
Intel’in Habana Gaudi’si biraz rekabetçi bir performans sunsa ve Habana SynapseAI yazılım paketiyle birlikte gelse de, Nvidia’nın CUDA özellikli bilgi işlem GPU’larına kıyasla hala yetersiz kalıyor. Bu, sınırlı kullanılabilirlikle birleştiğinde, Gaudi’nin ChatGPT gibi büyük dil modelleri (LLM’ler) için o kadar popüler olmamasının nedeni budur.
Artık AI hücumu devam ettiğine göre, Intel’in Habana’sı daha geniş dağıtımlar görüyor. Amazon Web Services, LLM’leri eğitmek için Intel’in 1. Nesil Gaudi’sini PyTorch ve DeepSpeed ile denemeye karar verdi ve sonuçlar ticari olarak DL1 EC2 bulut sunucuları sunacak kadar umut vericiydi.
Milyarlarca parametre ile büyük dil modellerini (LLM’ler) eğitmek zorluklar sunar. Tek bir hızlandırıcının bellek sınırlamaları ve uyum içinde çalışan birden çok hızlandırıcının ölçeklenebilirliği göz önüne alındığında, özel eğitim tekniklerine ihtiyaçları vardır. AWS araştırmacıları, LLM eğitim zorluklarından bazılarını azaltmak ve model geliştirme ve eğitimi hızlandırmak için tasarlanmış PyTorch için açık kaynaklı bir derin öğrenme optimizasyon kitaplığı olan DeepSpeed’i ve çalışmaları için Intel Habana Gaudi tabanlı Amazon EC2 DL1 bulut sunucularını kullandı. Elde ettikleri sonuçlar çok ümit verici görünüyor.
Araştırmacılar, her biri sekiz Habana Gaudi hızlandırıcısı ve 32 GB belleğe sahip 16 dl1.24xlarge bulut sunucusundan ve her biri toplam 700 Gb/sn toplam çift yönlü ara bağlantı bant genişliğine sahip kartlar arasında tam ağ RoCE ağından oluşan AWS Batch kullanarak yönetilen bir bilgi işlem kümesi oluşturdu. Ayrıca küme, düğümler arasında toplam 400 Gb/sn ara bağlantıya sahip dört AWS Elastic Fabric Adapter ile donatıldı.
Yazılım tarafında, araştırmacılar BERT 1.5B modelini çeşitli parametrelerle önceden eğitmek için DeepSpeed ZeRO1 optimizasyonlarını kullandılar. Amaç, eğitim performansını ve maliyet etkinliğini optimize etmekti. Model yakınsamasını sağlamak için, hiperparametreler ayarlandı ve hızlandırıcı başına etkili parti boyutu, adım başına 16’lık mikro partiler ve 24 kademeli gradyan birikimi ile 384’e ayarlandı.
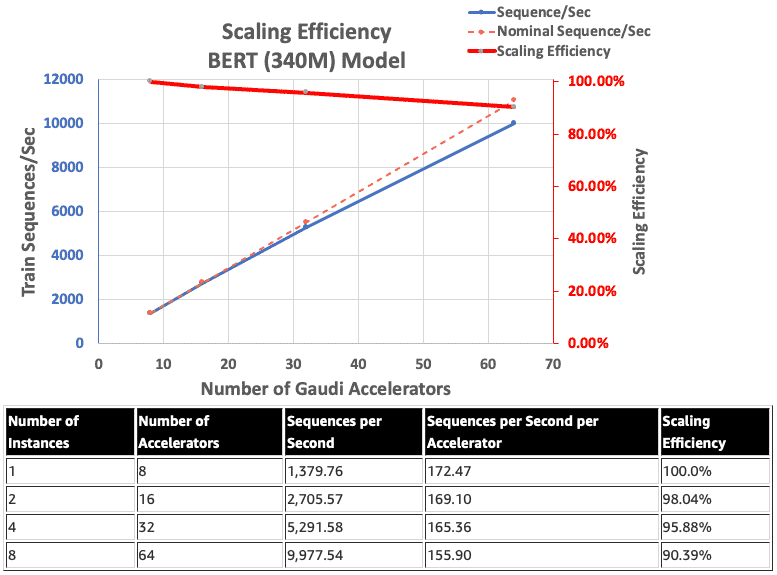
Intel HabanaGaudi’nin ölçekleme verimliliği nispeten yüksek olma eğilimindedir ve BERT 340 milyon modelini çalıştıran sekiz bulut sunucusu ve 64 hızlandırıcı ile asla %90’ın altına düşmez.
Bu arada, Gaudi’nin yerel BF16 desteğini kullanan AWS araştırmacıları, BERT 1,5 milyar modeli etkinleştirmek için FP32’ye kıyasla bellek boyutu gereksinimlerini azalttı ve eğitim performansını artırdı. 340 milyon ila 1,5 milyar parametreli bir BERT modeli için DeepSpeed ZeRO aşama 1 optimizasyonlarını kullanarak 128 hızlandırıcıda %82,7’lik bir ölçeklendirme verimliliği elde ettiler.
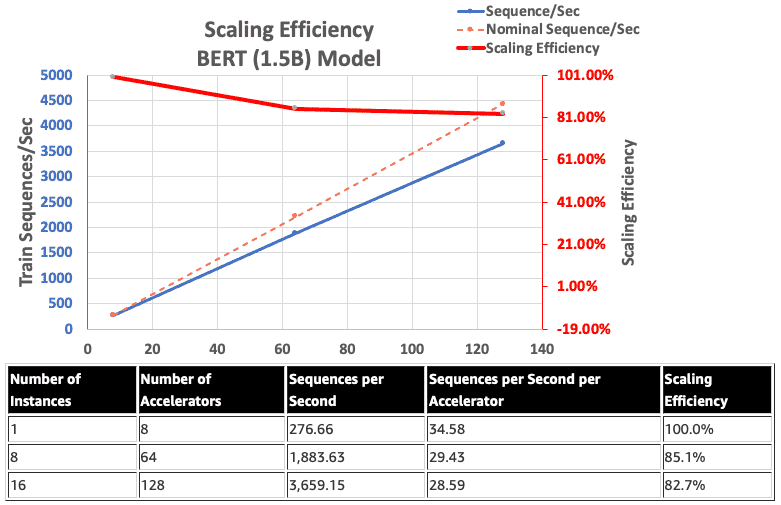
Genel olarak, AWS araştırmacıları, DeepSpeed ve birden fazla Habana Gaudi hızlandırıcı ile uygun Habana SynapseAI v1.5/v1.6 yazılımı kullanıldığında, 1,5 milyar parametreye sahip bir BERT modelinin 16 saat içinde önceden eğitilebileceğini ve 128 ağda yakınsama sağlayabileceğini buldu. Gaudi hızlandırıcıları, %85’lik bir ölçeklendirme verimliliğine ulaşıyor. mimarisi şu şekilde değerlendirilebilir: AWS Atölyesi.