
İle tefsir etmek Andreessen Horowitz, üretken yapay zeka, özellikle metinden sanata tarafında, dünyayı yiyor. Bilgi istemlerinden metin ve görüntüler oluşturan yapay zeka geliştiren yeni girişimlere akıttıkları milyarlarca dolara bakılırsa, yatırımcılar en azından buna inanıyor.
Geride kalmamak için Big Tech, ister yukarıda belirtilen yeni girişimlerle ortaklıklar yoluyla isterse şirket içi Ar-Ge yoluyla kendi üretken yapay zeka sanat çözümlerine yatırım yapıyor. (Bkz: Microsoft, Görüntü Oluşturucu için OpenAI ile iş birliği yapıyor.) Güçlü Ar-Ge kanadından yararlanan Google, halihazırda mevcut olan platformlarla rekabet edebilmek için üretken yapay zeka alanındaki çalışmalarını ticarileştirerek ikinci rotaya gitmeye karar verdi.
Google, bugün yıllık G/Ç geliştirici konferansında, Imagen adlı metinden resme bir model de dahil olmak üzere, tümüyle yönetilen yapay zeka hizmeti Vertex AI’ye giden yeni yapay zeka modellerini duyurdu. Google’ın geçtiğimiz Kasım ayında AI Test Kitchen uygulaması aracılığıyla önizlemesini yaptığı Imagen, mevcut görüntüler için altyazı yazmanın yanı sıra görüntüler oluşturup düzenleyebilir.
Google Cloud’da Vertex AI direktörü Nenshad Bardoliwalla, TechCrunch’a bir telefon görüşmesinde “Google Cloud kullanan herhangi bir geliştirici bu teknolojiyi kullanabilir” dedi. “Bir veri bilimcisi veya geliştiricisi olmanıza gerek yok.”
Vertex’te görüntü
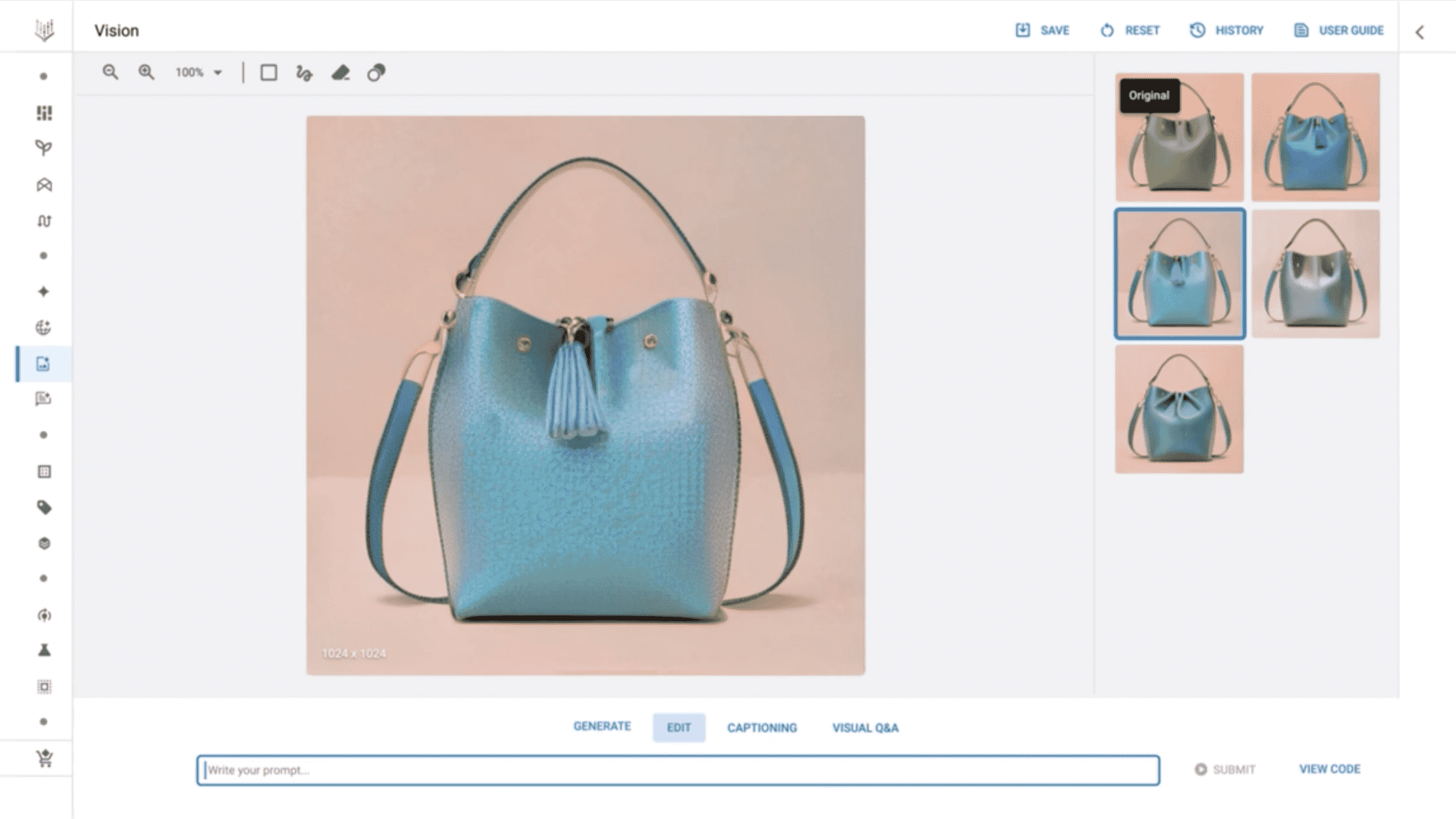
Imagen’i Vertex’te kullanmaya başlamak gerçekten de nispeten basit bir süreçtir. Model için bir kullanıcı arayüzüne, Google’ın Model Bahçesi adını verdiği, Google tarafından geliştirilmiş modellerin yanı sıra seçilmiş açık kaynak modellerden oluşan bir seçkiden erişilebilir. MidJourney ve Nightcafe gibi üretici sanat platformlarına benzer şekilde, kullanıcı arabiriminde müşteriler, Imagen’in bir avuç aday görüntü oluşturmasını sağlamak için istemler (ör. “mor bir el çantası”) girebilir.
Düzenleme araçları ve takip komutları, örneğin içlerinde tasvir edilen nesnelerin rengini ayarlayarak Imagen tarafından oluşturulan görüntüleri iyileştirir. Vertex ayrıca, müşterilerin Imagen’i belirli stillere ve tercihlere yönlendirmesine olanak tanıyan ince ayarın yanı sıra görüntüleri keskinleştirmek için yükseltme sunar.
Daha önce ima edildiği gibi Imagen, isteğe bağlı olarak bu altyazıları Google Çeviri’den yararlanarak çevirerek resimler için altyazılar da oluşturabilir. GDPR gibi gizlilik düzenlemelerine uymak için, oluşturulan ve kaydedilmeyen görüntüler 24 saat içinde silinir, Bardoliwalla diyor.
“İnsanların üretken yapay zeka ve görüntüleri ile çalışmaya başlamalarını çok kolaylaştırıyoruz.” ekledi.
Elbette, kullanıcı arayüzü ne kadar gösterişli olursa olsun, üretken yapay zekanın tüm biçimleriyle ilişkili bir dizi etik ve yasal zorluk var. Imagen gibi yapay zeka modelleri, genellikle genel görüntü barındırma web sitelerini tarayarak bir araya toplanmış veri kümelerinden gelen mevcut görüntüler üzerinde “eğitim” yaparak metin istemlerinden görüntüler oluşturmayı “öğrenir”. Bazı uzmanlar, telif hakkı alınmış olanlar da dahil olmak üzere herkese açık görüntülerin kullanıldığı eğitim modellerinin, adil kullanım doktrini ABD’de Ama bu bir mesele olası olmayan yakında çözülecek.
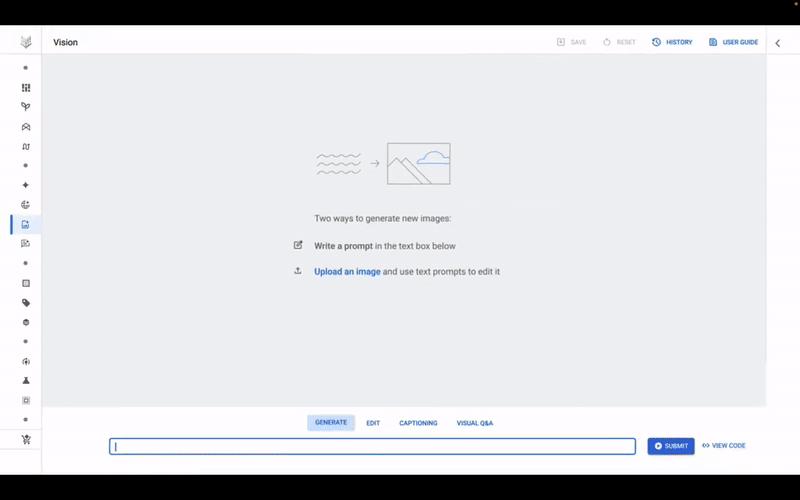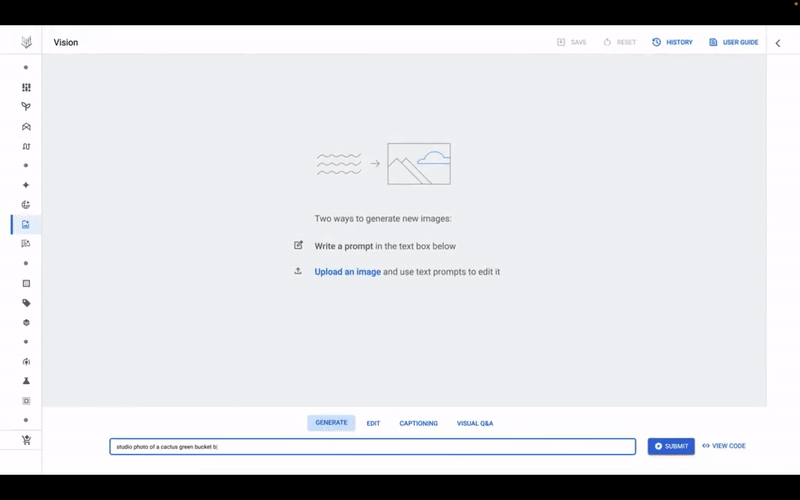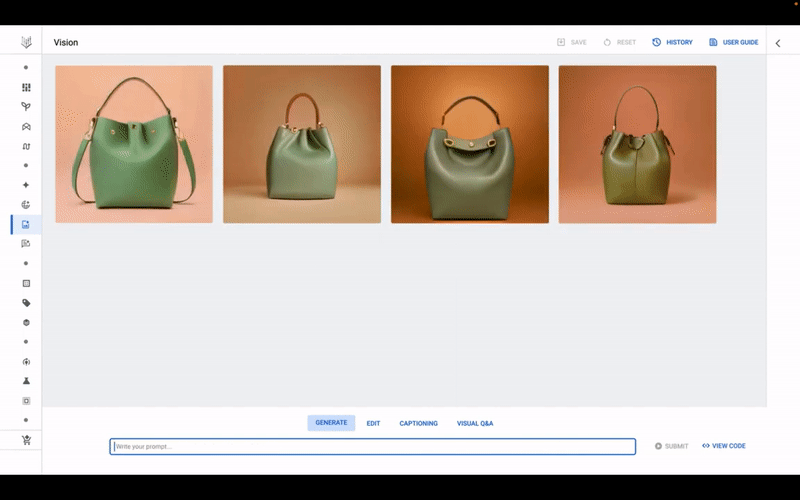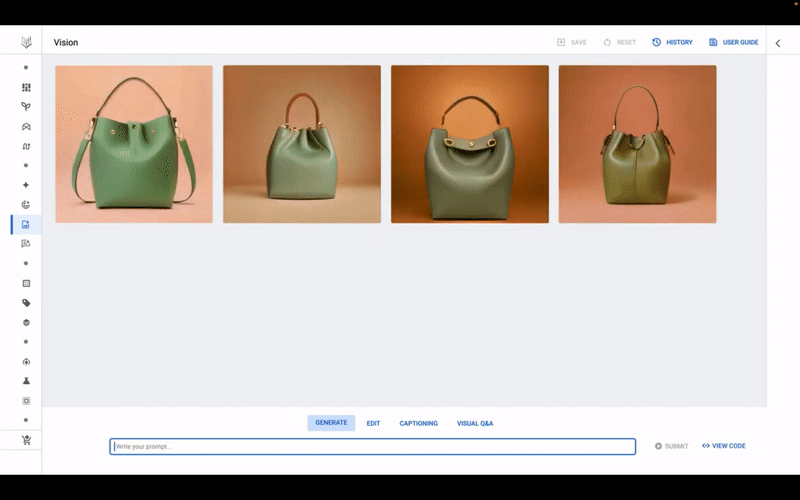
Vertex AI’da Google’ın Imagen modeli iş başında.
Popüler AI sanat araçları Midjourney ve Stability AI’nin arkasındaki iki şirket, bir hedef noktasında. Yasal durum araçlarını web’den kazınmış görüntüler üzerinde eğiterek milyonlarca sanatçının haklarını ihlal ettiklerini iddia ediyor. Stok görüntü sağlayıcısı Getty Images, Stability AI’yi ayrı ayrı mahkemeye verdi. bildirildiğine göre sanat üreten model Stable Diffusion’ı eğitmek için izinsiz olarak sitesinden milyonlarca görüntü kullanmak.
Diye sordum Bardoliwalla, Vertex müşterilerinin Imagen’in telif hakkıyla korunan materyaller konusunda eğitim almış olabileceği konusunda endişelenmeleri gerekip gerekmediği. Anlaşılır bir şekilde, durum buysa, onu kullanmaktan caydırılabilirler.
Bardoliwalla, Imagen’in ticari markalı resimler konusunda eğitim almadığını açıkça söylemedi – yalnızca Google’ın, “telif hakkı iddialarından arınmış” olduklarından emin olmak için modellerinin içindeki “kaynak verilere bakmak” için geniş “veri yönetimi incelemeleri” yürüttüğünü söyledi. (Korumalı dil, büyük bir sürpriz olarak gelmiyor orijinal görüntü halka açık bir veri seti üzerinde eğitildi, LAYONtelif hakkıyla korunan eserler içerdiği bilinmektedir.)
“Telif hakkı bilgileriyle ilgili tüm yasalara uyma dengesi içinde olduğumuzdan emin olmalıyız.” Bardoliwalla devam etti. “Müşterilere işlerinde kullanabileceklerinden emin olabilecekleri modeller sağladığımız ve eğitimli modellerinden oluşturulan IP’ye tamamen güvenli bir şekilde sahip oldukları konusunda çok netiz.”
IP’ye sahip olmak başka bir konudur. En azından ABD’de bu net değil Yapay zeka tarafından oluşturulan sanatın telif hakkına tabi olup olmadığı.
Tek başına mülkiyet sorununa değil, telif hakkıyla korunan eğitim verileriyle ilgili sorulara yönelik bir çözüm, sanatçıların yapay zeka eğitimini tamamen “devre dışı bırakmasına” izin vermektir. Yapay zeka girişimi Spawning, üretken yapay zeka teknolojisini devre dışı bırakmak için sektör çapında standartlar ve araçlar oluşturmaya çalışıyor. Adobe, kendi devre dışı bırakma mekanizmalarını ve araçlarını takip ediyor. Kasım ayında yazılım robotlarının resimler için sayfaları taramasını yasaklamak için HTML etiketi tabanlı bir koruma başlatan DeviantArt da öyle.
Görsel Kaynakları: Google
Google, devre dışı bırakma seçeneği sunmaz. (Adil olmak gerekirse, baş rakiplerinden biri olan OpenAI de öyle.) Bardoliwalla bunun gelecekte değişip değişmeyeceğini söylemedi, sadece Google’ın “modelleri “etik ve sorumlu” bir şekilde eğittiğinden emin olmakla “aşırı derecede ilgileniyor”.
Bu biraz zengin, sanırım, bir şirketten geliyor iptal edildi Dışarıdan bir AI etik kurulu, önde gelen AI etik araştırmacılarını görevden almaya zorladı ve kısıtlama “Rekabet etmek ve bilgiyi şirket içinde tutmak” için yapay zeka araştırması yayınlamak. Ama yorumla Bardoliwalla’nın sözlerini istediğiniz gibi.
ben de sordum bardoliwalla Google’ın, eğer varsa, Imagen’in oluşturduğu zehirli veya önyargılı içerik miktarını sınırlamak için attığı adımlar hakkında – üretken yapay zeka sistemleriyle ilgili başka bir sorun. Kısa bir süre önce, AI girişimi Hugging Face ve Leipzig Üniversitesi’ndeki araştırmacılar bir alet Stable Diffusion ve OpenAI’nin DALL-E 2’si gibi modellerin, özellikle yetkili konumlardaki insanları tasvir etmeleri istendiğinde, beyaz ve erkek gibi görünen insan resimleri üretme eğiliminde olduğunu gösteriyor.
Bardoliwalla, Vertex tarafından barındırılan üretken modellere yapılan her API çağrısının toksisite, şiddet ve müstehcenlik dahil olmak üzere “güvenlik özellikleri” açısından değerlendirildiğini iddia ederek bu soru için daha ayrıntılı bir yanıt hazırladı. Bardoliwalla, Vertex’in modelleri bu niteliklere göre puanladığını ve belirli kategoriler için yanıtı engellediğini veya müşterilere nasıl devam edecekleri konusunda seçenek sunduğunu söyledi.
“Tüketici özelliklerimizden, müşterilerimizin üretmek için bu üretken yapay zeka modellerini aradığı türde içerik olmayabilecek içerik türleri hakkında çok iyi bir sezgiye sahibiz.” o devam etti. “Bu müşterilerimizin aradıkları ve marka değerlerine zarar vermeyen sonuçları üretebilmelerini sağlamamız için Google için önemli bir yatırım ve pazar liderliği alanıdır.”
Bu amaçla Google, Vertex’te yönetilen bir hizmet teklifi olarak, kuruluşların model performansını zaman içinde sürdürmesine ve üretimde daha güvenli ve ölçülebilir şekilde daha doğru modeller kullanmasına yardımcı olacağını iddia ettiği, insan geri bildiriminden güçlendirilmiş öğrenimi (RLHF) başlatıyor. Makine öğreniminde popüler bir teknik olan RLHF, sözleşmeli çalışanlardan bir yapay zeka sohbet robotundan gelen yanıtları derecelendirmelerini istemek gibi doğrudan insan geri bildirimlerinden bir “ödül modeli” eğitiyor. Daha sonra, Imagen’in çizgileri boyunca üretken bir yapay zeka modelini optimize etmek için bu ödül modelini kullanır.
Görsel Kaynakları: Google
Bardoliwalla, ihtiyaç duyulan ince ayar miktarının RLHF, müşterinin çözmeye çalıştığı sorunun kapsamına bağlı olacaktır. RLHF’nin her zaman doğru yaklaşım olup olmadığı konusunda akademi içinde tartışmalar var – AI girişimi Anthropic, bunun kısmen olmadığını, çünkü RLHF’nin düşük ücretli müteahhitlerin işe alınmasını gerektirebileceğini savunuyor. zoraki son derece toksik içeriği derecelendirmek için. Ancak Google farklı hissediyor.
“RLHF hizmetimizle, bir müşteri bir modalite ve model seçebilir ve ardından modelden gelen yanıtları derecelendirebilir.” Bardoliwalla dedi. “Onlar bir kez Bu yanıtları takviyeli öğrenme hizmetine gönderdiğinizde, modeli bir kuruluşun aradığı şeyle uyumlu daha iyi yanıtlar üretecek şekilde ayarlar.”
Yeni modeller ve araçlar
Google bugün duyurdu: Codey ve Chirp.
Google’ın GitHub’ın Yardımcı Pilotuna yanıtı olan Codey, Go, Java, Javascript, Python ve Typescript dahil olmak üzere 20’den fazla dilde kod üretebilir. Codey, bir bilgi istemine girilen kodun bağlamına dayalı olarak sonraki birkaç satırı önerebilir veya OpenAI’nin ChatGPT’si gibi, model hata ayıklama, dokümantasyon ve üst düzey kodlama kavramları hakkındaki soruları yanıtlayabilir.

Görsel Kaynakları: Google
Chirp’e gelince, 100’den fazla dili destekleyen ve videolara alt yazı yazmak, sesli yardım sunmak ve genellikle bir dizi konuşma görevini ve uygulamasını desteklemek için kullanılabilen, “milyonlarca” saatlik ses eğitimi almış bir konuşma modelidir.
Google, I/O’daki ilgili bir duyuruda, metin ve resim verilerini belirli anlamsal ilişkileri eşleyen vektörler adı verilen temsillere dönüştürebilen Vertex için Gömme API’sini önizlemede başlattı. Google, bir kuruluşun verilerine, duyarlılık analizine ve anormallik tespitine dayalı Soru-Cevap sohbet botları gibi anlamsal arama ve metin sınıflandırma işlevleri oluşturmak için kullanılacağını söylüyor.
Google, Codey, Imagen, resimler için Gömme API’si ve RLHF’nin Vertex AI’da “güvenilir test kullanıcıları” tarafından kullanılabileceğini söylüyor. Bu arada, Gömme API’si olan Chirp ve yapay zeka modelleriyle etkileşim kurmak ve bunları dağıtmak için bir paket olan Generative AI Studio’ya, Google Cloud hesabı olan herkes Vertex’te önizlemede erişebilir.
