
Nvidia, H100 hesaplama GPU’su için bazı yeni performans sayıları yayınladı. MLPerf 3.0, derin öğrenme iş yükleri için önemli bir kıyaslamanın en son sürümü. Hopper H100 işlemci, eğitim süresi ölçümlerinde yalnızca önceki model A100’ü geride bırakmakla kalmıyor, aynı zamanda yazılım optimizasyonları sayesinde performans kazanıyor. Ayrıca Nvidia, kompakt L4 kompakt bilgi işlem GPU’sunun selefi T4 GPU ile erken performans karşılaştırmalarını da açıkladı.
Nvidia ilk olarak H100 testinde elde ettiği sonuçları yayınladı. MLPerf 2.1 karşılaştırması Eylül 2022’de, amiral gemisi bilgi işlem GPU’sunun çeşitli çıkarım iş yüklerinde selefi A100’ü 4,3-4,4 kata kadar yenebileceğini ortaya çıkardı. MLPerf 3.0’da elde edilen yeni yayınlanan performans rakamları, Nvidia’nın H100’ünün A100’den daha hızlı olduğunu (sürpriz değil) doğrulamakla kalmıyor, aynı zamanda Intel’in yakın zamanda piyasaya sürdüğü Xeon Platinum 8480+ (Sapphire Rapids) işlemcisinden ve NeuChips’ten de somut bir şekilde daha hızlı olduğunu yeniden teyit ediyor. Bir dizi iş yükünde ReccAccel N3000 ve Qualcomm’un Cloud AI 100 çözümleri
Bu iş yükleri arasında görüntü sınıflandırma (ResNet 50 v1.5), doğal dil işleme (BERT Large), konuşma tanıma (RNN-T), tıbbi görüntüleme (3D U-Net), nesne algılama (RetinaNet) ve öneri (DLRM) yer alır. Nvidia, yalnızca GPU’larının daha hızlı olduğunu değil, aynı zamanda makine öğrenimi endüstrisinde daha iyi desteğe sahip olduklarını belirtiyor – bazı iş yükleri rakip çözümlerde başarısız oldu.
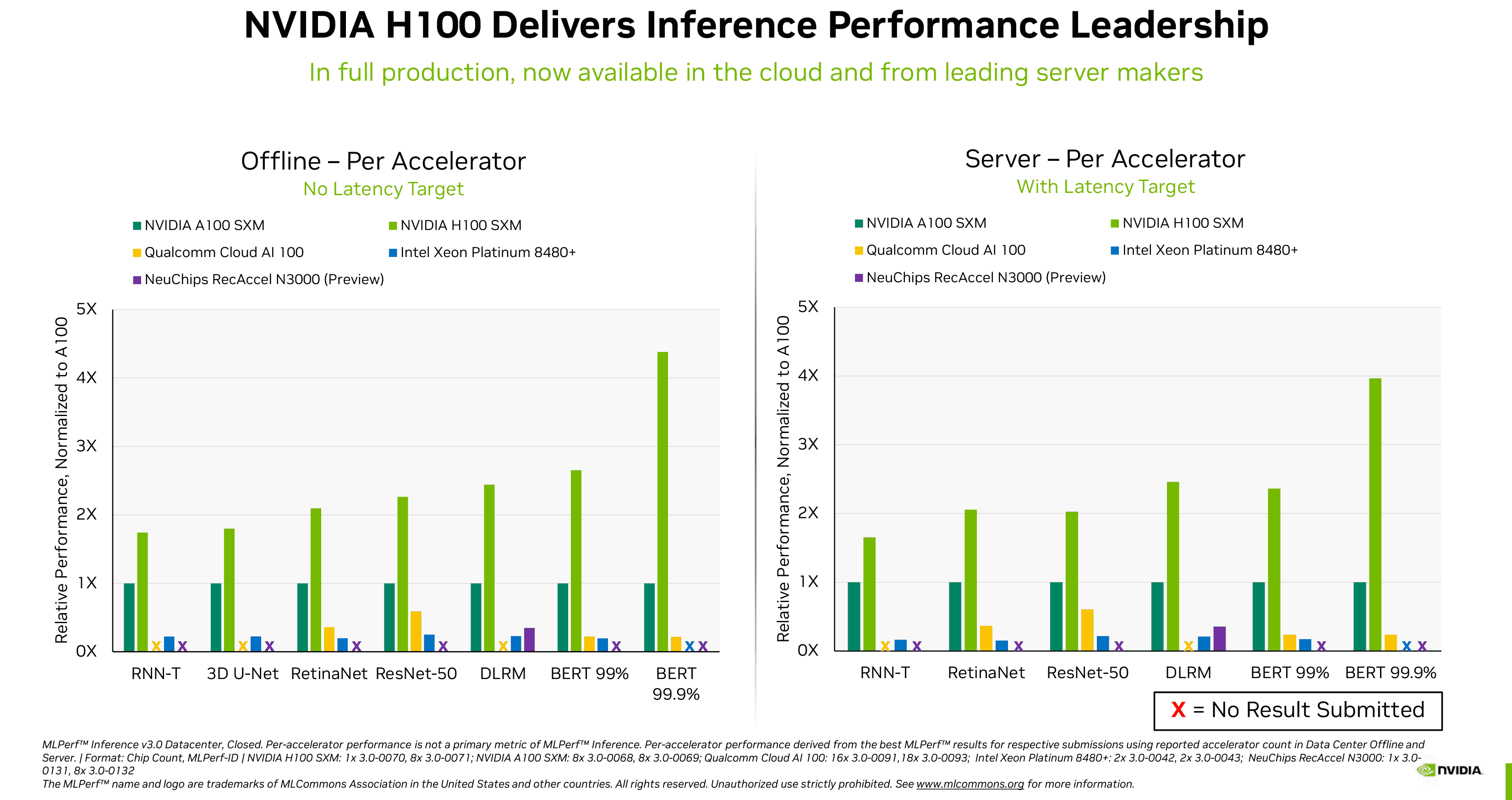
Yine de Nvidia tarafından yayınlanan rakamlarda bir sorun var. Satıcılar, MLPerf sonuçlarını iki kategoride gönderme seçeneğine sahiptir: kapalı ve açık. Kapalı kategoride, tüm satıcıların matematiksel olarak eşdeğer sinir ağları çalıştırması gerekirken, açık kategoride, donanımlarının performansını optimize etmek için ağları değiştirebilirler. Nvidia’nın rakamları yalnızca kapalı kategoriyi yansıtmaktadır, bu nedenle Intel veya diğer satıcıların donanımlarının performansını optimize etmek için uygulayabilecekleri optimizasyonlar bu grup sonuçlarına yansıtılmaz.
Nvidia’nın kendi örneğinin de gösterdiği gibi, yazılım optimizasyonları modern yapay zeka donanımına büyük faydalar sağlayabilir. Şirketin H100’ü, MLPerf 3.0’a karşı MLPerf 2.1’de öneri iş yüklerinde %7’den nesne algılama iş yüklerinde %54’e yükseldi, ki bu oldukça büyük bir performans artışıdır.

Nvidia’da Yapay Zeka, Kıyaslama ve Bulut Direktörü Dave Salvator, ChatGPT ve benzeri hizmetlerin patlamasına atıfta bulunarak bir blog gönderisinde şunları yazıyor: “Yapay zekanın bu iPhone anında, çıkarım performansı hayati önem taşıyor… Derin öğrenme artık neredeyse her yerde konuşlandırıldı ve fabrika zeminlerinden çevrimiçi öneri sistemlerine kadar doymak bilmez bir çıkarım performansı ihtiyacına yol açtı.”
Şirket, H100’ün MLPerf 3.0’da çıkarım performansının kralı olduğunu yeniden teyit etmenin yanı sıra, yakın zamanda piyasaya sürülen AD104 tabanlı L4 hesaplama GPU’su (yeni sekmede açılır). Ada Lovelace destekli bu bilgi işlem GPU kartı, herhangi bir sunucuya sığması için tek yuvalı, düşük profilli bir form faktörü içinde gelir, ancak oldukça müthiş bir performans sunar: genel bilgi işlem için 30,3’e kadar FP32 TFLOPS ve 485’e kadar FP8 TFLOPS (seyreklik ile) ).
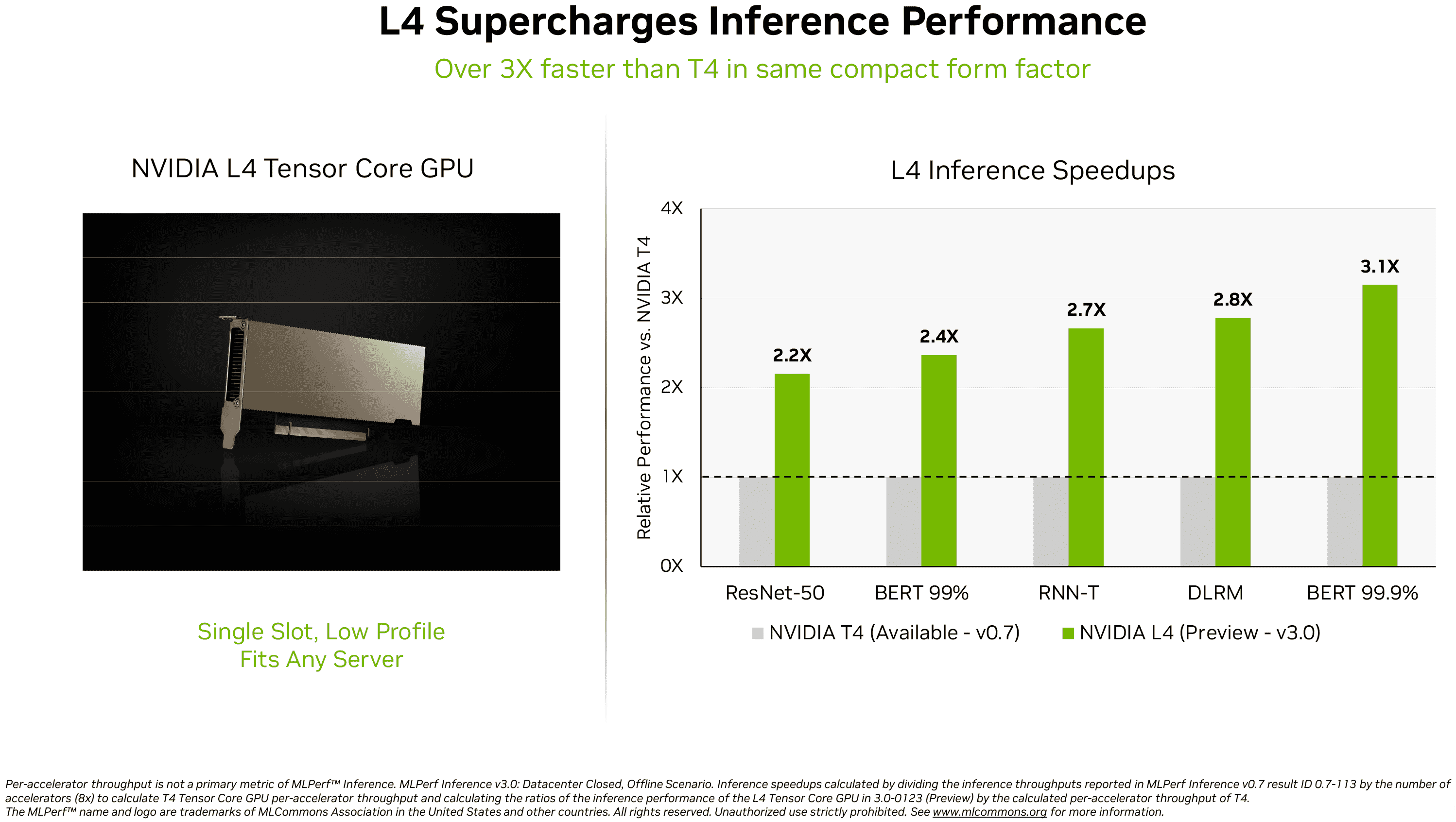
Nvidia, L4’ünü yalnızca diğer kompakt veri merkezi GPU’larından biri olan T4 ile karşılaştırdı. İkincisi, 2018 Turing mimarisine sahip TU104 GPU’yu temel alır, bu nedenle iş yüküne bağlı olarak yeni GPU’nun MLPerf 3.0’daki öncekinden 2,2–3,1 kat daha hızlı olması şaşırtıcı değildir.
Salvator, “Yıldız yapay zeka performansına ek olarak, L4 GPU’lar 10 kata kadar daha hızlı görüntü kodu çözme, 3,2 kata kadar daha hızlı video işleme ve 4 kattan fazla daha hızlı grafik ve gerçek zamanlı işleme performansı sunuyor” diye yazdı.
Halihazırda büyük sistem üreticileri ve bulut hizmeti sağlayıcıları tarafından sunulan Nvidia’nın H100 ve L4 bilgi işlem GPU’larının kıyaslama sonuçları şüphesiz etkileyici görünüyor. Yine de, bağımsız testler yerine Nvidia’nın kendisi tarafından yayınlanan kıyaslama sayılarıyla uğraştığımızı unutmayın.