
GPT-4 ve Claude gibi dil modelleri güçlü ve faydalıdır, ancak eğitildikleri veriler yakından korunan bir sırdır. Allen Yapay Zeka Enstitüsü (AI2), kullanımı ücretsiz ve incelemeye açık yeni, devasa bir metin veri kümesiyle bu eğilimi tersine çevirmeyi hedefliyor.
Veri kümesi olarak adlandırılan Dolma, araştırma grubunun planlanan açık dil modeli veya OLMo (Dolma, “OLMo’nun İştahını Besleyecek Verilerin kısaltmasıdır) için temel oluşturmayı amaçlamaktadır. Modelin yapay zeka araştırma topluluğu tarafından ücretsiz olarak kullanılması ve değiştirilmesi amaçlandığından, (AI2 araştırmacılarını tartışıyorlar) modeli oluşturmak için kullandıkları veri kümesi de öyle olmalıdır.
Bu, AI2’nin OLMo ile ilgili kullanıma sunduğu ilk “veri eseri”dir ve bir blog yazısındaKuruluştan Luca Soldaini, ekibin yapay zeka tüketimi için uygun hale getirmek için kullandığı çeşitli süreçlerin arkasındaki kaynakları ve mantığı açıklıyor. (“Daha kapsamlı bir makale üzerinde çalışılıyor,” diye belirtiyorlar başlangıçta.)
OpenAI ve Meta gibi şirketler, dil modellerini oluşturmak için kullandıkları veri setlerinin bazı hayati istatistiklerini yayınlasa da, bu bilgilerin çoğu özel mülkiyet olarak kabul edilir. İncelemeyi ve genel olarak iyileştirmeyi caydırmanın bilinen sonucunun yanı sıra, bu kapalı yaklaşımın verilerin etik veya yasal olarak elde edilmemesinden kaynaklandığına dair spekülasyonlar var: örneğin, birçok yazarın kitabının korsan kopyalarının alınması.
AI2 tarafından oluşturulan bu grafikte, en büyük ve en yeni modellerin yalnızca bir araştırmacının belirli bir veri kümesi hakkında bilmek isteyebileceği bilgilerin bir kısmını sağladığını görebilirsiniz. Hangi bilgiler kaldırıldı ve neden? Yüksek ve düşük kaliteli metin olarak kabul edilen nedir? Kişisel detaylar uygun şekilde eksize edildi mi?
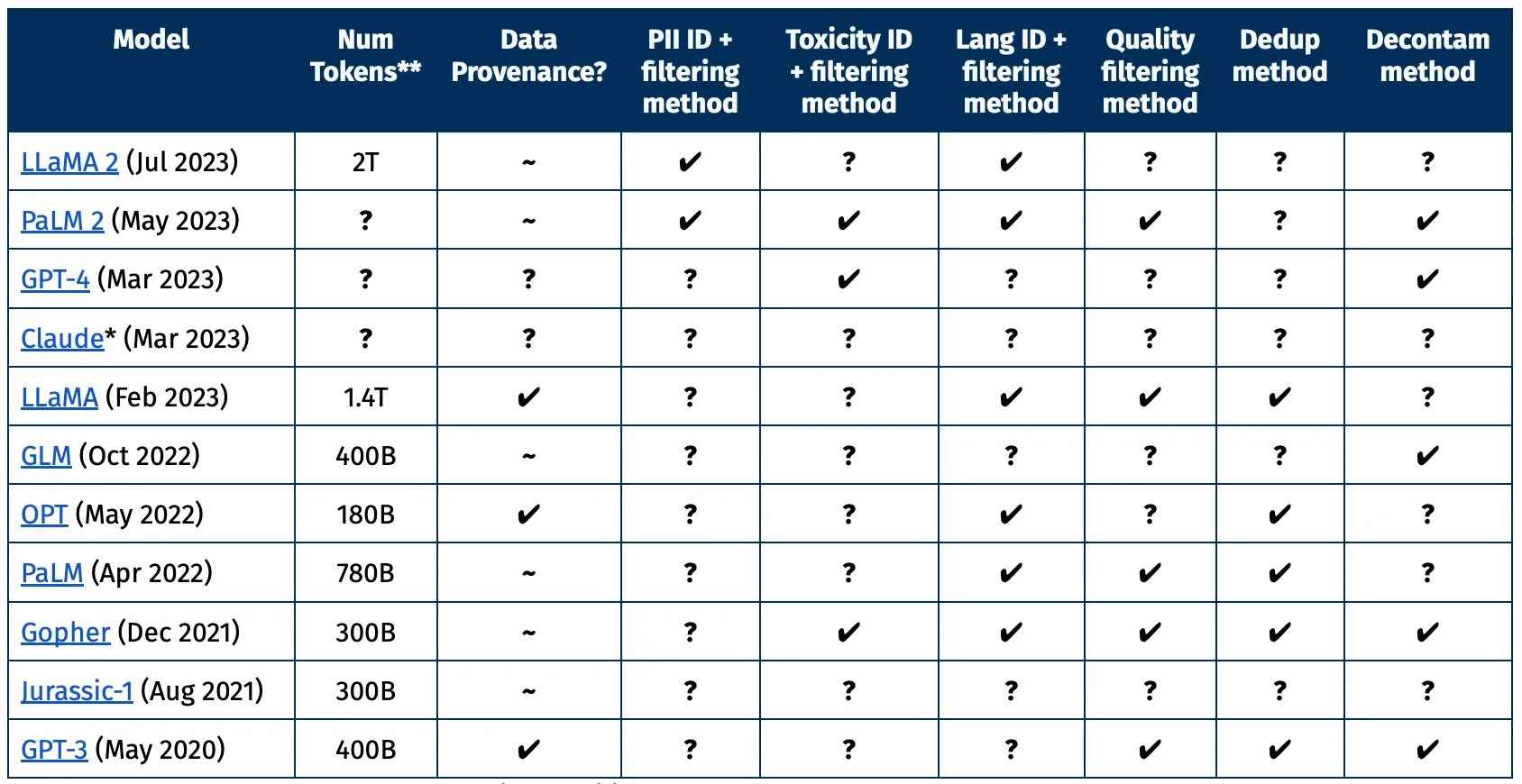
Farklı veri setlerinin açıklığını veya eksikliğini gösteren grafik.
Elbette, son derece rekabetçi bir AI manzarası bağlamında, modellerinin eğitim süreçlerinin sırlarını korumak bu şirketlerin ayrıcalığıdır. Ancak şirketlerin dışındaki araştırmacılar için, bu veri kümelerini ve modelleri daha opak hale getirir ve üzerinde çalışılması veya çoğaltılması zorlaşır.
AI2’nin Dolma’sının, tüm kaynakları ve süreçleriyle – örneğin, nasıl ve neden orijinal İngilizce metinlere göre kırpıldığı – kamuya açık bir şekilde belgelenmesiyle bunların tam tersi olması amaçlanmıştır.
Açık veri kümesi olayını ilk deneyen değil, ancak açık ara en büyüğü (3 milyar belirteç, yapay zekaya özgü bir içerik hacmi ölçüsü) ve kullanım ve izinler açısından en basit olduğunu iddia ediyorlar. “Orta riskli eserler için ImpACT lisansını” kullanır. burada ayrıntıları görebileceğiniz. Ancak esas olarak Dolma’nın olası kullanıcılarının şunları yapmasını gerektirir:
- İletişim bilgilerini ve amaçlanan kullanım durumlarını sağlayın
- Herhangi bir Dolma türevi kreasyonu ifşa edin
- Bu türevleri aynı lisans altında dağıtın
- Dolma’yı gözetleme veya dezenformasyon gibi çeşitli yasaklanmış alanlara uygulamamayı kabul edin
AI2’nin tüm çabalarına rağmen bazı kişisel verilerinin veritabanına girmiş olabileceğinden endişe edenler için burada bir kaldırma talep formu bulunmaktadır. Belirli durumlar içindir, sadece genel bir “beni kullanma” olayı değil.
Bunların hepsi sana iyi geliyorsa, Dolma’ya erişim Hugging Face aracılığıyla sağlanır.