalma eğiliminde değil.
En azından ekip henüz kodu dünyaya salmıyor. Her ne kadar onların bir GitHub sayfasıgeliştiriciler şöyle yazıyor: “Demoyu ve kodu halka açık yayına hazırlamak için aktif olarak çalışıyoruz. Şu anda belirli bir yayın tarihi veremesek de, lütfen hem demoya hem de kaynak kodumuza erişim sağlama niyetimizin kesin olduğundan emin olun.”
İnternet aniden dans sahtekarlıklarıyla dolduğunda kıyamet kopacak mı? Öğreneceğiz ve muhtemelen istediğimizden daha erken.