
AMD’nin AI veri merkezi hızlandırıcısı MI300X’i resmi olarak duyurmasının hemen ardındanyız. Bu, kesinlikle hesaba katılması gereken bir işlem gücüdür – AMD’nin, Nvidia’yı AI hızlandırma dünyasında baskın oyuncu olarak tüneğinden çıkarmaya çalışmak için bir sopa olarak kullanmayı amaçladığı bir güç. Ancak, her yeni mimarinin genellikle güç verimliliğini iyileştirmesine (aynı iş birimi için lee enerji tüketmesine) rağmen, artan performans bazen daha yüksek güç çekimlerine dönüşebilir. Ve AMD’nin OAM tabanlı (OCP Hızlandırıcı Modülü) – MI300X – kesinlikle güç tüketiyor: 750 W ile aslında form faktöründe şimdiye kadarki en yüksek TDP derecesine sahip ürün. Yine de endişelenmeyin: OAM çözümlerinin teknik özellikleri teslim edilebilir gücün 1000 W’ına kadar çıkıyor, bu nedenle performansı daha da ölçeklendirmek için hala yer var.
750 W, herhangi bir kişisel bilgisayar donanımı tarafından (en azından bir bireyin bakış açısından) tüketilmesi gereken çok büyük bir güç olsa da, bu wattların donanıma güç verdiğini unutmamalıyız. AMD’nin en güçlü grafik kartları bile. Bu güç için AMD, yapay zeka ile ilgili iş yükleri için (hem üretken yapay zeka hem de Büyük Dil Modeli’nde) en performanslı hızlandırıcı olduğunu iddia ettiği şeyi sunuyor. [LLM] işleme).
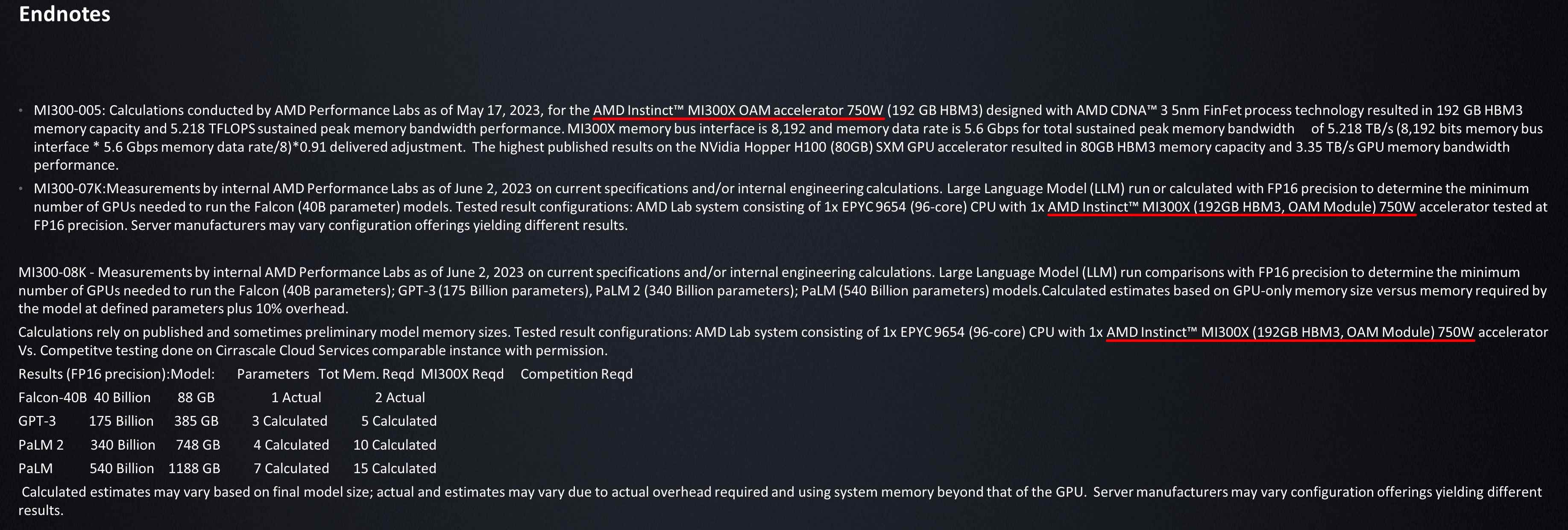
AMD’nin iki fabrikasyon sürecinde (8x 5nm) oluşturulmuş 12 yongayı nasıl sıkıştırmayı başardığını düşünürsek [GPU] ve 4x 6nm düğümleri [I/O die] toplam 153 milyar transistör için bu iddianın bazı destekleri olabilir. Elbette, AMD’nin tek bir MI300X üzerinde 40 milyar parametreli bir LLM modeli (Falcon 40-B) çalıştırmayı başardığı da var. Bu etkileyici, özellikle AMD’nin MI300X’in tek bir pakette sekiz adede kadar hızlandırıcıya ölçeklenmesini amaçladığı düşünülürse.
| Satır 0 – Hücre 0 | AMD MI300X | AMD MI300A | AMD MI250X | AMD RX 7900XTX |
| CPU çekirdekleri | 0 | 3x 8 çekirdekli CCD (24 çekirdekli) [Zen 4] | – | – |
| GPU çekirdekleri | 8x GCD (304 CU) [CDNA 3] | 6x GCD (228 CU) [CDNA 3] | (220 CU) [CDNA 2] | (RDNA 3) |
| Adreslenebilir Bellek | 192 GB (8x 24 GB HBM3) | 128 GB (8x 16 GB HBM3) | 128 GB (8x 16 GB HBM2e) | 24 GB GDDR5 |
| Bellek Bant Genişliği | 5,2 TB/sn | 5,2 TB/sn | ~ 3,28 TB/s | 384 GB/sn |
| Sonsuz Kumaş Bant Genişliği | 896 GB/sn | 896 GB/sn | 800 GB/sn | – |
| Transistör Sayısı | 153 Milyar | 146 Milyar | ~ 58.2 Milyar | ~ 57 Milyar |
| TDP | 750 W | ? | 560 W | 355 W |
Yukarıdaki tablodan da gördüğümüz gibi, AMD’nin artan güç verimliliğine odaklanması, artık sağa sola yayılan LLM modellerinin işlenmesini içeren Yüksek Performanslı Bilgi İşlem (HPC) senaryoları için artan bilgi işlem gereksinimlerini karşılamaya yetmedi. . Artan performans gereksinimleri, AMD’nin en son güç tasarrufu teknolojileri, teknikleri ve TSMC’nin en son fabrikasyon teknolojisine rağmen, 190 W’lık bir güç zarfı artışına ihtiyaç duyulduğu anlamına gelir.
Ancak bu 190 W TDP artışı (yaklaşık %33 daha fazla güç çekimi), MI250X’e kıyasla transistörlerin kabaca üç katına güç verilmesi anlamına geliyor – MI300X’in seyrek algoritmalar için geliştirilmiş desteği dikkate alınmasa bile (inanılmaz derecede önemli) verimlilik kazanımlarında etkileyici bir gösterge LLM ve AI işleme için). Bu, AMD’nin bilgi işlem hızlandırıcıları ile şirketin amiral gemisi oyun GPU’su, nispeten cılız RX 7900 XTX arasındaki fark hakkında hiçbir şey söylemez.