
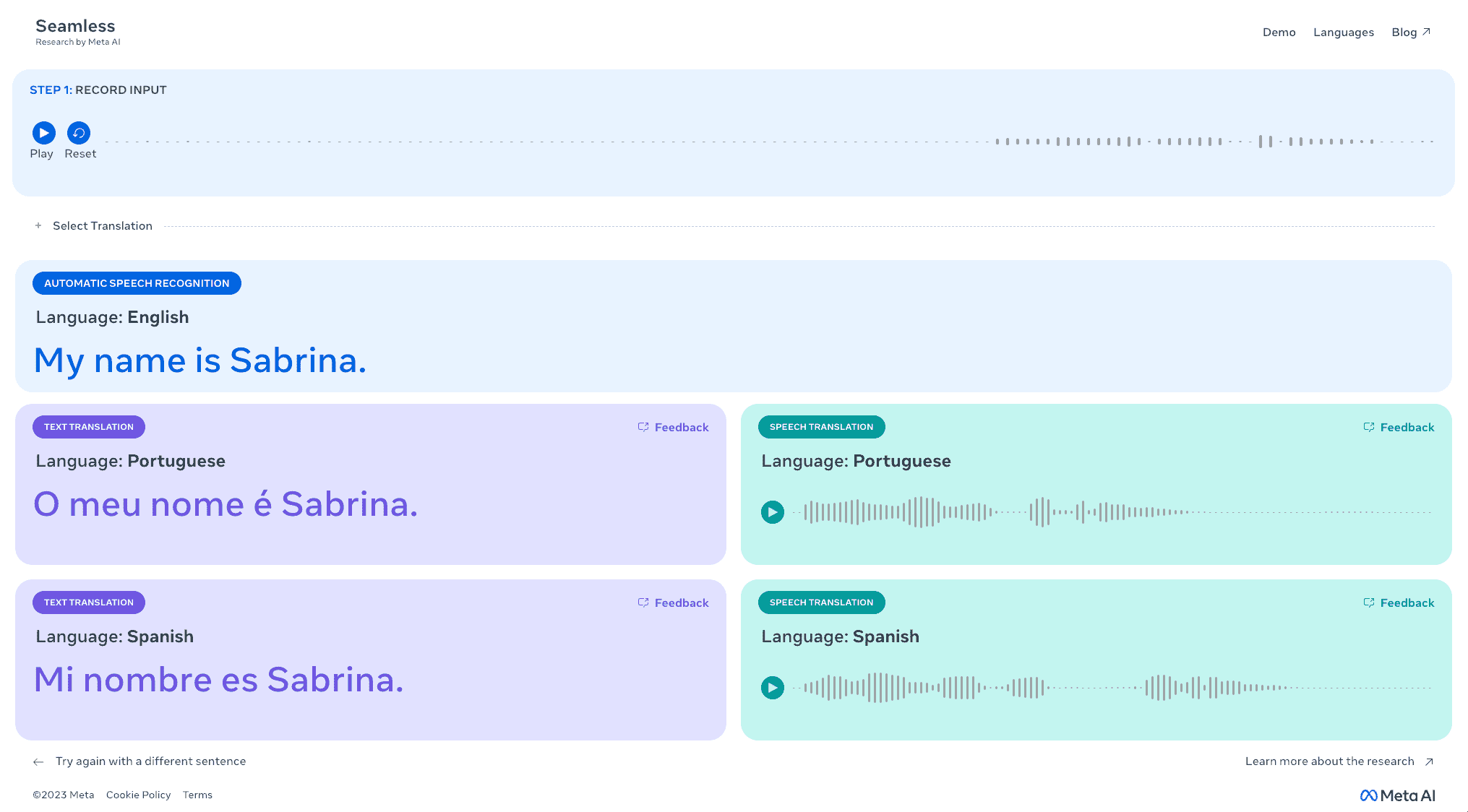
Sesimi kaydettikten birkaç saniye sonra model, sesli çeviriyle birlikte metin çevirisini de üretti. Ekran görüntüsü: Sabrina Ortiz/ZDNET
Google Çeviri’ye elveda. Bis später. Hasta Luego.
Başka bir dil öğrenmek zordur. Meta’nın yeni yapay zeka çeviri modeli sizin için işin zor kısmını yapmak üzere burada; hatta bir demoyu deneyebilirsiniz.
Salı, Meta açıklandı SeamlessM4T, yaklaşık 100 dili destekleyen ilk hepsi bir arada çok modlu ve çok dilli çeviri yapay zeka modeli. Model, konuşmayı metne, konuşmayı konuşmaya, metinden konuşmaya ve metinden metne çevirileri gerçekleştirebilir. Meta, SeamlessM4T’nin tek sistem yaklaşımının hataları ve gecikmeleri azaltarak çeviri verimliliğini ve kalitesini artırdığını iddia ediyor.
İfadenin çevrilmesini istediğiniz en fazla üç dili seçin
Modeli denemek için açmanız yeterli bu demo bağlantısı tarayıcınıza girin ve çevrilmesini istediğiniz cümlenin tamamını kaydedin. En iyi sonuçlar için Meta, sessiz bir ortamda denemenizi önerir.
Daha sonra ifadenin çevrilmesini istediğiniz en fazla üç dili seçebilirsiniz. İfadenizi girdikten sonra, bir transkript görüntüleyebilir ve çevirileri dinleyebilirsiniz.
Demoyu denedim ve sonuçların doğruluğundan ve hızından etkilendim. Cümlemi kaydettikten birkaç saniye sonra model, yukarıdaki fotoğrafta görüldüğü gibi sesli çevirinin yanı sıra bir metin çevirisi de üretti.
Büyük dilsel modellere karşı
Bu bir gösteri olduğu için Meta, hatalı çeviriler üretebileceği veya girilen kelimelerin anlamlarını değiştirebileceği konusunda uyarıyor. Kullanıcılar bu yanlışlıklarla karşılaşırsa Meta, modelin iyileştirilebilmesi için onları hataları bildirmek üzere geri bildirim özelliğini kullanmaya teşvik eder.
Meta, SeamlessM4T’nin, diller arasında konuşmadan konuşmaya çeviri için özel olarak eğitilmiş mevcut çeviri modellerinden ve ayrıca birden fazla dil çiftinde konuşmayı ve metni dönüştüren modellerden daha iyi performans gösterdiğini iddia ediyor. SeamlessM4T olarak bilinen şeyin bir örneğidir. çok modlulukyani bir programın çeşitli veri türleri (bu durumda ses ve metin verileri) üzerinde çalışma yeteneği.
Daha önce Meta, metni 200 farklı dil arasında çevirebilen büyük dil modellerine odaklanmıştı. Metne bu şekilde odaklanmak, Meta’dan Loïc Barrault’a göre bir sorun teşkil ediyor.
Konuşma çevirisiyle uğraşmak
No Language Left Behind (NLLB) gibi tek modlu modeller metinden metne (T2TT) çeviri kapsamını 200’den fazla dile getirirken, birleşik S2ST (konuşmadan konuşmaya-metne) modeller benzer aralık veya performans” diye yazdı.
“SeamlessM4T – Çok Dilli ve Çok Modlu Makine Çevirisi” adlı resmi belge yayınlandı Meta projesine adanmış sitede, Kesintisiz İletişim. Ayrıca bir tane var ilgili GitHub sitesi.
Yazarlar, o dönemde konuşmanın dışarıda bırakıldığını, çünkü sinir ağlarını eğitmek için kamuya açık alanda daha az konuşma verisi bulunduğunu yazıyor. Ancak hepsinden önemlisi, ses verilerinin sinir ağları için sinyal olarak işlenmesi daha zengin olduğu için.
“Makine çevirisi açısından konuşmayı işlemek daha zordur”
“Makine çevirisi açısından konuşmayı işlemek daha zordur. Daha fazla bilgi kodlar. Bu aynı zamanda niyeti aktarmada ve konuşmacılar arasında daha güçlü sosyal bağlar kurmada üstün olmasının nedenidir.”, diye yazıyor Barrault.
SeamlessM4T’nin amacı hem ses verileri hem de metin verileri üzerinde eğitilmiş bir program oluşturmaktır.
Çok modluluğun programın açık bir unsuru olduğu da unutulmamalıdır.
Böyle bir programa bazen “uçtan uca” program denir, çünkü programın ilk kez eğitildiği “etkin modellerde” olduğu gibi metin bölümlerini ve konuşma bölümlerini ayrı işlevlere bölmez. konuşmayı metne dönüştürme gibi bir öğe üzerinde ve ardından konuşmadan konuşmaya dönüştürme gibi başka bir öğe üzerinde.
Programın yazarlarının belirttiği gibi, “Günümüzde çoğu S2ST sistemi, çeviriyi aşamalı olarak gerçekleştiren çeşitli alt sistemlerden oluşan basamaklı sistemlere dayanmaktadır – örneğin, otomatik konuşma tanımadan (ASR) T2TT’ye ve ardından metinden konuşmaya kadar. Üç aşamalı bir sistemde (TTS) sentezi”.
Birlikte eğitilmiş mevcut birkaç parçayı birleştiren bir program
Bunun yerine yazarlar, birlikte eğitilmiş mevcut birkaç parçayı birleştiren bir program geliştirdiler. Bunlar arasında “SeamlessM4T-NLLB, çok dilli bir T2TT modeli”nin yanı sıra “etiketlenmemiş konuşma ses verilerinden yararlanan bir konuşma temsili eğitim modeli” olan w2v-BERT 2.0 adlı bir program ve ayrıca “metinden üniteye bir dizi olan T2U” yer alıyordu. dizi modeli” ve Çok Dilli HiFi-GAN, “birimlerden konuşmayı sentezlemek için birim ses kodlayıcı”.
Dört bileşen tek bir programda bir Lego seti gibi bir araya getiriliyor. bu yıl da Meta tarafından tanıtıldıUnitY adı verilen ve “önce metni üreten, ardından ayrı akustik birimleri tahmin eden iki adımlı bir modelleme çerçevesi” olarak tanımlanabilecek.
Organizasyonun tamamı aşağıdaki şemada görülebilir.
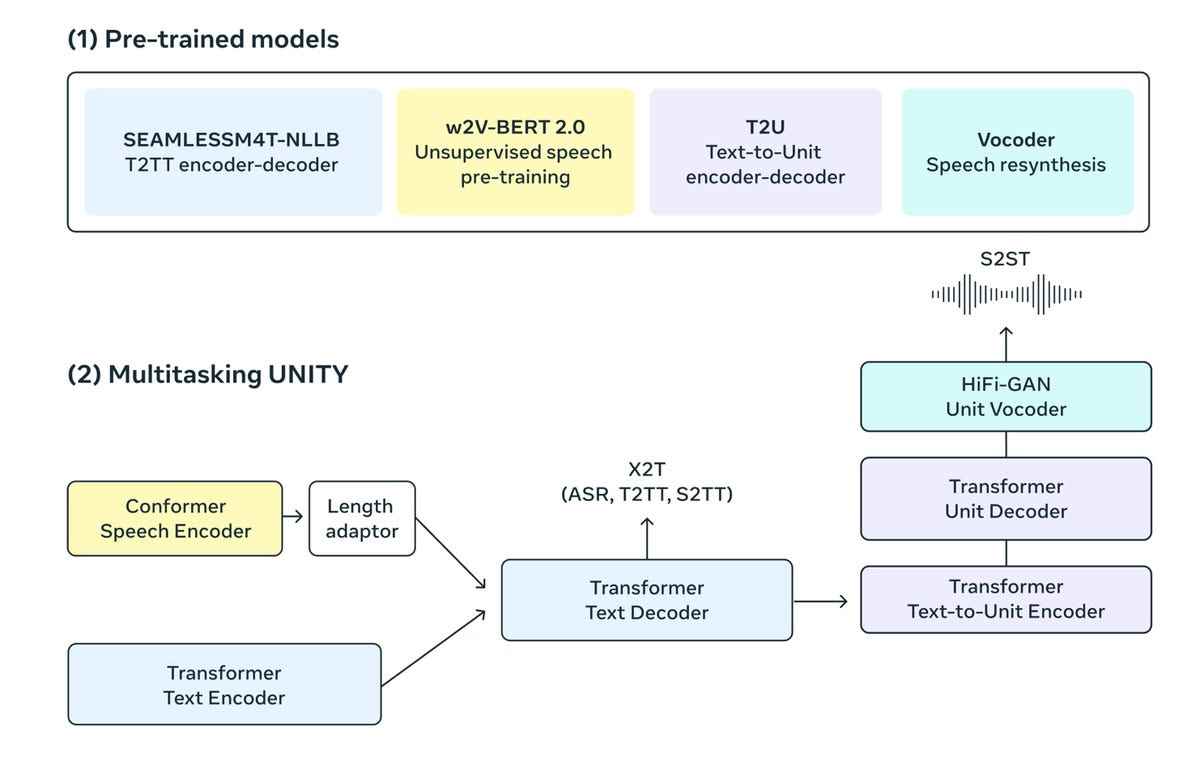
Yazarlar, hepsi bir Lego seti gibi tek bir programda birbirine bağlanan mevcut birkaç parçayı bir araya getiren bir program geliştirdiler. Arama Meta AI 2023
Yazarlar, programın konuşma tanıma, konuşma çevirisi ve konuşmadan metne dönüştürmeyi test ederken diğer birçok program türünden daha iyi performans gösterdiğini belirtiyor. Özellikle yendi değişiklik programları bunlar aynı zamanda uçtan uca ve açıkça konuşma tanıma için tasarlanmış programlardır.
Ekteki GitHub sitesi yalnızca programın kodunu değil, aynı zamanda çok modlu verileri “entegre etmek” için yeni bir teknoloji olan SONAR’ı ve çok modlu görevleri otomatik olarak değerlendirmek için bir metriğin yeni bir sürümü olan BLASAR 2.0’ı da sunuyor.
Kaynaklar: “ZDNet.com” Ve “ZDNet.com”