

Tiernan Ray ve Stability.ai’nin Dream Studio’su
İşte, kariyerinizdeki bir sonraki adımı hayal ediyorsunuz: Yapay zeka tarafından sürüklenmekten kaçınmak için yönlendirmede usta olmak. OpenAI’nin ChatGPT’si gibi üretken bir yapay zeka programının size itaat etmesini sağlayacak en iyi cümleyi yazma sanatında şampiyon olun.
O kadar hızlı değil: İstem sanatının kendisi, büyük dil modelleri (LLM) kullanılarak otomasyonla desteklenebilir.
Geçtiğimiz hafta Google’ın DeepMind birimi tarafından yayınlanan bir makalede, araştırmacılar Chengrun Yang ve ekibi, LLM’lerin bir görevi çözmeye en yakın olanı bulana kadar farklı istemleri denemelerine olanak tanıyan OPRO adında bir program oluşturdular. Bu, bir kişinin yazarken yapacağı deneme yanılma işlemini otomatikleştirmenin bir yoludur.
Ulaşılacak ideali doğal dilde ifade etmek için Yüksek Lisans Programlarını kullanma
“Optimize Edici Olarak Büyük Dil Modelleri” başlıklı araştırma makalesi sunucuda yayınlandı ön baskı arXivbir dil modeli kullanılarak nasıl “optimize edileceğine”, yani programın ideal duruma yaklaşmaya dayalı olarak giderek daha kesin yanıtlar üretmesini sağlamaya ilişkin bir deneyi ayrıntılı olarak açıklamaktadır.
Yang ve ekibi, bu ideal durumu açıkça programlamak yerine, ulaşılacak ideali doğal dilde ifade etmek için Yüksek Lisans’ları kullanmaya karar verdi. Bu, AI programının farklı görevler için sürekli değişen optimizasyon taleplerine uyum sağlamasına olanak tanır.
Yang ve ortak yazarlarının yazdığı gibi, büyük dil modellerinin dilsel işleme esnekliği “optimizasyon için yeni bir fırsat sunuyor: optimizasyon problemini resmi olarak tanımlamak ve güncelleme adımını programlanmış bir çözücüyle türetmek yerine, optimizasyon problemini doğal dilde tanımlıyoruz, sonra Yüksek Lisans’tan problem tanımına ve önceden bulunan çözümlere dayalı olarak yinelemeli olarak yeni çözümler üretmesini isteyin.
Meta-Prompt’un gücü
OPRO programının kalbinde “Meta-Prompt” adı verilen bir algoritma bulunmaktadır. Meta-Prompt önceki istemleri gözden geçirir ve bunların belirli bir sorunu çözmedeki etkinliğini değerlendirir. Daha sonra en iyisini bulmaya çalışabileceği birkaç bilgi istemi oluşturur.
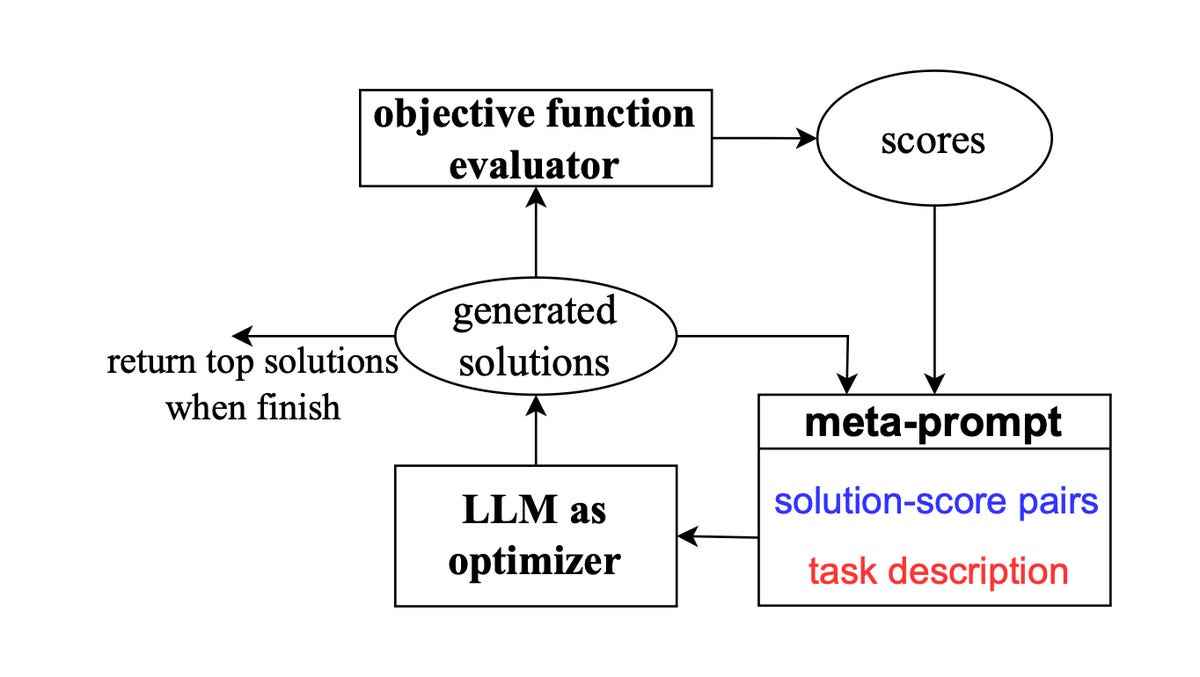
DeepMind meta isteminin yapısı. Derin Düşünce
Aslında Meta-Prompt, klavye başında oturan ve daha önce işe yarayıp yaramadığını gördüklerine dayanarak birçok yeni olasılığı yazan bir kişiye benzer. Meta-Prompt, istemler ve yanıtlar üretmek için herhangi bir ana dil modeline bağlanabilir. Yazarlar, GPT-3 ve GPT-4’ün yanı sıra Google’ın PaLM 2 dil modeli de dahil olmak üzere çok sayıda farklı dil modelini test ediyor.
Yazarlar OPRO’yu temel problemler üzerinde test ederek başlıyorlar. Bunlardan biri, programdan “bir fonksiyonu en aza indirmesinin”, yani daha önceki örneklere benzer ancak sonuç gibi daha küçük bir sayısal değer üreten bir sayı çifti bulması istendiği doğrusal regresyondur.
Yüksek Lisans için iyi bir bilgi istemi yazmak, optimize edilecek bir görev olarak düşünülebilir
Bu nedenle dil modeli bir matematik problemine çözüm bulma yeteneğine sahiptir. Bu, bu sorunun çözülmesinin normalde yalnızca bu sorun için tasarlanmış bir program tarafından (kendi deyimiyle “çözücü” olarak anılır) çözülmesi gerçeğine rağmen böyledir. Yazarların yazdığı gibi, “LLM’ler, meta-istemde sağlanan geçmiş optimizasyon yörüngesine dayanarak küçük ölçekli problemlerdeki optimizasyon yönlerini doğru bir şekilde yakalar.”
Ve büyük bir dil modeli için iyi bir bilgi istemi yazma sanatının kendisinin de optimize edilmesi gereken bir görev olarak görülebileceği ortaya çıktı.
Araştırmacılar bunu bir süredir biliyorlar. Microsoft bilim adamları önerdi Yılın başında “otomatik istem optimizasyonu” dedikleri şey. Bu yaklaşım, istemin yazımını iyileştirmek için otomatik olarak değiştirir. Yang ve ekibi daha da ileri gitti. Meta-Prompt, önceki bir istemi iyileştirmek için değiştirmek yerine tamamen yeni istemler oluşturur.
GSM8K ve BIG-bench ile karşılaştırma
Açıkladıkları gibi, “çalışmamızdaki her optimizasyon adımı, doğal dil geri bildirimi işlevinde bir giriş istemini değiştirmek veya yeni istemin aşağıdaki komutu takip etmesini gerektirmek yerine, daha önce oluşturulan istemlerin yörüngesine dayalı olarak test doğruluğunu artırmayı amaçlayan yeni istemler üretir. aynı anlamsal anlam.
Araştırmacılar Meta-Prompt’un istemleri ne kadar iyi optimize edebildiğini test etti.
Meta-Prompt’ı, istemi optimize etmenin performansı artırdığını gösteren kıyaslamalarda test ettiler.
Bunlardan biri “GSM8K” 2021’de OpenAI tarafından tanıtıldı“Nina haftada 4 düzine kurabiye pişiriyor. Bu kurabiyeler 16 kişi arasında eşit olarak paylaştırılırsa her kişi kaç kurabiye yer?” gibi ilkokul düzeyindeki bir dizi matematik problemi.
İkinci bir test, muhakeme testi olan BIG-bench’in bir türevidir. geçen yıl tanıtıldı diğerleri arasında Google tarafından. Google yazarlarının BIG-bench Hard adlı yeni sürümü, bu yıl tanıtıldıgeçmişte büyük dil modellerinin insan düzeyinde doğruluk sağlamada başarısız olduğu akıl yürütme sorunlarına odaklanır.
Sihirli cümle: “Adım adım düşünelim”
Google yazarlarının orijinal makalede yazdığı gibi BIG-bench problemleri “çeşitlidir” ve “dilbilim, matematik, sağduyulu akıl yürütme, biyoloji, fizik, sosyal önyargı, yazılım geliştirme ve diğer alanlardan problemler çıkarır.
Yazarlar, her iki görev için otomatik olarak oluşturulan istemleri, şekilde gösterildiği gibi “elle” geliştirilen istemlerle karşılaştırırlar. 2022’nin çalışması Takeshi Kojima ve Tokyo Üniversitesi’ndeki ekibi ve Google Araştırma tarafından.
Kojima ve ekibi, istemin başına basitçe “Adım adım düşünelim” ifadesini ve ardından örnek bir yanıtı ekleyerek, GSM8K ve BIG-bench gibi görevlerde büyük dil modellerinin yeteneğini geliştirebileceklerini keşfettiler. Bu cümlenin dil modeli açısından “zincirleme düşünme” adımlarını tetiklemek için yeterli olduğunu buldular.
Yang ve ekibi, Meta-Prompt ile, “Adım adım düşünelim”e benzer, ancak kendi dillerinde daha iyi veya daha optimal ifadeler içeren istemleri otomatik olarak oluşturabileceklerini keşfetti.

Dil modelinin daha optimal mesajlar sunmasını sağlamak için kullanılan “meta istem” örneği. Turuncu metin metaprompt’tır, yani dil modeline bir istemin nasıl oluşturulacağını söyleyen talimatlardır. Mavi metin bazı örnekleri göstermektedir. Mor metin, optimizasyon görevini ve çıktı formatını açıklar. Derin Düşünce
İstemleri optimize eden algoritmayı optimize edin
Bazen otomatik olarak oluşturulan istemler çok karmaşık hale gelebilir. Örneğin, “temporal_sequence” adı verilen BIG-bench akıl yürütme görevinde, bir senaryonun bazı öğeleriyle birlikte bir dil modeli sağlanır ve daha sonra bir şeyin gerçekleştiği zamana yanıt vermesi istenir. Örneğin:
Bugün Richard yüzme havuzuna gitti. Oraya saat kaçta gitmiş olabilir?
Bunu biliyoruz: Richard saat 7’de uyandı. Samantha, Richard’ı sabah 7’den akşam 8’e kadar bahçede yürürken gördü.
Marc, Richard’ın sabah 8’den akşam 9’a kadar spor salonunda çalıştığını gördü.
David, Richard’ın sabah 9’dan akşam 10’a kadar okula gittiğini gördü.
Andrew, Richard’ın sabah 10’dan akşam 4’e kadar istasyonda beklediğini gördü.
Yüzme havuzu saat 17.00’den sonra kapatılmaktadır.
Richard hangi saatler arasında yüzme havuzuna gitmiş olabilir?
Yang ve ekibi, aşağıdaki gibi çok karmaşık soruları derlediği için Meta-isteminin daha iyi performans gösterdiğini buldu:
“Bir kişinin bir mekanda bulunduğu süreyi belirlemek için öncelikle kişinin başka bir şey yaparken görülmediği ve mekanın açık olduğu tüm dönemleri belirleyin. Daha sonra kişinin başka bir şey yaparken görüldüğü dönemleri eleyin. Geriye kalanlar dönemler, kişinin o yerde bulunabileceği olası dönemlerdir.”
Genel olarak, “optimize edilmiş istemlerimizin GSM8K ve Big-Bench Hard testlerinde insan tasarımı istemlerden önemli ölçüde, bazen %50’den fazla daha iyi performans gösterdiğini” buldular.
Ancak istemleri optimize eden algoritmayı optimize etmek için hala yapılması gereken işler var.
Meta-Prompt olumsuz örneklerden sonuç çıkaramıyor
Özellikle, OPRO’nun Meta-İstemi örneklerden çıkarımda bulunamaz olumsuz. “Her optimizasyon adımında eğitim setini rastgele örneklemek yerine Meta-Prompt’a hata vakalarını dahil etmeye çalıştık” diyorlar, “ancak sonuçlar benzer, bu da vaka hatalarının tek başına LLM optimize edicinin anlaması için yeterince bilgilendirici olmadığını gösteriyor” hatalı tahminin nedeni.
Belki de bir sonraki programlama işiniz Meta-Prompt’u daha iyi istemler oluşturması için kandırmanın en iyi yolunu bulmak olacaktır.
Kaynak : “ZDNet.com”